Hi,
if a List Files/Folders node is configured to check a directory and search within that for a specific file, it usually should return a no result but occasionally errors out:
2024-09-19 17:58:30,633 ERROR List Files/Folders 3:1171:0:1140:0:1155 Execute failed: /chunk-parallel-0.pause
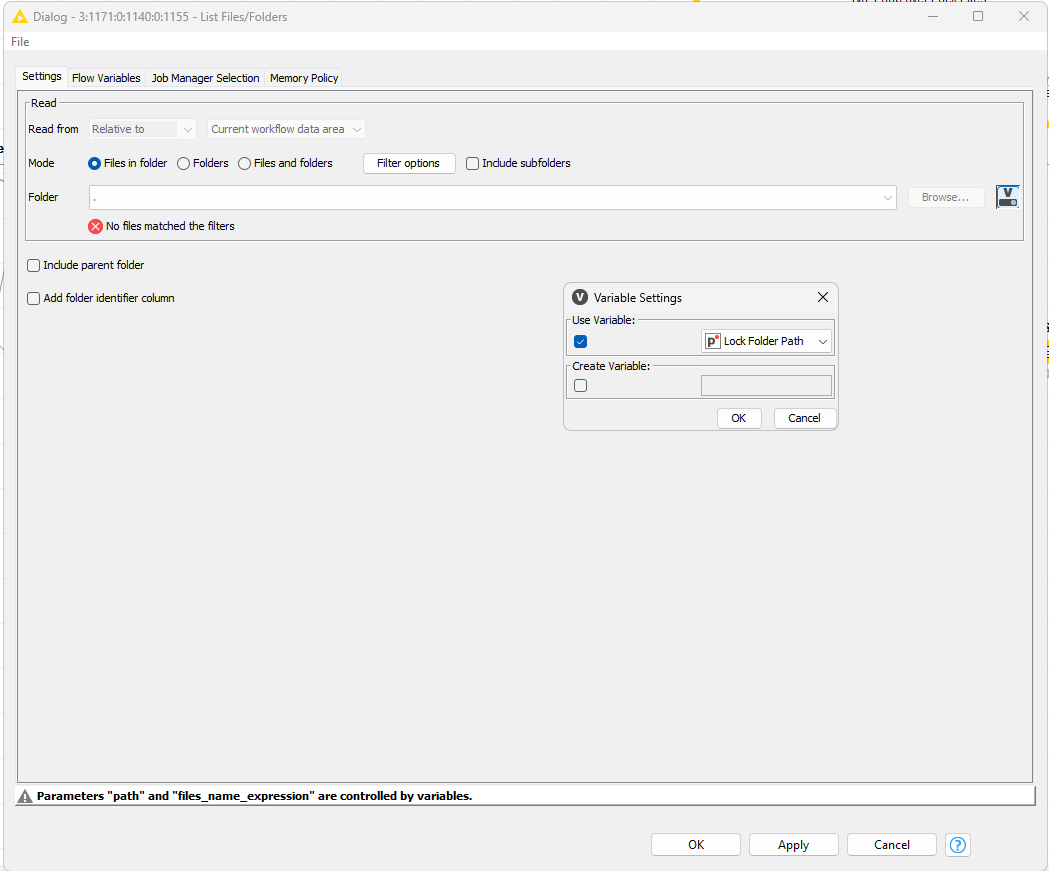
Folder Path managed via Variable
File name managed via variable
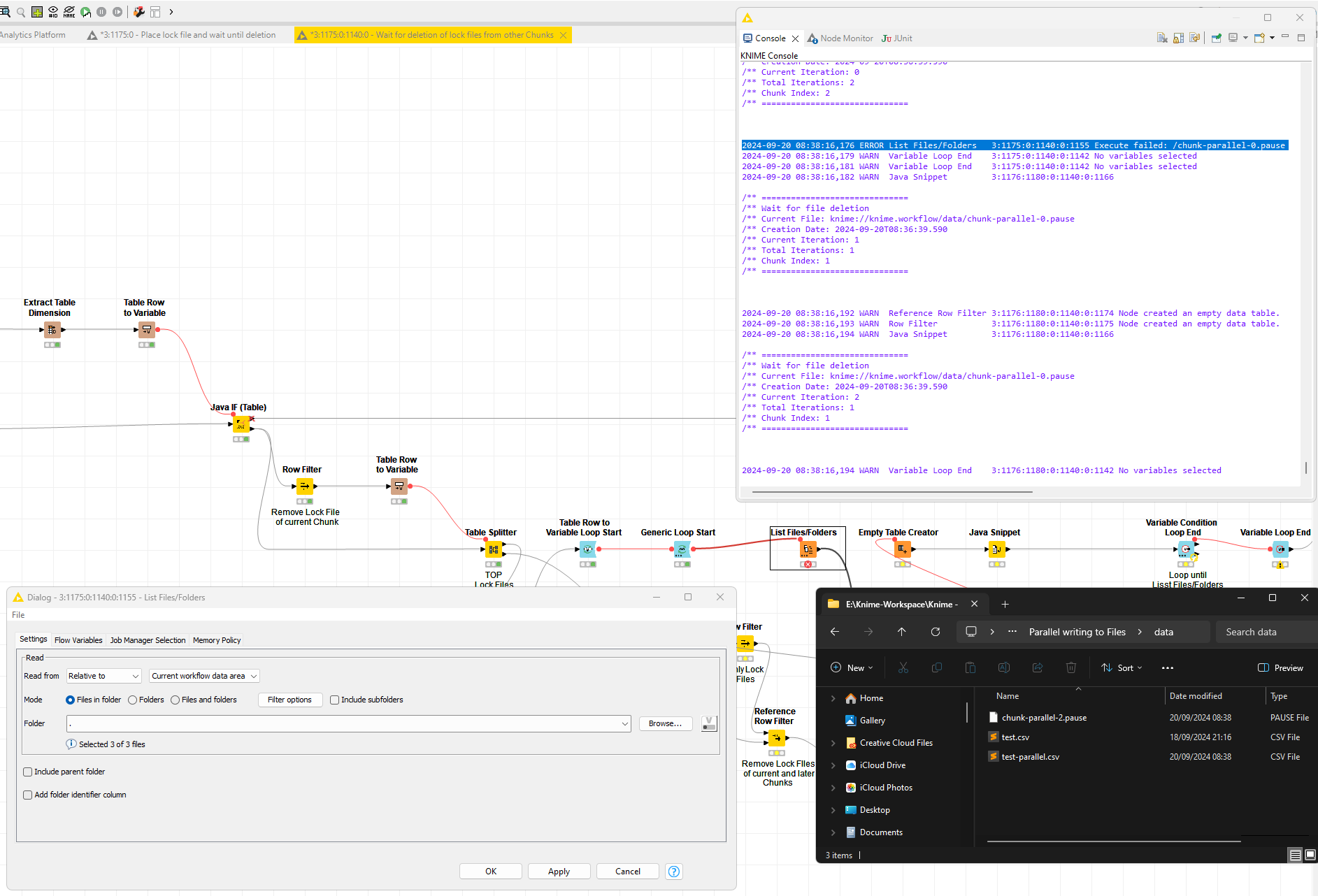
This is triggered during parallel execution. Here is the test workflow:
PS: The List Files/Folders node also fails if no filter option was enabled. It seems to be related to using a variable to determine the folder to check or manage any filter. Upon I removed the variables, the node did not failed anymore.
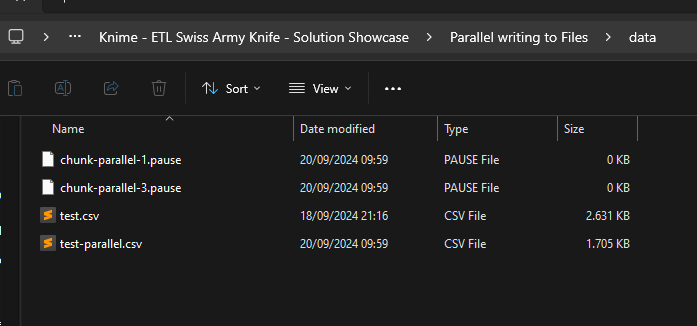
PPS: No, it seems fundamentally broken / unreliable … there are files in the workflow data folder. No variable is used. When I manually re-execute the node w/o any change being made, it works.
