Hi @ludvig_olsson , welcome!
Loop processing in KNIME is always going to be significantly slower than non-loop alternatives, and I wonder if it might be possible in your case to find an alternative to the loop.
As @armingrudd says, having a sample of your data and also an idea of exactly what you need to do within the loop would be useful, because it isn’t possible to give specific advice without that, and in some cases, I realise that there is no alternative but to run it as a loop, and go grab a coffee!
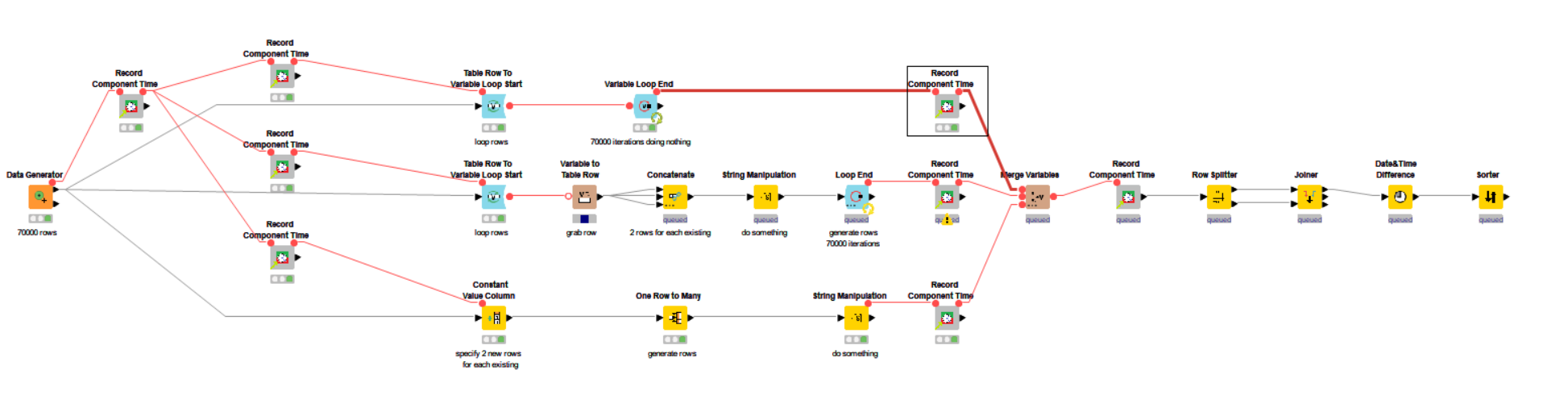
I have put together here a workflow which demonstrates the difference in processing time for a loop that does nothing (70000 times) , versus a loop that creates 2 rows for each existing row (70000 times) vs a non-loop branch that produces the same result as the middle loop, by using alternative nodes. In this case it uses the “one row to many” node, which can generate additional rows for each existing row in the table. I wonder if that particular node could help you?
At the end of this, the middle branch and lower branch have each returned 210,000 rows. The top branch has returned nothing, because it is an empty loop for comparison purposes.
I have also incorporated a component I wrote that records a timestamp at different places so we can get a simple total elapsed time in seconds for each branch.
When this finished running, the results on my laptop were as follows:
The lower branch has generated 210,000 rows from 70,000 in about 1 second.
The loop that did nothing but iterate, took over 200 seconds (to achieve nothing!)
The loop that iterated to create the same 210,000 rows that the non-loop version achieved took well over 400 seconds to do it.
I recognise that in this workflow, the processing of the loops was occurring concurrently and a true figure would be better achieved by running each in isolation but they still give good comparative results.
As with all programming constructs, loops should be avoided whenever possible (excepting that sometimes a performance hit to improve understandability/maintainability is reasonable), especially where large numbers of iterations are involved as they scale badly, but as I said, it may be that in your case it cannot be avoided. So if you are able to provide some idea of the logic contained within your loop, it may be possible for somebody to think of an alternative that removes or reduces the need for the loop.
It would be interesting for system-comparison purposes to know how fast this demo workflow completes on your system, as mine is on a not-particularly fast laptop.