when trying to use Apache workflow executor together with local big data environment, the component does not execute and throws in the following error :
“Could not find required Spark job for Spark version: 3.5. Possible reason: The KNIME Extension for Apache Spark that provides the jobs for your Spark version is not installed.”
This is likely to the fact that the workflow executor only supports spark 3.4, whereas the local big data env node was updated (in 5.3) to use spark 3.5.
“BD-1271: (Big Data Extensions): Update Create Local Big Data Environment to Apache Spark 3.5”
I have tested the issue in KNIME 5.2.6 and the component executes without issues.
Since there is no spark version config available in “Create Local Big Data Environment” node, is using older versions of KNIME the only available workaround?
are there plans to update the workflow executor extension to align the versions?
sorry for the late reply. When we add support to a newer Spark version we update all related components together e.g. Local Big Data and the Spark Extension. Both where updated to support Spark 3.5 with KNIME Analytics Platform 5.5.
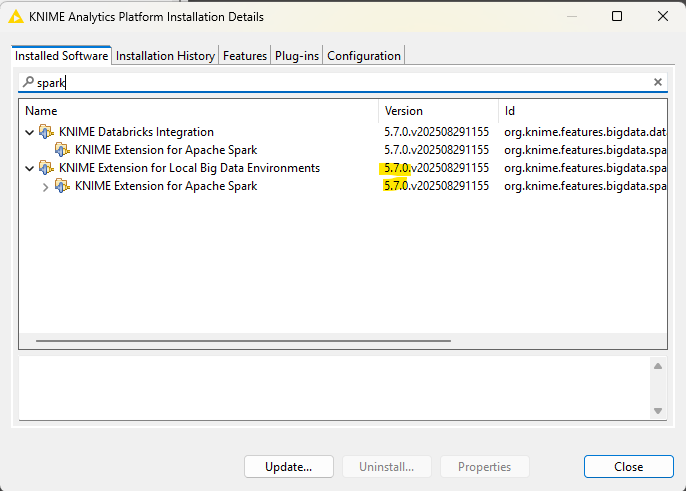
That said, it looks like in your installation the Local Big Data Extension has been updated to >=5.3 but the Spark Extension hasn’t been updated. Can you please check the extension version by clicking in KNIME AP on the Question mark and go to About KNIME Analytics Platform. In the dialog click on the Installation Details button and search in the Installed Software tab for Spark. You should see something similar but with another version e.g. 5.3…
Make sure that the first two numbers (here 5 and 7) are the same for both extensions. If this is not the case try to update KNIME. If this fails uninstall both extensions via the Uninstall button, restart KNIME and re-install the extensions again.
sorry I missed that. That is a bit of a surprising combination for me How did you manage to use the KNIME Workflow Executor for Spark within the Local Big Data Environment and why would you do that? I would be also interested to know why you are using the extension and if there could be an alternative. The reason is that we most likely will no longer maintain the extension because not many people are using it and it is a lot of effort to maintain it.
Hi Tobias! Thanks a mil and sorry to hear this will no longer be maintained- I personally really like this feature.
The main use case here would be quickly refactoring knime-native (meaning no python scripts/db nodes etc) workflows for performance (parallelism + lazy evaluation) on a single machine. I know there are other options e.g. streaming or/and parallel chunk loop , but those are not always the best choice : not all nodes are stremamble , memory usage is very high with parallel chunk loops + each step is always materialized, whereas spark optimizes the queries before execution.
Perhaps adding version config option to the local big data node is a feasible workaround? ( so that a user can fall back to spark 3.4 for compatibility)