Hello, i want to ask about a lookup with rule or something like that
for example i have a data from two table like this
Table 1 (Assume this data collected from difference source)
Bank
ID
Elemento Bank
91238
EB
37172
Elemento Bank Corporation
10234
Ele Bank
03941
EBC
28481
And then i have table 2 like this
General Bank Name
General ID
Elemento Bank Corporation
EB01
Hungary Bank
HB01
Bank of Amazing
BA01
i want to lookup/assign all the value from table 1 which is a various name that people input about the Elemento Bank and i want to assign it to the table 2 which is a general Elemento Bank Corporation so its easier for the company to get all information about Elemento Bank… so its like many to one relation… so the output table should be like this
For some processes, I would consider that maybe some kind of String similarity search would be of use, but in this case my feeling would be to go “old school” with a lookup table of synonyms and aliases. My reasoning is that you do not want to have incorrect “guesses” no matter how similar strings may be, and that you would really want to limit the range of synonyms/abbreviations allowed.
e.g. If you are allowing abbreviations then “Hungary Bank” and, say in future, “Happy Bank” could both be abbreviated to “HB”, so how would you know which was meant?
It might seem like hard work producing the synonym list, but you can always have a Conversation with chatGPT to get you started…
… and then you can add/modify the list as you need to.
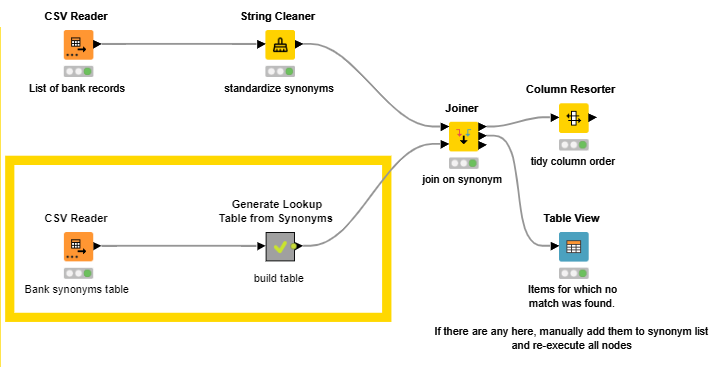
In this workflow, it takes a lookup table of synonyms for each bank, and turns this into a set of standardized synonyms (all uppercase, all whitespace, punctuation and other symbols, accents, unprintables etc removed). This list can then be joined using a similar synonym created against each entry in the input table.