hello fellow Knimers,
I am desperate … I have no problem with (nested) loops in plain code writing, but KNIME’s graphic representation (while helpful in other areas and I love it!) completely puzzles me when it comes to construction loops. I just cannot get to grips with the logic of it.
here’s the problem: I have a table with IDs in one column, and formulas in another column (this can be empty). I need to check for each row (ID) if it is dependent on another ID(s), that means: if it has a formula attached, is this formula referencing any ID(s) of the ID column.
here, ID 12277 (row 2) would be dependent on ID 12276 (row 1) and ID 12278 (row 3) and as the goal, I would like to add a column with the dependencies (as a list like in Column D, or similar).
I extracted the ID-column as a separate table and tried to chunk loop through every row of the main table to look at one formula at a time.
Then try to “side-inject” the extracted ID table to iterate through all IDs to test if they occur in this single formula from the main loop.
nesting two for-loops in code is straightforward, but I just can’t make it in KNIME ???
PS: if anyone knows a good primer for KNIME loops, please share. the KNIME flow control documentation didn’t clarify this for me…
Hi @roberting , for the last row, can you explain why your Column D does not produce a list containing ID 12275 in it? Is it because 12275 does not exist in Column B, or is it because it is outside of if-else statement brackets?
ID 12277 (row 2) is the only one with a formula that is linked to other iDs, row 1 and 3 have no formula at all, while row 4 has a formula, but is not dependent on any ID within the scope of that table (12275 does not exist/ is not listed in col B). The syntax of the formulas does not play any role here.
Column D is what I do not have yet, but what I want to achieve. these formulas are just an example, in reality there are formulas with hundreds of lines of code.
They IDs stand for Attributes (also thousands of them) that may contain static values (no formula in col C) while others derive their values from calculations, which may or may not involve any of the other attributes (IDs from col B).
For documentation purposes, I need to identify the possible dependencies for any attribute (those that have a formula == that rely on others for their calculation).
So I need to check every single formula against all IDs, to see if any of the IDs is contained in this code (doesn’t matter how or where exactly). The part of extracting/identifying the IDs in the code is also not the problem (I will do that with Regex) – I am having trouble setting up something embarrassingly simple as nested loops do do that crosschecking.
Hi @badger101
If there’s a way to do that without looping through the rows, please let me know.
I want to solve this problem in the first place – but as the graphic representation of loops in KNIME is bewildering me, input on the loop matter is still wellcome!
As for your quest to learn more on the “graphic representation of loops in Knime”, you can always share an annotated screenshot of how you set it up, and point out at which point did it get too complex. I’m sure once people see that, they can help “translate” what’s going on for you
Cheers @badger101 !
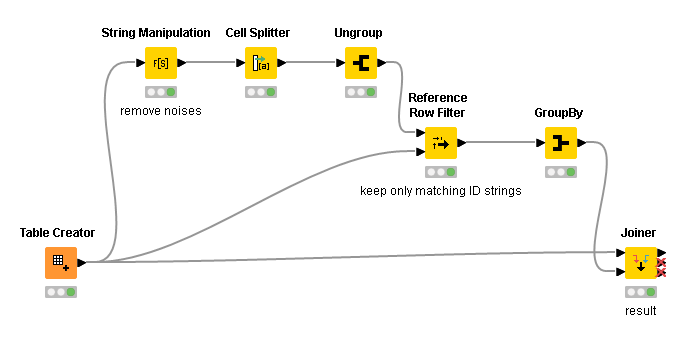
I didn’t think of Group/Ungroup, great hint!
However, I need to identify the IDs exactly - I cannot only throw away everything that’s not numerical.
IDs (unlike in the example) can have any length up to 40 chars and are alphanumerical, with possible spaces, and a handful of allowed special chars – plus there is no common structure to them.
So the safe way would be to really search/match each ID against the code string – and this is what brought me to looping through a list of these iDs, checking each of them if it is contained in the code or not.
Okay @roberting what you need to do is to list ALL regex patterns for those IDs. Then the regex experts on the forum will come and offer solutions. Good luck!
While you wait for potential solutions from others, here’s a temporary alternative to regex.
It utilizes substring match.
Suits complex string cases as you described, however, substring-based method can produce false positive identifications when short & simple reference IDs are used. Use with caution
Wow!
When I saw this approach, I was skeptical about because of the multiplication that happens in the ungroup node - with my data it produces a 160 million row table, but the laptop could handle this in 5 mins. Great! thanks!
P/S. FYI there's more than one way to do substring matching in KNIME, so if in the future you'll work with an even larger dataset, we can always test out the alternatives for performance purposes.