Hello!
I am a student and new to this programme.
Could you help me how to make a list of frequent value in a dataset?
I would be very grateful for your kind help! Have a nice day!
Regards,
NA
Hello!
I am a student and new to this programme.
Could you help me how to make a list of frequent value in a dataset?
I would be very grateful for your kind help! Have a nice day!
Regards,
NA
Hello @nada98,
can you tell me something more about the data or maybe can you upload some? Depending on the type we can decide how to proceed.
Thank you,
RB
Hello RB!
Thank you for your reply! Really appreciate it!
So I have an example dataset about airline delays. I would like to filter or make a listing from it to identify which airline or airport has the most frequent delayed flight.
Once again, thank you!
Regards,
NA
I assume 1 row to be 1 flight. Correct?
I’d proceed in this way:
This is just for computing absolute values. Do you need a relative view too? (Ex: Easyjet: 70% on time, 30% delayed).
RB
Hello RB,
thank you again for your kind reply and help!!
What is the relative view, If I may ask?
Thank you!!
Regards,
NA
No worries ![]()
Take this example:
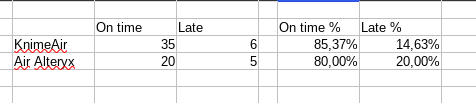
If you want to work on absolute vaues, Knime Air has been late on 6 flights.
With relative numbers, Air Alteryx is worse, since it has a 20% rate of lateness.
What you consider “worse” depends on what you want to take into account.
So my question is: do you need to consider just absolute values or you need percentages as well?
Have a nice weekend,
RB
Dear RB,
Thank you so much for your kind help!
I really appreciate it! :))
Wish you have a nice day!
Regards,
NA
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.