Am using "List file" to get, well, a list of files from a directory in a table.
With help of "Regex Split" I was able to extract the path into a separate column, pattern (windows):
(.*)\\.*$
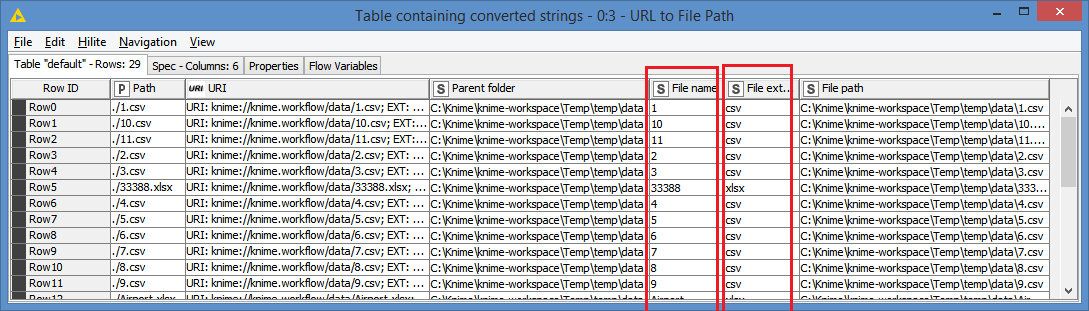
see attached picture for the output.
What I can't get to work is extracting the file names (into a separate column). Any suggestions? Regex Split, Java snippet, whatever works is fine by me.
I often run these two nodes (“List FIles”->“URL to File Path”) to get a list of filenames in a folder. However, “URL to File Path” is SLOW when using cloud drive because it verifies that each file exists before breaking the URL down in its Path components. Since I just ran the List files node, I already know that the files exist and I don’t need to spend the extra 5-10 min waiting for “URL to File Path” to re-check everything. Does anyone know of an equivalent for “URL to File Path” that doesn’t perform the extra checking step?
Note: I am aware that I could use Regex split to manually decompose the URL, however I need a solution that is independent of the system (e.g. Windows, linux), so harcoding in specific path syntax (e.g. “” vs. “/”) isn’t what I’m looking for.
Thanks for the suggestion. I put a cache node between the “List Files” and “URL to File Path” and noticed no difference in behavior. I think this is because the “URL to File Path” will still perform file system calls to confirm each file exists regardless of whether the input table is cached.
The only solution I found (but chose not to implement) was to roll my own RegEx Cell Split in order to manually parse the URLs into file paths and file names. The challenge here is that this is a platform specific task and I need my workflows to run across platforms, so a lot of extra logic based on reflection is required – likely making a very brittle end product.
considering platform issues there is Extract System Properties node which gives you platform information and based on it you can apply right logic using Case of If nodes. Shouldn’t be too complicated.
Considering the speed of URL to File Path node I will check it and get back to you.
Thanks ipazin. The slowness of URL to Pile Path comes into play under the following scenario:
You read a list of 2000 file URLs from a remote server (e.g. cloud drive or FTP); then you need to extract the file name, the parent directory name, file extension, etc… The URL to File Path does a great, cross-platform-compatible job with this. However, this node has the side-effect of going through each of those 2000 entries and first verifying that the file exists.This is a one-at-a-time loop and can take 10 minutes depending on the connection speed. This is 100% wasted time since we already know that the files exists because we just obtained the URLs from the List Files node.
Thus having a version of URL-to-FilePath where you could turn off the “verify file exists” part of the functionality would be very useful. Your suggestion that we can re-implement this node from scratch is appealing as it would save hours of time over the course of a week, but I don’t know how to do this so it will work across all platforms (Mac, linux, & windows). An example workflow would be helpful!
I see. Seems this node indeed performs one IO call per row. I will report it and then maybe something can be improved in future releases.
I didn’t mean to re-implement this node from scratch. What I had in mind is to perform Regex Split based on Platform information. Here is workflow example for you to check out: https://kni.me/w/L0yXIdSKUMQREVbk
If you can apply right logic based on platform in Regex Split node this should do the trick. And should be faster
If it can work on all three platforms then great! I have never really worked on Mac or Linux so not familiar with paths and thus can’t verify it covers all three platforms…
This looks like a nice, flexible bit of RegEx. If it can really handle all OS cases, then that would be great! I will try this one and ipazin’s solution and see what works best.
With the new file handling framework you can also use the new path expressions in the Column Expressions node to work with file paths. To get the file name simply use the getFileName() expression as shown in this example workflow:
Hi @tobias.koetter , thanks for sharing, it’s good to know these functions.
Alternatively, you can also get the filename using the URL to File Path node. Of course, we’d need to convert the Path to URI first using the Path to URI node: