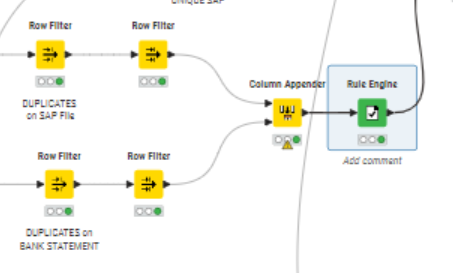
Hi @carmelavivant , in my original workflow, it was assuming that there was only one column for the matching process, and would need a little adjustment to make it work.
The workflow that you have (with a nested loop) isn’t going to work, or at least I cannot see what the logic would be to make it work. It would, incidentally, require an additional loop end because it currently has to loop starts and only one loop end, although that won’t directly solve your problem. To me this is a problem that would require only a single-loop.
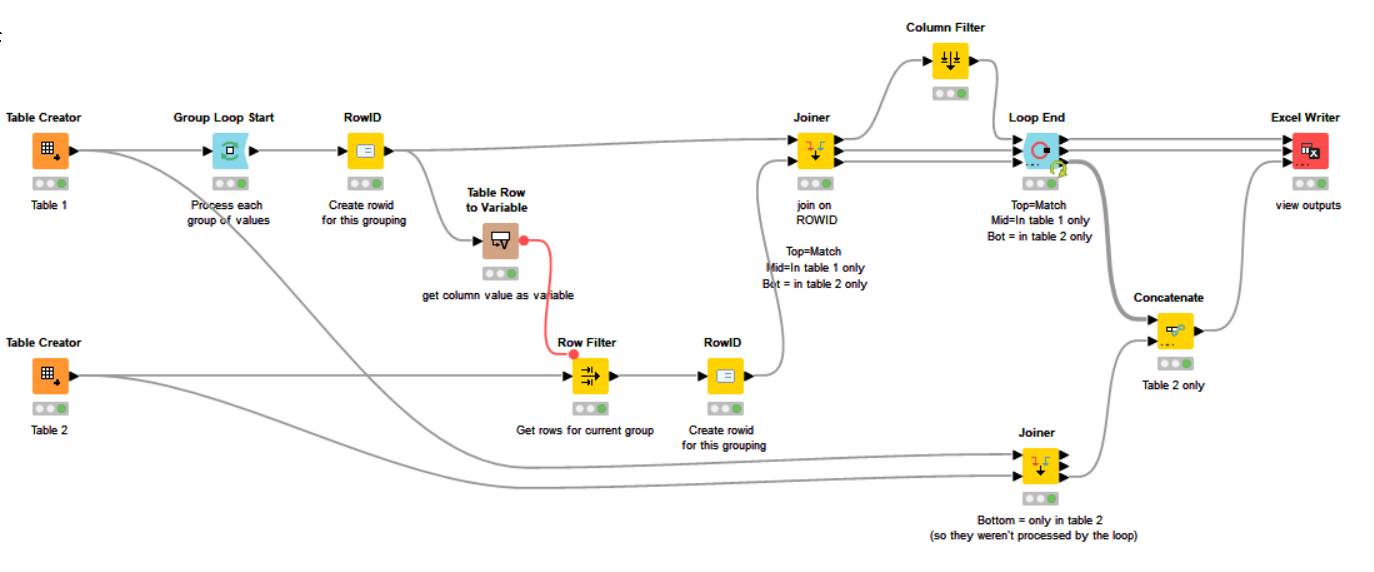
However, I took a step back and have realised that you don’t actually need any loops!
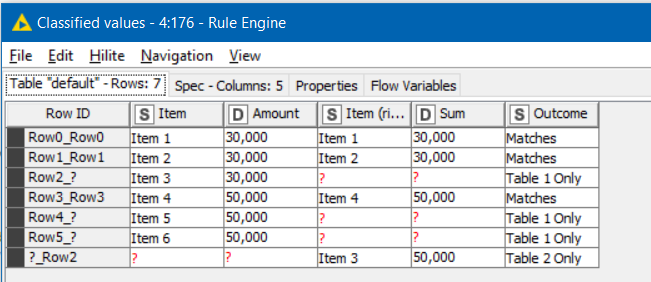
In essence, your problem is to compare two tables and identify:
rows that are in both
rows that are in Table1
rows that are in Table2.
