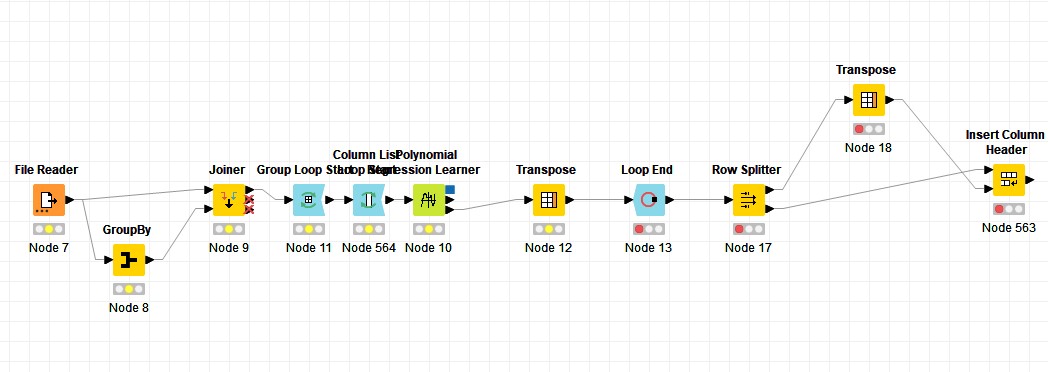
I am working on a complex machine learning workflow that runs a polynomial (quadratic) regression for each unique ID in the UID column and then for each column that starts with Mean(SN_… My dependent variable will always start with “LDO” So it is a double loop, one for each unique row record and then a sub loop for each column given the above rule.
Do make things more fun, I am trying to solve for the maximum of the polynomial regression for each UID for each SN_ column. So if I have 10 UIDs and 5 SN_ columns, I will have a total of 50 quadratic models run, 5 for each UID. So I will need to solve 5 regressions per person within the bounds of the min/max of the SN_ field it is running the regression for, for that UID.
I have coded this in python and trying to do the whole thing in Knime. I am trying to attach the workflow and data but the workflow file is too big so I attached a screenshot sample_data.xls (789.5 KB)
Hi @Shmelky
You can upload the workflow to KNIME Hub, than you can keep working on it and have it linked here. For making workflows smaller reset it before uploading. You can here, under Share and collaborate learn how to upload workflows to hub: About – KNIME Community Hub
One thing I noticed from your workflow, there is another loop end missing.
You need to think of loop like brackets in programming. Every loop needs to have a loop start and loop end node.
I’m not sure I understand your problem, even with the workflow. You said you have something already “alive” in Python, right ? So, could you please share the output data (generated by Python) ? If possible, can you transform your data from “sample_data.xls” to have the “in & the out” data for better understanding of your problem.
Attached is the output from the sample_data.xls. Each UID had a quadratic regression with the optimum value for each of the independent variables. df_peaks_T.xlsx (28.5 KB)
Here is the python code
ids = df.UID.unique()
x_fields = [col for col in df if col.startswith('SN_')]
y_field = [col for col in df if col.startswith('LDO_')]
# ignore warnings
import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter('ignore')
df_peaks = pd.DataFrame()
for uid in ids:
# make empty list to story peaks
peaks=[]
for clm in x_fields:
for y in y_field:
df_id = df[df.UID==uid]
min = df_id[clm].min()
max = df_id[clm].max()
X = df_id[clm]
y = df_id[y]
model = np.poly1d(np.polyfit(X, y, 2))
fit = minimize(-model, x0=1, method='trust-constr', bounds=((min,max),))
peaks.append(fit.x[0])
# add peaks to dataframe as a column
df_peaks[uid]=peaks
df_peaks_T = df_peaks.T
I am trying to do the above in Knime without using Python Scripts.