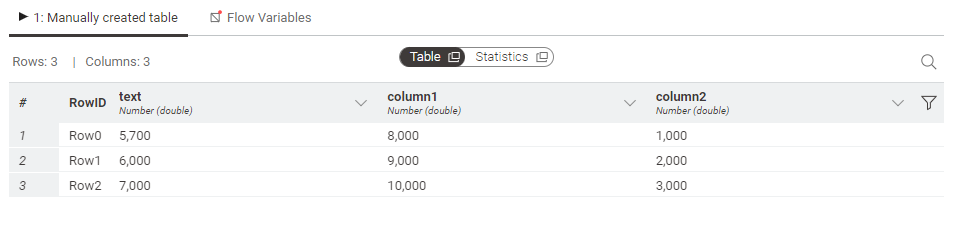
I have the following data and I want to divide the values from the second to the sixth column by 1000.
0.00310197
424868.0
0.0
0.0
0.0
80.727
0.00321034
685538.0
0.0
0.0
0.0
410.426
0.00331503
952584.0
0.0
0.0
0.0
1838.99
0.00341881
1209740.0
0.0
0.0
0.0
8755.59
0.0035226
1428250.0
0.0
0.0
0.0
48348.9
0.00362638
1588640.0
0.0
0.0
0.0
149099.0
I wanted to make a loop over the columns after excluding the first one to divide the values by 1000 :
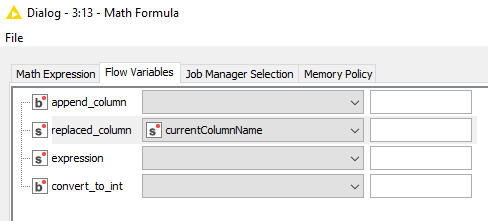
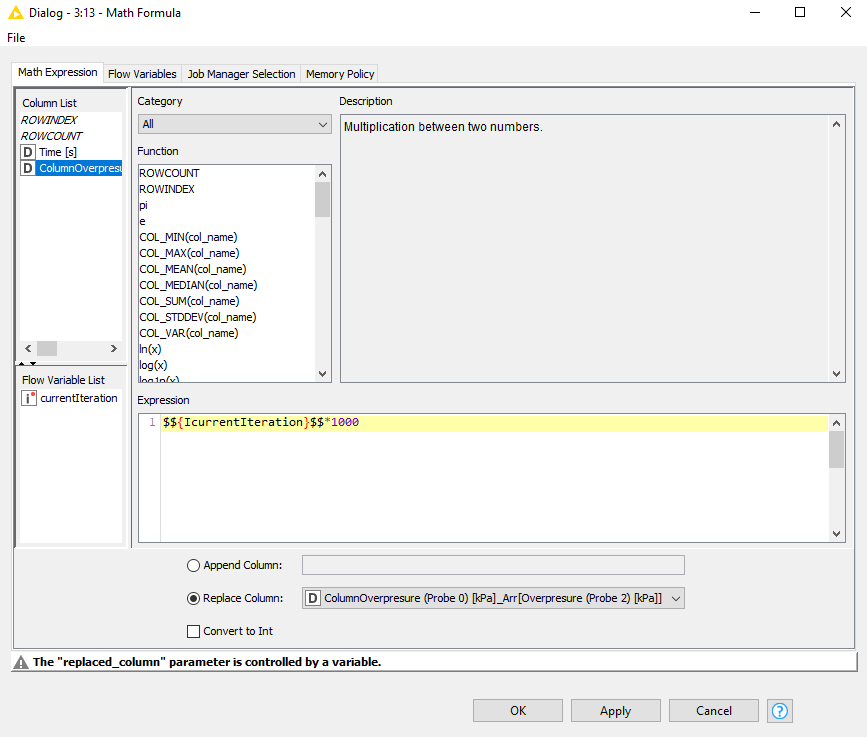
Unfortunatly with the “Math Formula” node, I need to specify the column name I want to make the operations, and the name of each column is different at each iteraration so it doesn’t work.
I can successfully replace the values using the currentColumnName from the Column List Loop Start node :
But I cannot use this field for math operations as it is a string :
I tried to convert my column name to double with a StringManipulation (variable) node but as you probably guessed, converting letters to double doesn’t fwork.
Do you know what format I need to convert my column header to, to be able tu use it in the math formula node ?
These solutions would be the easiest, I agree. Unfortunatly I may have different column names and number of column when I work with different datasets so the loop seem the best idea at this point.
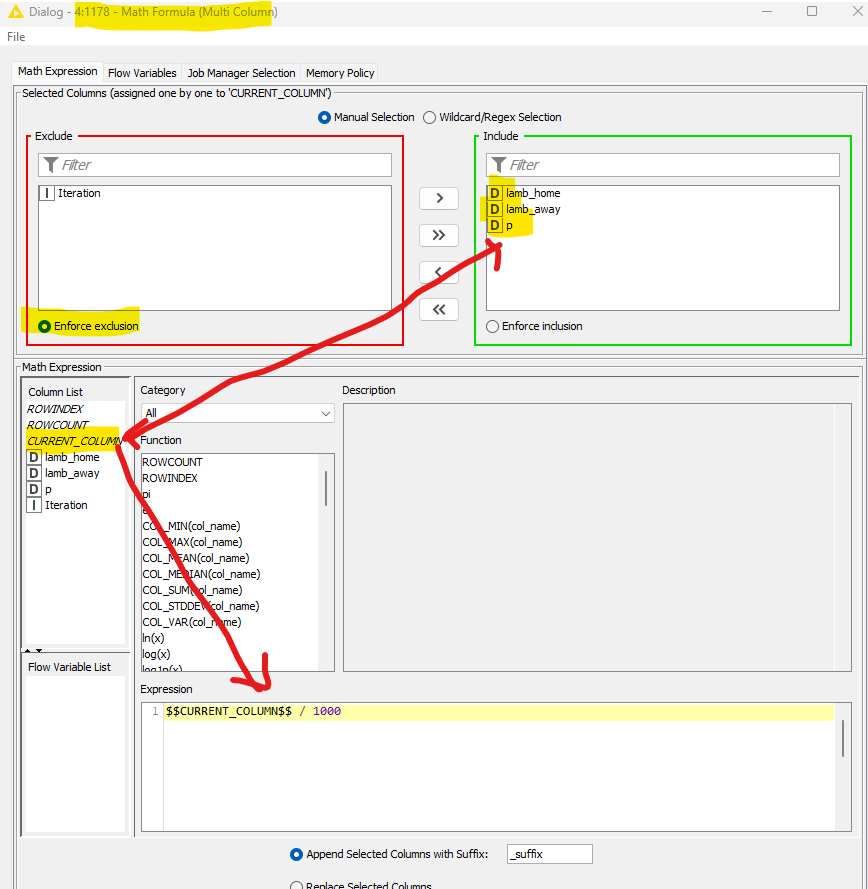
Did you actually try to use the Math Formula (Multi Column) node?
If you configure it like the screenshot above (Enforce exclusion on the columns to exclude), the number of columns and the name of the columns doesn’t matter. They all will be processed. Every column that is not defined in the Exclude box, will be divided by 1000.
use table transposer again - now columns headers are always Row0 to Row5
use math formula multi column and exclude Row5
Then I think there are ways to send the original data set through row filter to remove all rows (pretty much empty table with original headers) and the concatenation with output from math node (think there is a away to configure it to stack them on top of each other despite mismatch in column names)
Probably a bit of an alternative approach but might do the job.