Try copying them from the example workflow.
@Brock_Tibert it is not a node but a function you add to a component or qualified node.
Some nodes can also be used for streaming depending on the sort of node. You activate it under job manager under the configuration.
It still is beta though. Has solved several data transfer problems over time.
2 Likes
@Brock_Tibert what you also can do is tell the driver to reconnect to the data source if lost. Also you can set up a construct where you track the tables you already have processed and start with the ones that have not yet been. The article also deals with that.
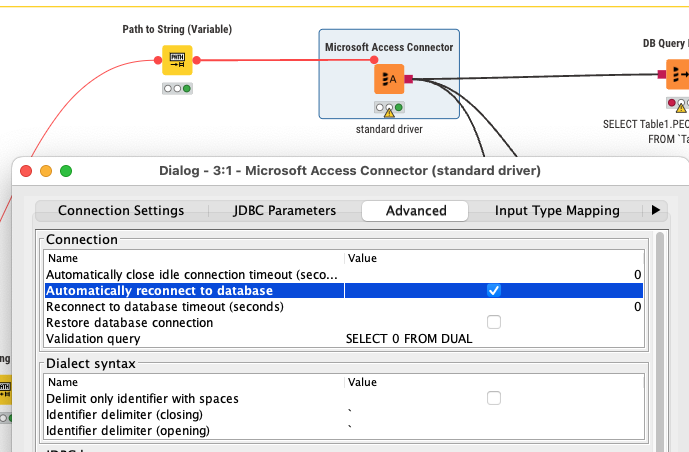
1 Like
I wanted to close the loop on this. While I couldn’t seem to crack the case on getting this to run end-to-end for the 20 years worth of Access Files (1 per year), I could mostly get around the Heap errors by running one year at a time. I found that after a year was processed, clicking “Reset All” did the trick. Without this, I would get a memory error on the “next” attempt.
As a one-off task, this is more than sufficient.
Thank you to everyone who assisted above. It was constructive as I used these tasks to really dive into KNIME.
4 Likes
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.