Hello! I’m working with a unique dataset and need some advice on transforming it.
strings broken down to pairs of consecutive elements.knwf (14.4 KB)
Each row in my dataset starts with the letter ‘A’ and is followed by a sequence of other letters, with varying row lengths.
For instance, some rows look like
A B C
A D E F
A G
A T R
What I aim to do is restructure this data so that each row is broken down into pairs of consecutive elements. To illustrate, from the row
A B C
I would create
A B
B C
and from the row;
A D E F
the new rows would be
A D
D E
E F
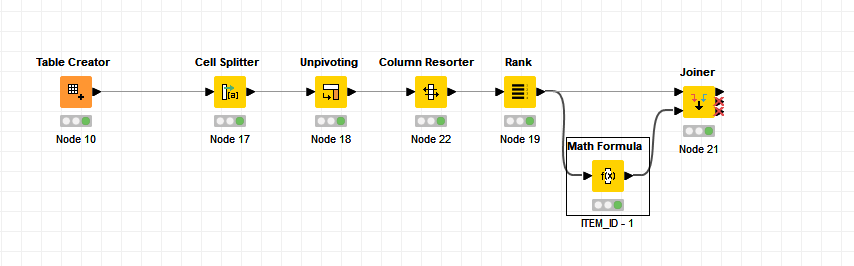
to achieve this, I’ve considered splitting each row into multiple columns, each representing one letter, and then the number of columns would depend on the number of letters in the row. After splitting, my idea is to perform a group-by operation for each first column with its subsequent column. This would essentially extract the path within the pairs until I reach the maximum number of columns for that row. Each group-by operation would then yield the consecutive pairs as a new row in my transformed dataset. However, I’m not entirely sure if this is the most efficient approach or if there’s a better method to handle this kind of data manipulation. Could you provide some insights or suggest alternative strategies that might be more effective?
I will use this method to break AS Number Paths into pairs to create a network graph.