Here is the thread dump:
240920 Knime threaddump topic 83377 list files folders fails.tdump.txt (83.3 KB)
Best
Mike
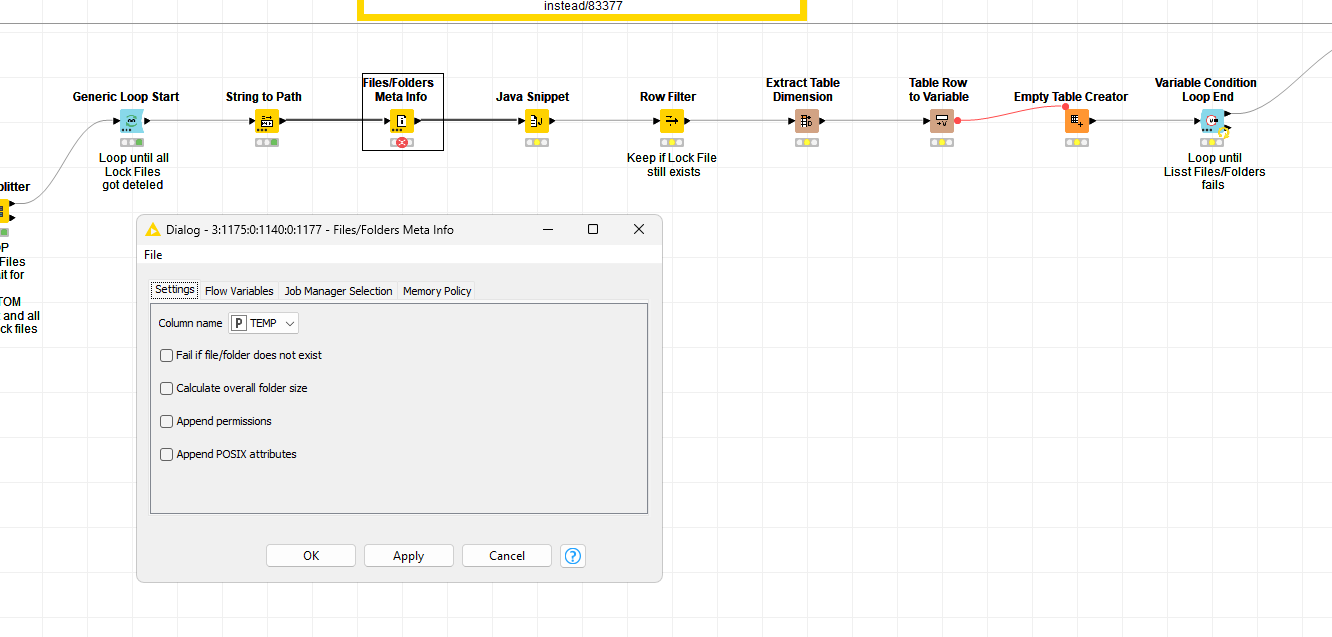
It seems there is a more fundamental issue. I reworked the integration to use the Files/Folders Meta Info node but it also fails occasionally even though it is specifically configure to NOT fail.
2024-09-20 09:59:22,466 ERROR Files/Folders Meta Info 3:1176:1180:0:1140:0:1177 Execute failed: The file/folder '/chunk-parallel-0.pause' does not exist
Here is the thread dump:
240920 Knime threaddump topic 83377 files folders meta info fails.tdump.txt (86.9 KB)
Re-executing the node without making any change work, though.
@mwiegand I have a hard time understanding what you are doing and what the problem is. Is it possible to boil that down to a phenomenon that would occur when you reset the whole thing and start fresh and do not try to delete some files in parallel executions that might then not be there (or something).
My recommendation would be to design even KNIME workflows to have some space for error (maybe wait nodes or unique file names) since one never exactly knows what might go on on a system and if maybe a write operation might be to fast.
Indeed in an ideal world a program would handle all that automatically. I currently cannot decide if this is a ‘major’ bug/flaw or a fringe case that can easily be avoided by some measures.
Hi @mlauber71,
I am working on an example / educational workflow that shows how to process data in parallel but allows to write results into the same file. The overarching scenario is to scrape an entire website. Though, sometimes not all URLs are know nor present in the XML-sitemap. So, during the scrape, newly identified URLs are added to the stack. To prevent parallel chunks scraping the same URL multiple times, it is necessary to use a shared URL-file.
Anyhow, the issue is that regardless of the node I use, they all share the same bug. They fail even though they should not. That is especially true for the Files/Folders Meta Info node which has the option to fail if the file does not exist disabled.
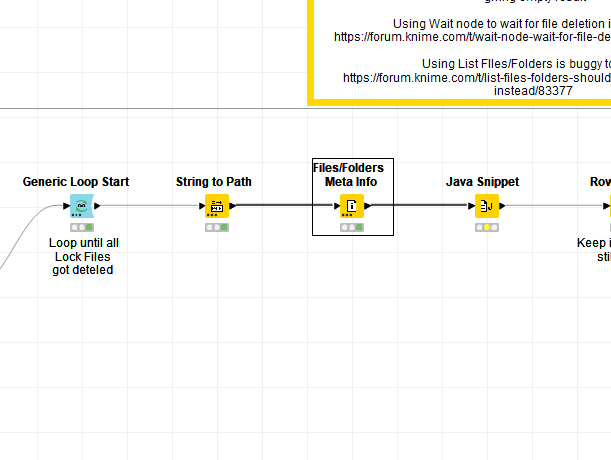
I overcame this issue by using “brute force” … a try-catch wrapped inside a Generic Loop Start and Variable Condition Loop End node.