That basically describes the function of the Joiner node, but there is one small complication which makes the Joiner node unsuitable by itself; this being that if a row is duplicated in one of the tables, we only want one to join, and the other must be considered an “extra” row that is only present in one table.
This was why I added a loop in my previous example, so that it could compare groups of rows for each key and only match these on a row-by-row basis, marking any “additional” rows in one table as “extra”.
But this doesn’t require a loop to achieve, we simply have to add an additional sequence to the “key” , grouped within the key columns. This is the job for the “Rank” node.
The Rank node can be told to group by the key columns, and rank rows with a sequence number within key groupings. The node does require an additional column other than those which defines the groups, so for the purposes of your sample data, I have had to add an additional “dummy” column.
I’m still using KNIME 4.7.x, so my nodes will appear slightly different to your KNIME 5.1 workflow, but this takes each of your sample Table Creators and determines the differences:
The Rank nodes are configured like this:
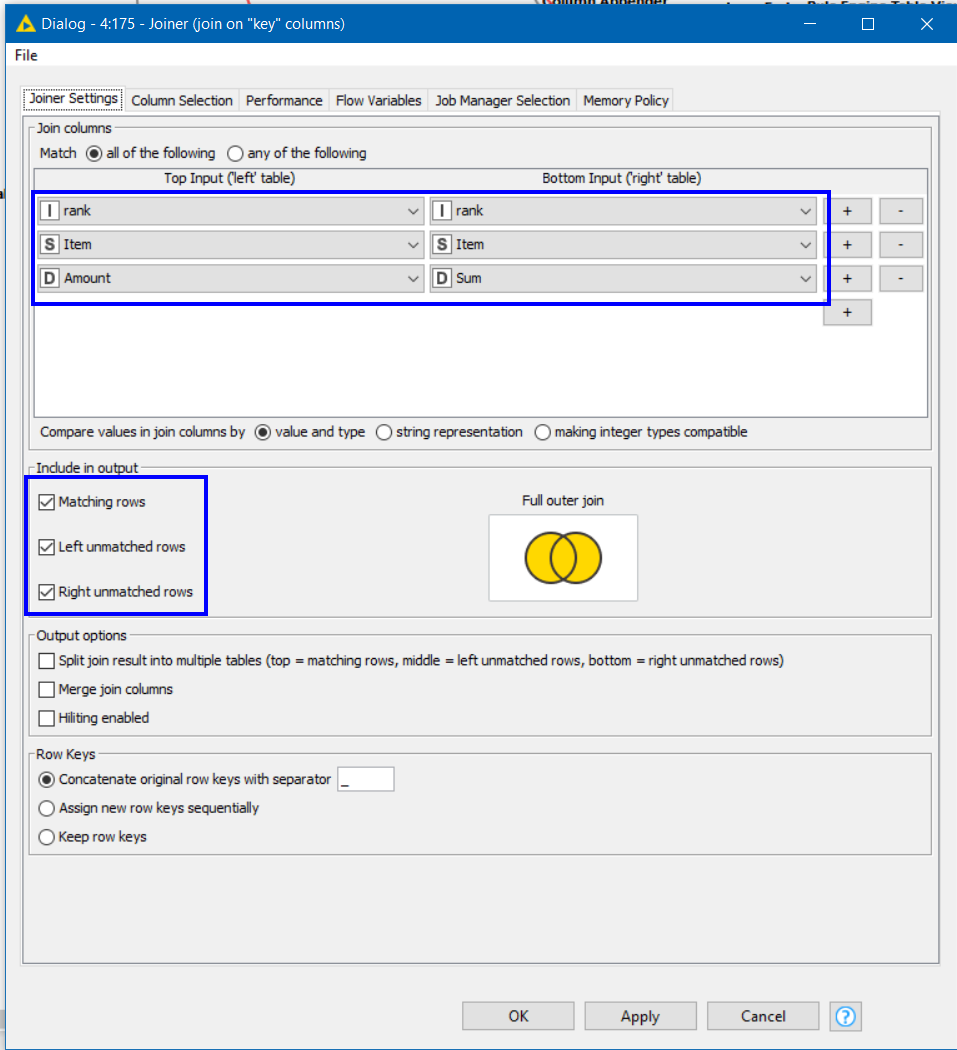
The joiner then joins using your key columns plus “rank”
and it is up to you whether you want to split the different outputs across the 3 joiner output ports, or just use the top port for further processing.
