Am trying to build a simple time series model using the Keras nodes. Am new to deep learning so would love get your input on whether I have set up the data and the nodes appropriately.
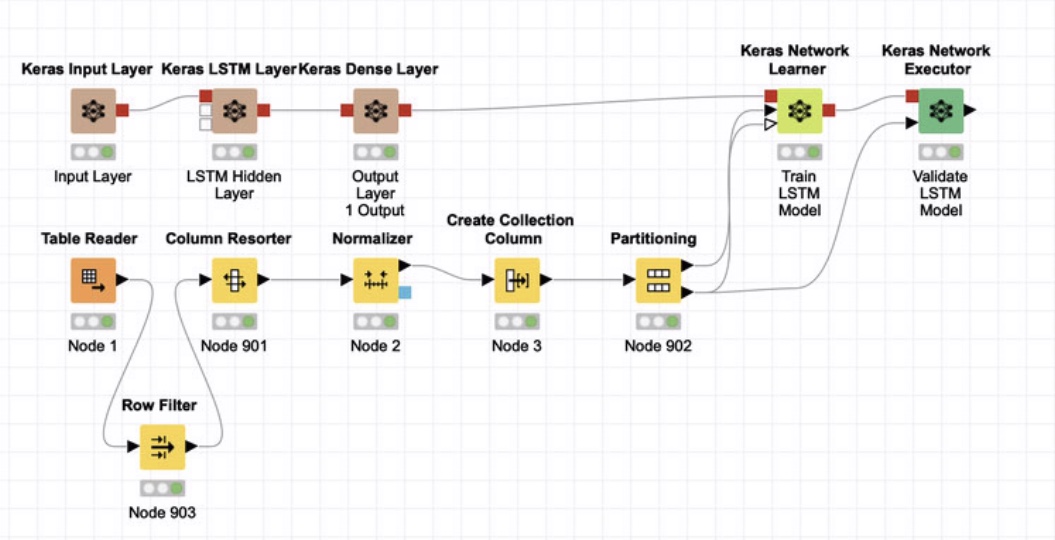
