Hi, I am looking to create a loop to join up two columns so that I can get every iteration or combination possible. I know I can do this other ways with creating a constant value column and then join with string manipulation but was hoping to try it via a loop. Image below explains it better.
Thanks.
True, loop practice but also then possibly more scalable for larger data.
The cross join also works well for this and I’m not too fussed by “needing a loop”.
Thanks @takbb & @ArjenEX
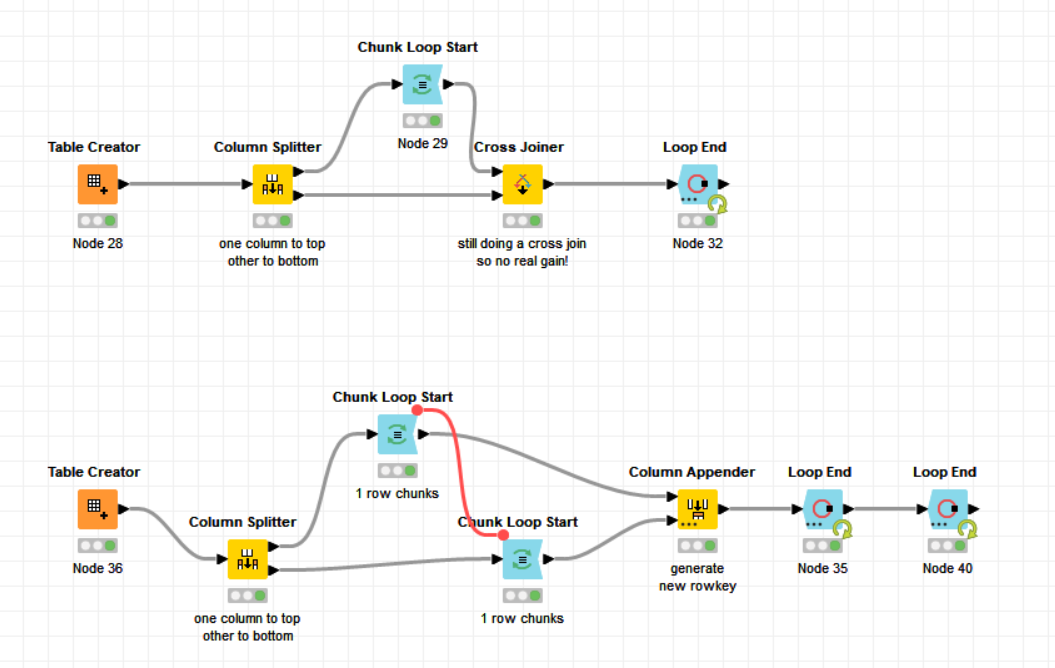
As an academic exercise, loops could be done like this:
The first option iterates each row from the first column and then cross joins with all rows from the bottom. So it’s still performing a Cross Join, which kind of makes it a little pointless
The second one avoids the cross join using two loops with one nested inside the other.
It’s difficult to say that either would be more scalable for larger data. Ultimately you are still cross joining (just manually and more slowly), and the larger the data, the greater the number of combinations produced so as far as I can see, looping is simply going to increase the time taken and still use memory resources.
KNIME loops (like all programming loops) scale really badly from a performance point of view, so the more that can be done inside a single node (e.g. cross-joiner) the better, as data volumes increase.
I guess if you wanted to collect the results but not retain all combinations in memory, writing each major iteration to a file, and performing garbage collection, without retaining the collected data table could keep memory cost down but at the expense of performance.
That might scale better for memory but if data volumes are huge, I wouldn’t want to sit around waiting for it to complete! Buying more memory might be the more scalable option