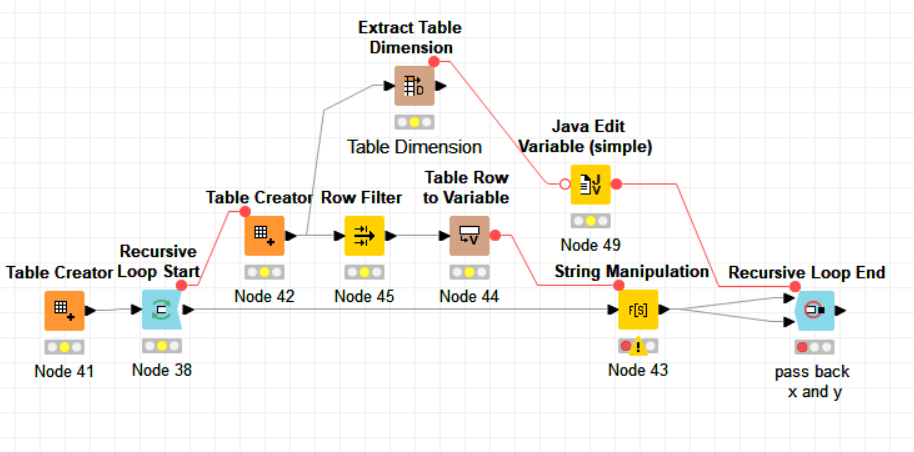
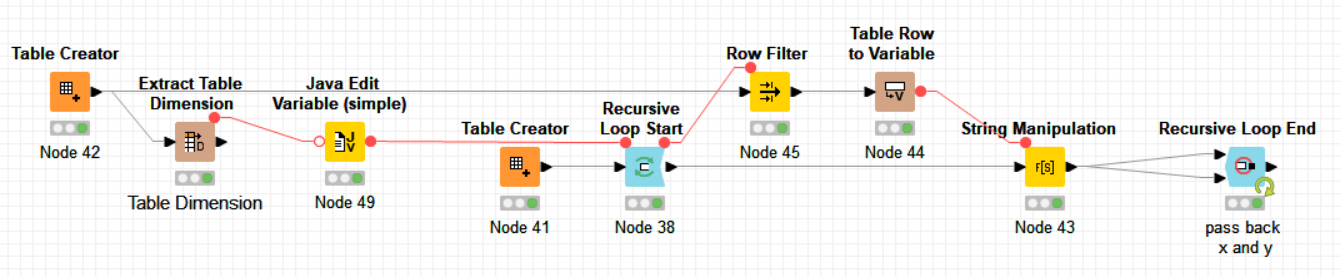
Think of a normal loop where first time you get the data table from the input (as usual) but at next iterations (n) you get as table in the loop input what the loop output provided as table at iteration (n-1).
It is a very powerful concept which allows to re-utilize loop output data from previous iteration at each next iteration until a stop condition is reached. The condition can be diverse, for instance n. of iterations but also a condition pre-established by yourself.
Hope this sheds some light. Otherwise just let’s us know
Then I give you a like for your help and hope it increases your reward even more
Seriously It nice to have people invest their time and help out here!
br
Also here is my contribution as a beginner. A leave a simple workflow for KNIMers wanting to understand the concept of the recursive loop at the basic level.
The -Table Creator- (node 42), -Extract Table Dimension- and -Java Edit Variable- nodes do not change inside the loop, so for a question of efficiency, it is better to initialize them outside and before the loop only once for ever. Otherwise, KNIME will execute them at every loop. This is without impact in a toy example but may become significant in a real case. Just a last improvement and suggestion: add comments to the nodes explaining what each one does when sharing a workflow. People will appreciate it !
Your workflow nicely shows how the task given to the -String Manipulation- node can change over the iterations of a loop, acting every time on the same strings which get gradually and differently modified thanks to the recursive loop. Indeed, without a recursive loop, this task would be difficult to implement.
Nice idea. Actually, before using the recursive loop I was saving the list of modified terms that were generated in the first loop as a table with the table writer node, and then reading the same table again at the beginning of the next iteration. it did the job, but it was extremely slow when processing long lists.
Indeed, this would have been the alternatively solution if the recursive loop did not exist. KNIME is doing the same behind the scene, but obviously in a much more efficient way which makes the process faster and simpler to the user.

 !
!