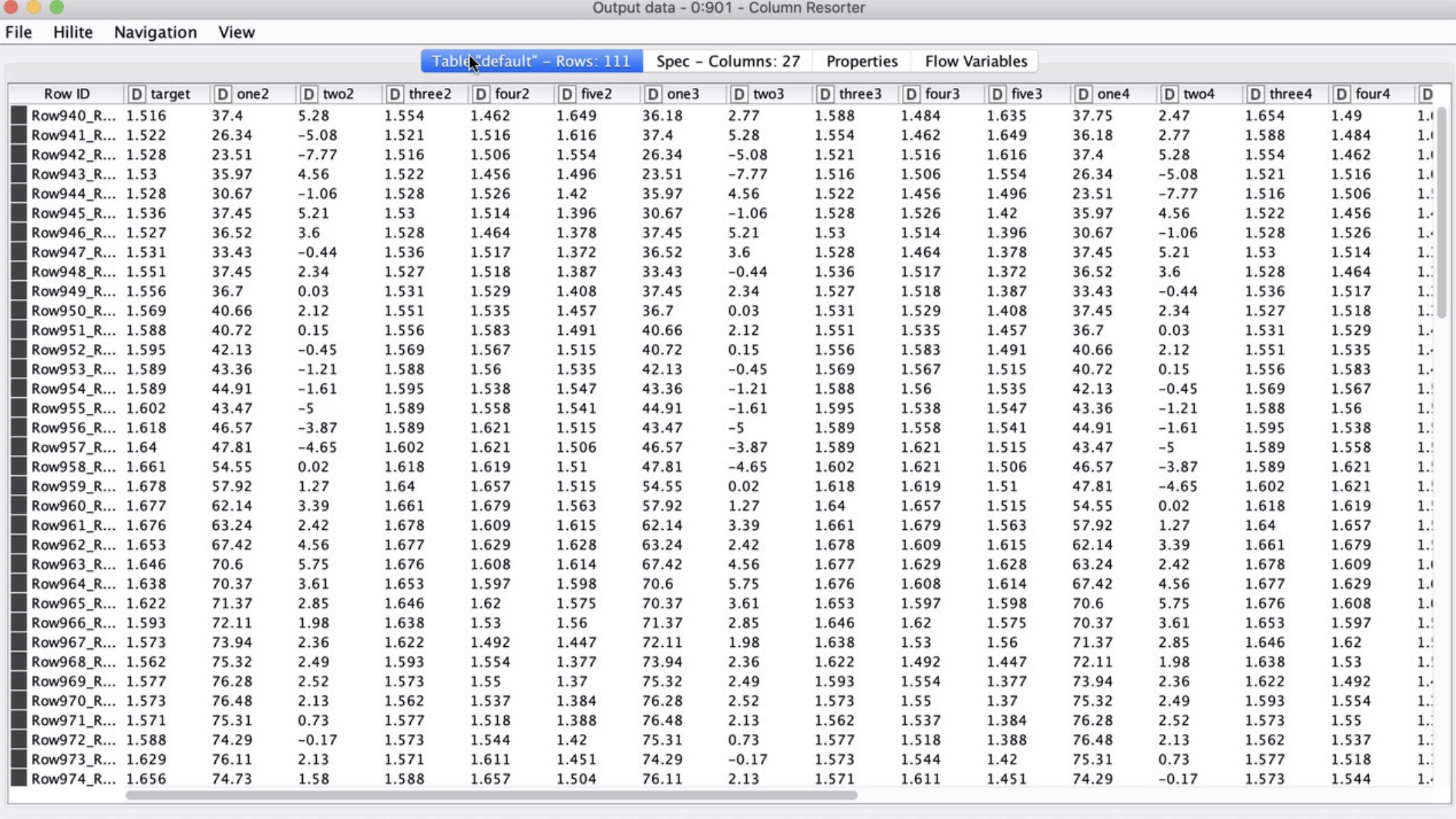
Original data: Am using time series data where each row is 1 week. Goal is the predict the column called “target”, with 5 features (called “one”, “two”, “three”, “four”, and “five”). Each of these five features has a 5 week