What you could try is using a chat instead of an instruct model and see if this helps though I doubt it.
From my perspective knime needs to come up with a system to keep up with the fast development of llms. It will not be acceptable to wait for weeks or even month to use these models.
Thank you very much. It seems like the issue with the nodes we are experiencing due to updates of the LLMs is a common challenge. I’ve encountered similar problems with OpenAI, particularly with new methods required to call the models using Python. Regarding maintaining consistency in how functions are called, one can still use the old version of the API connectors for the GPT models, which might allow us to keep calling the models in the same way for a bit longer. However, as new methodologies develop, one inevitably needs to implement these changes, which can be quite challenging.
I’m also concerned about whether KNIME will be able to adapt to these changes, as they significantly alter the programming needed to interact with the model through the API. It’s not just a matter of renaming functions; it requires a complete restructuring of how one calls the API and handles the responses. As you said, this is likely a theme that KNIME will need to address in the future. Let’s see what happens.
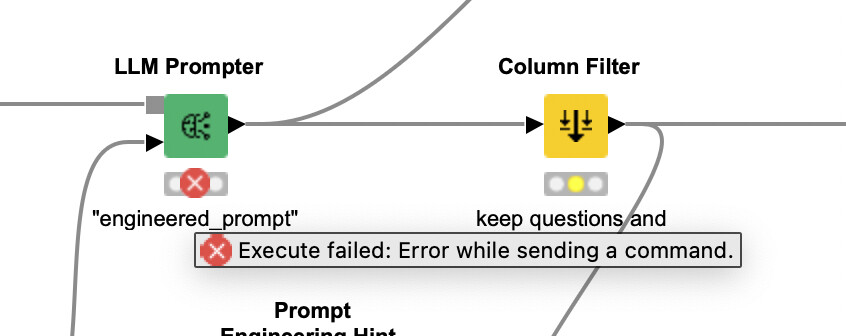
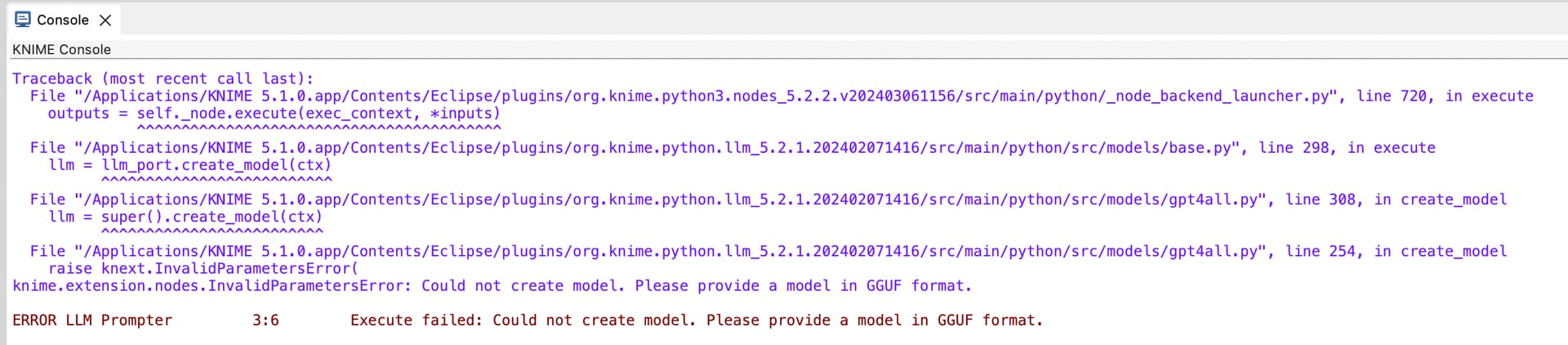
I’ve been troubleshooting an issue where the .gguf file of the Llama3 model (Meta-Llama-3-8B-Instruct.Q4_0) appears encrypted, leading to compatibility issues with the LLM Prompter. In contrast, the Mistral model’s .gguf file works seamlessly and it is not encrypted. Has anyone else experienced similar issues with the Llama3 model or other .gguf files?
It’s curious that as the Llama model improves, access to it seems to become encrypted. Do you think now Meta would use the same strategy as OpenAI did, like once the model become good enough they change from altruistic to profit-centered?