Hi, I’m using knime, in the hadoop world.
After connecting to HDFS I should create a SPARK context, via livy.
The node uses the libraries that are installed on the livy server, specifically the Jetty library.
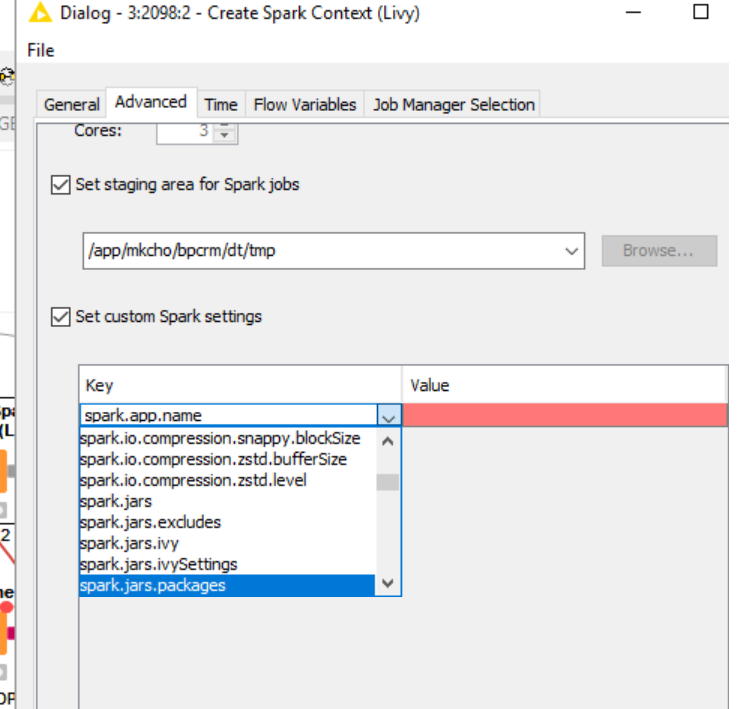
How do I load this library from the client side? can I load it from these settings from here?
You can add custom jars, using settings like the one in your screenshot. Please node that the Spark jobs are running on your cluster. This means the jars must be stored on your servers or e.g. HDFS.
Can you give me an example screenshot? in which I see which parameter to use and how to value the key and value column, and in the example how to set the value column in which the jetty library is located in a specific path.
Hi Sasha,
No, I connected without problems with the livy node, but there was a version change on the Hadoop side, and the jetty-io-9.4.39.v20210325.jar library present in the Cloudera package gives me problems, I would like to use only on livy the updated library jetty-io-9.4.48.v20220622.jar.
I saw that in the livy custom settings, I can indicate how to overwrite a system library with a custom one.
My question is how do you compile the image?
Not sure if this is possible. You can provide additional jars to your Spark Job, but not to the Livy service itself. Do you have trouble with Livy accessing HDFS or Spark accessing HDFS?
Cloudera provides Livy together with the Spark CDS, maybe you can update it to the latest version, and then you don’t have to use special jetty versions?
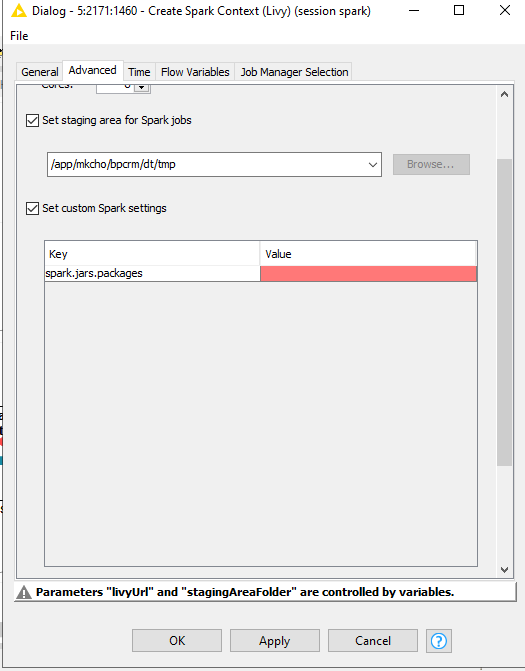
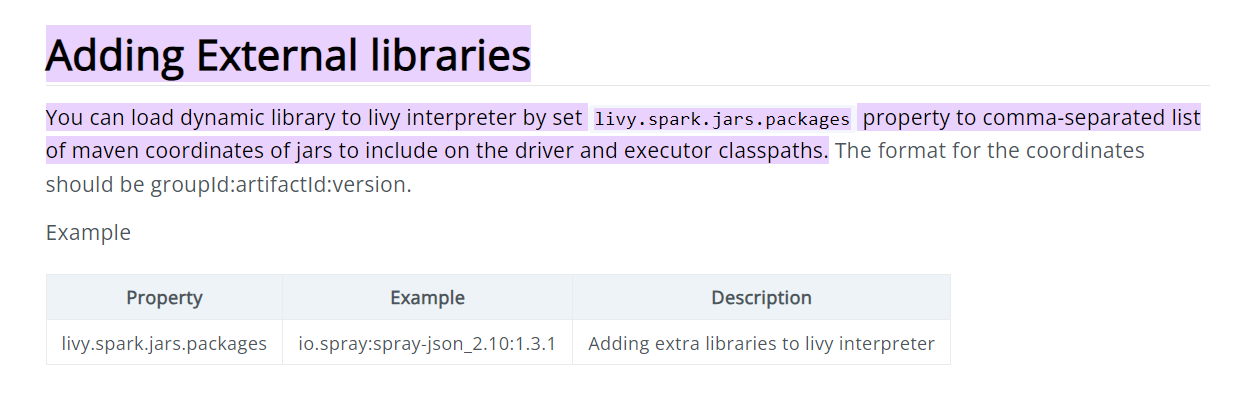
Not sure if this is possible, Netty is an essential lib used already in Livy and you might not able to replace it this way. You can try the spark.jars.packages option in the Livy configuration dialog. You might also be able to do this using the livy.spark.jars.packages on a global level via the Cloudera Manager, and the Livy configuration.