I try to find rare combinations of diagnosis and CPT codes. Data set has encounter, Dx, CPT.
By rare combination I would understand the one from the bigger distance from the Dx,CPT combination.
What could be the method to proceed?
Hi @izaychik63 -
Sorry for the late reply. What about just doing a GroupBy on Dx and CPT, and looking at those combinations with a low count?
I don’t have the right domain knowledge, so I probably am not understanding your question correctly. Are you actually instead looking to do some sort of string dissimilarity calculation, e.g. based on Levenshtein distance?
It is not about text to use Levenshtein. The records looks like:
Provider 1, Dx1, CPT12, CPT200, …
Provider 2, Dx1, CPT12,CPT201, …
Provider 3 Dx1, CPT11, CPT305,…
Provider 1 Dx2, CPT115, CPT450,…
Provider 2, Dx2, CPT114, CPT320,…
So, for same Dx I need to find outliers who used the most rare CPT combinations.
Here’s an example workflow. It reads in up to 5 CPT codes - some toy data I made up based roughly on your format - and after some ungrouping/sorting/regrouping, returns an ordered count of CPT combinations, rarest first. It’s clunky, but maybe it will help.
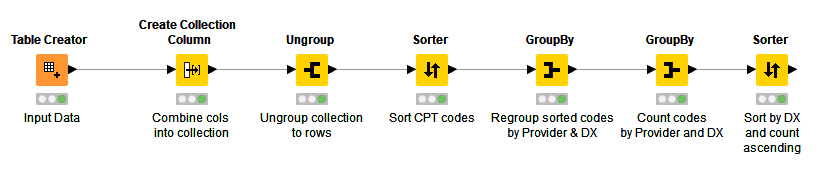
UngroupSortCountExample.knwf (16.4 KB)
Thank you, Scott. I never used set as grouping field.
1 Like