Let me start by saying I have searched the forums and after a reading a number of past posts, I still don’t quite understand what the setup looks like for a loop within a loop. I am still getting my feet under me, but the use of nodes to start and end loops is baking my brain.
What I am looking to do:
For each file in a path, load the database (MS Access) at that path. This component of walking the directories and setting up the file paths for the parent loop, loop 1, is all set. I will come back to this issue in a moment.
After loading the database from the path as part of loop 1, identify the tables, and for each table, read the table and write it to another database. I will call this loop 2 logic. I have this working for a single year only.
In short, I have everything working the way I want, the only bit that is tripping me up is the top-level loop 1. It’s not iterating.
My question: Are there any painfully simple tips and tricks that show how to perform a nested loop, and show how the parent loop goes to the next iteration after the child loop completes its iterations?
This post indicates up to 4 nested loops are possible, even with recursion, so I am confident it can be done, but based on my setup, I am not sure why the parent loop (loop 1) does not iterate after it completes its iterations (~30).
I start with dummy data for your paths. This goes into a chunk loop with chunk size = 1.
Inside this loop I simulate “fetching” tables (filtering a map…). Once I have all the tables I send the new table to a new chunk loop also with chunk size =1.
Inside that loop is your table transfer logic - I just add a new column with a “Processed” Flag.
Depending on the details you may need to use other loop starts or maybe turn parts of the table inside the loop to variables, but to assess that a minimal example of your set up is required.
@Brock_Tibert one idea can be to enclose the inner workings of a loop in a Metanode or Component. Also you can try to select the scope (right click) and see if the logic does make sense. Maybe you can provide a screenshot.
My question: You put two consecutive Loop End nodes together. What exactly are these doing, and how does KNIME know which loop these apply to? Do they work “inside” out?
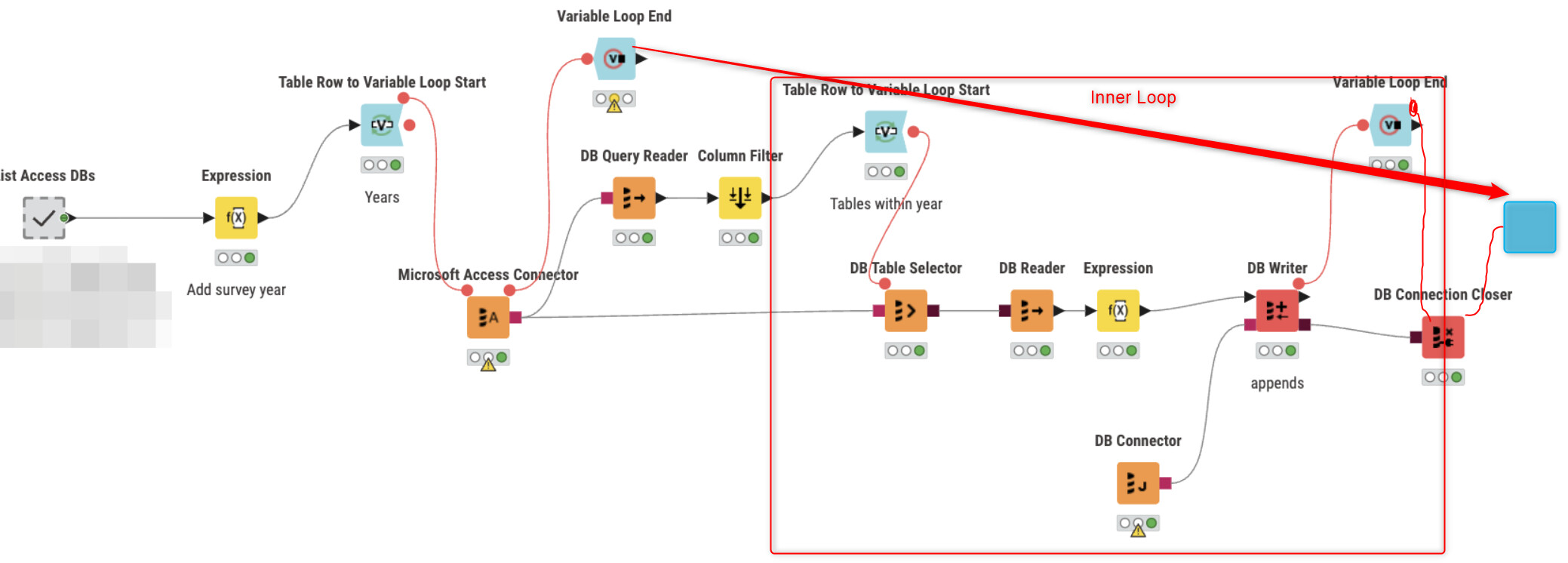
Yes. The first one closes out and collects results from the inner loop (DB Table moving) and the second one collects results from the outer loop (passing in paths to inner loop)
You can try and execute it step-wise to follow what is happening.
Thanks for this! The article you reference outlines a number of the tasks I am using, like using the Table rows for the iterations of the loop, iterating over files, etc. I also created my first Metanode for the first portion of my workflow; collect the database file locations on my local machine.
At least one bit that I am hung up on is the separation of logic between the two different loops. In Python, this is a pretty straight forward process, but the library I use is falling over on a few of the files. KNIME, however, is handling them with ease, so I am using this need as a way to “learn-by-doing”, I just can’t wrap my head around how to get the parent loop to iterate.