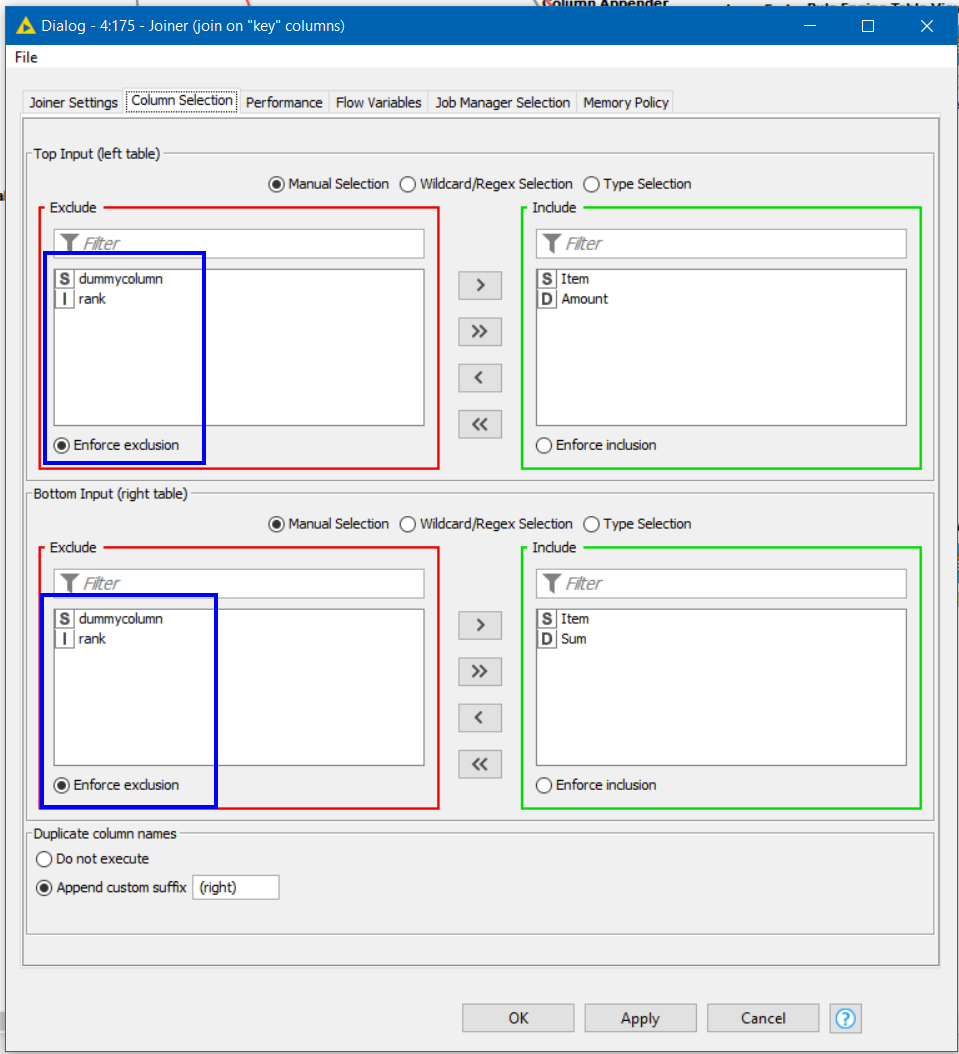
The rank and dummy columns can be excluded from output as they have done their job
forum 71643 - Loop Problem - alternative.knwf (46.8 KB)
I hope that helps