Hi @dvkumaraws2019 , you can achieve this without any code required, using existing nodes.
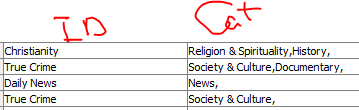
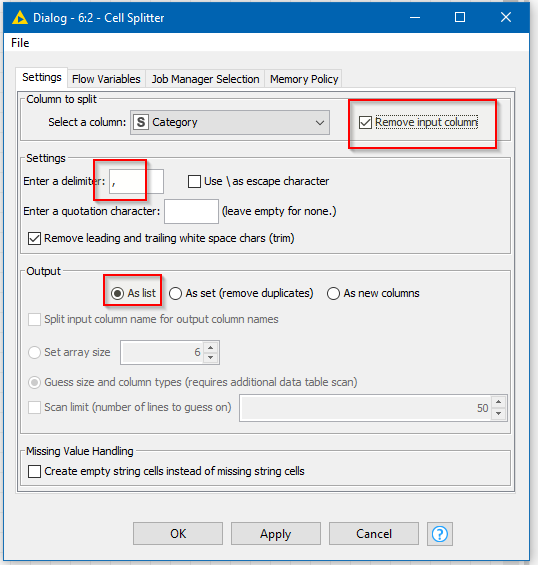
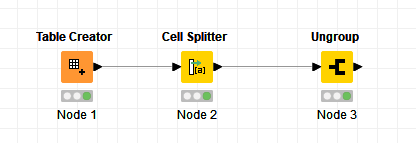
The Cell Splitter node can split the Category using “,” as the delimiter. The trick is to tell it to split into a “List” rather than columns
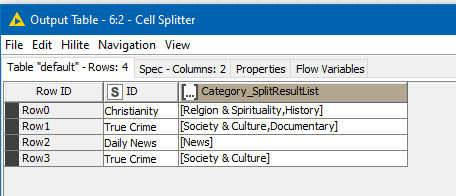
This causes it to turn the cell into a String List with each of your categories as elements.
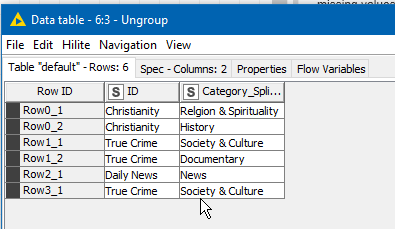
The “magic” happens by using this in conjunction with the “Ungroup” node, which expands your list across new rows, but in doing so “fills down” any other columns that are not being “ungrouped”
(Edit: In your sample data, you had duplicates which of course show here, so you could remove those with a Duplicate Row Filter if required, oh and you’ll want to probably add a Column Rename on the end, which I forgot ! )
 )
)