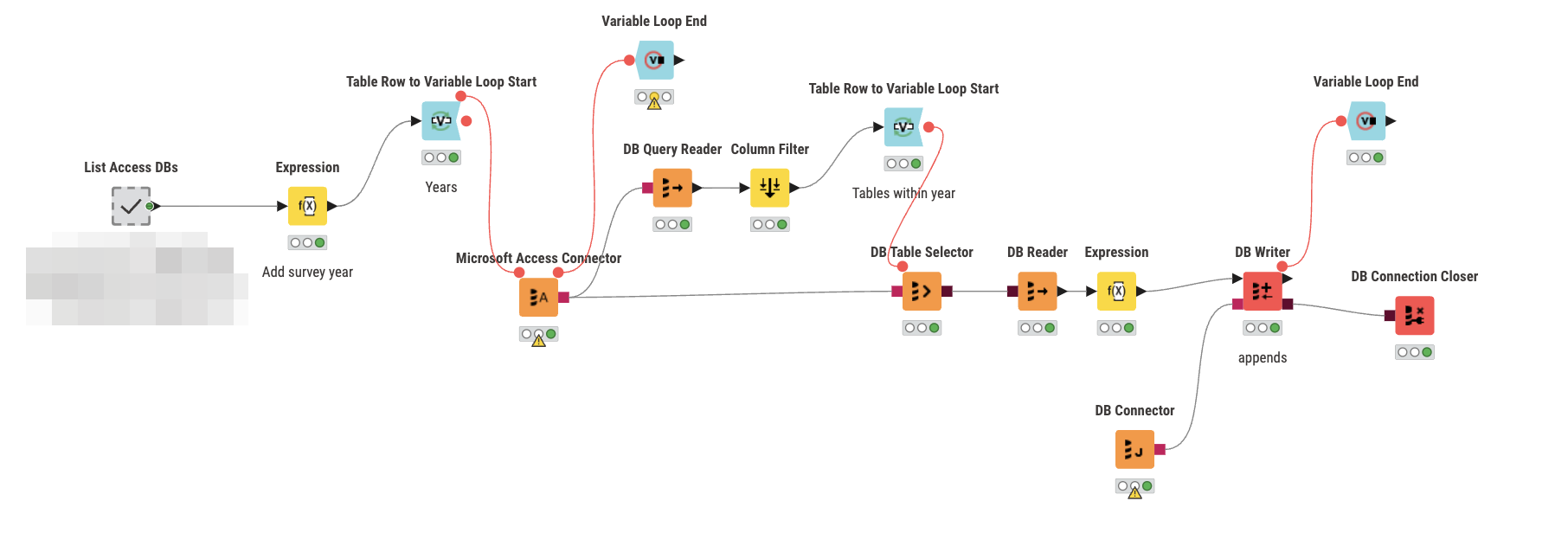
This is a screenshot of my loop. As I noted in the first post, it mostly works, but the parent loop (a valid list of file paths) doesn’t iterate. The child loop works on the tables, writes them to the new data store, and then concludes.
@ActionAndi@mlauber71 So it’s becoming clear that we end the inner most loops before the outer. Is there any documentation on this notion and after connecting the flow variables, what the flow variables are doing for the loop specifically?
I am learning as I go as I saw this side project as a fun opportunity to dive into more advanced KNIME flows. While I do scan for docs and resources, I am mostly clicking execute and crossing my fingers that it works. The point is that I would love to try to build some intuition as to how the nodes help “Frame” a loop and why the flow variables are helping with the iterations. To date, I am mostly using the flow variable as a dynamic input, but I suspect there is more to it.
And thank you both for providing some help (and patience) as I go!
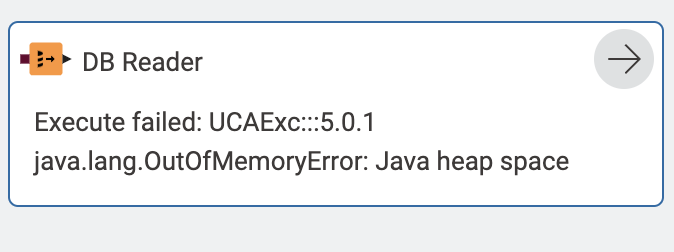
Thanks for the help everyone. I have the pipeline running, but now I am hitting OOM errors. I have 20 MS Access DB Files that are about .5 GIG each, and my loop simply wants to read in one table at a time, write it to another data store, and then move on. After a table is written, I no longer want the data. I attempted to use this community Garbage Collector Node to no avail.
I attempted to use the “Write tables to disc” option on the DB Reader node, but that only seems to have things hang.
Any other tips or tricks without restarting my computer after each pass (i.e. year) of the data?
As for MS Access, this is not by choice. I am working with a public source that distributes the annual data in Access, one database per year. What I am attempting to do is pull the data out of MS Access and store it in DuckDB. I want to build a warehouse over the twenty years, but the first step is to pull out the data and work with the data elsewhere.
Maybe streaming is an option? My understanding is that streaming allows processing chunks where each chunk is not cached - only the final output is.
Not all nodes are compatible with streaming though I think… not in front of a computer as of now, but pretty sure this is covered in @mlauber71 s medium article about knime optimization…
I know this is going to sound silly, but I have the Streaming Extension installed (new KNIME session, no workspace open), restarted (a few times now) but I can’t search and find the Streaming Nodes. I loaded the example workflow from the link above fine, and KNIME didn’t ask me to install the extension, and I confirmed the extension is installed, but for the life of me can’t figure out how to search for an add the streaming node to a blank workflow.