lag (called “one2”, “one3”, “one4”, “one5”, “one6”). Have excluded the first lag, since the use case is to predict 2 weeks out. Here’s what the features look like:
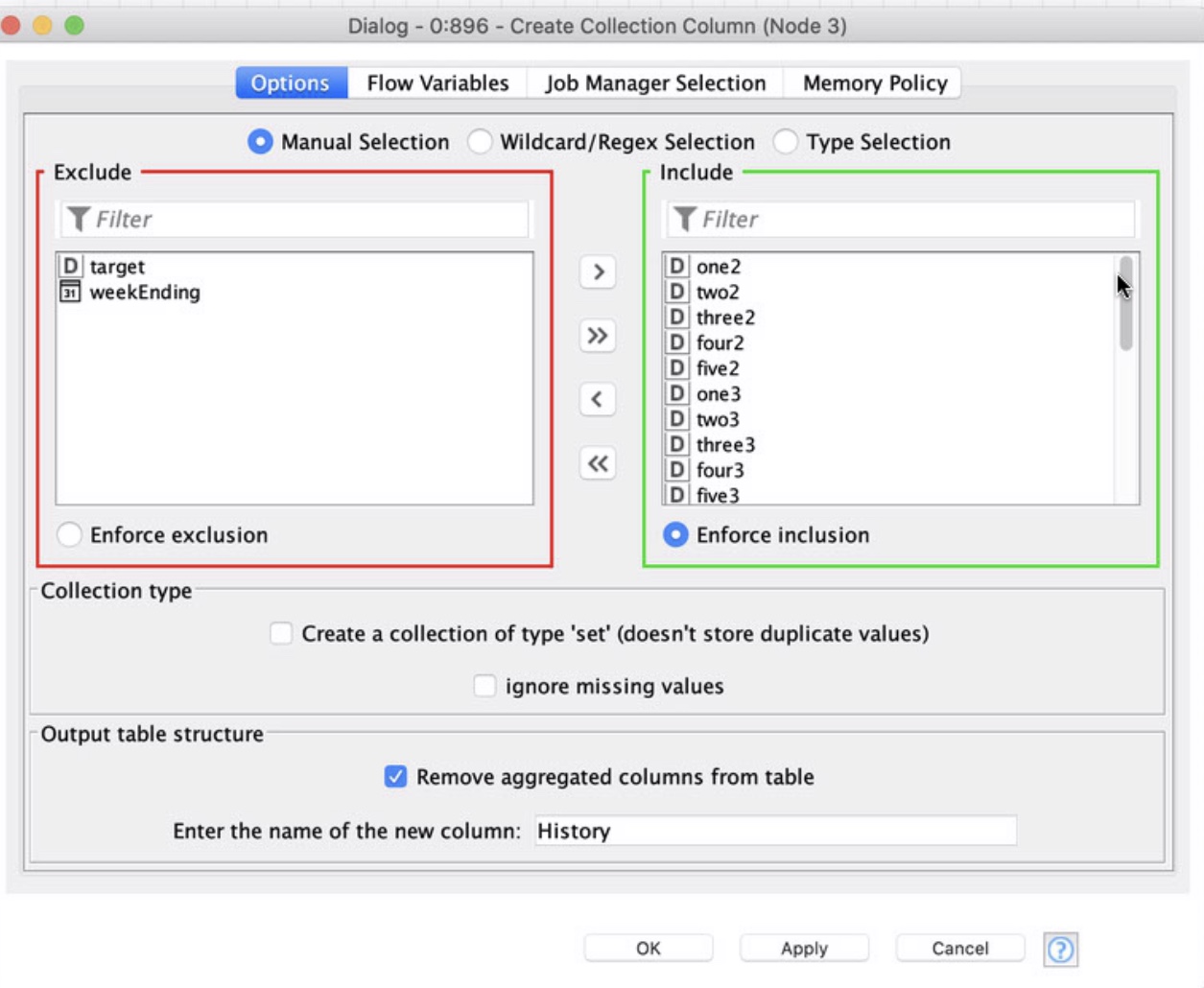
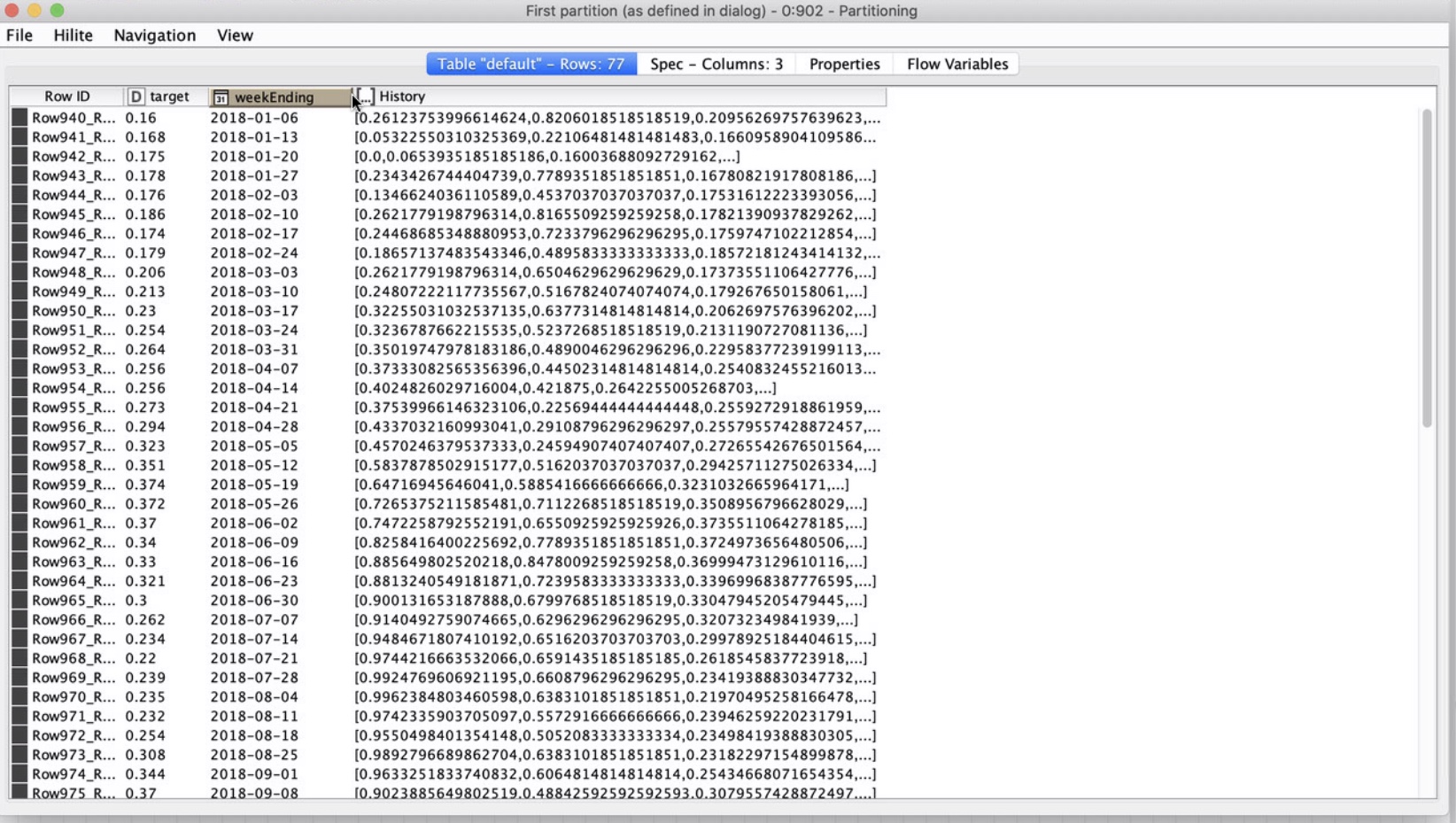
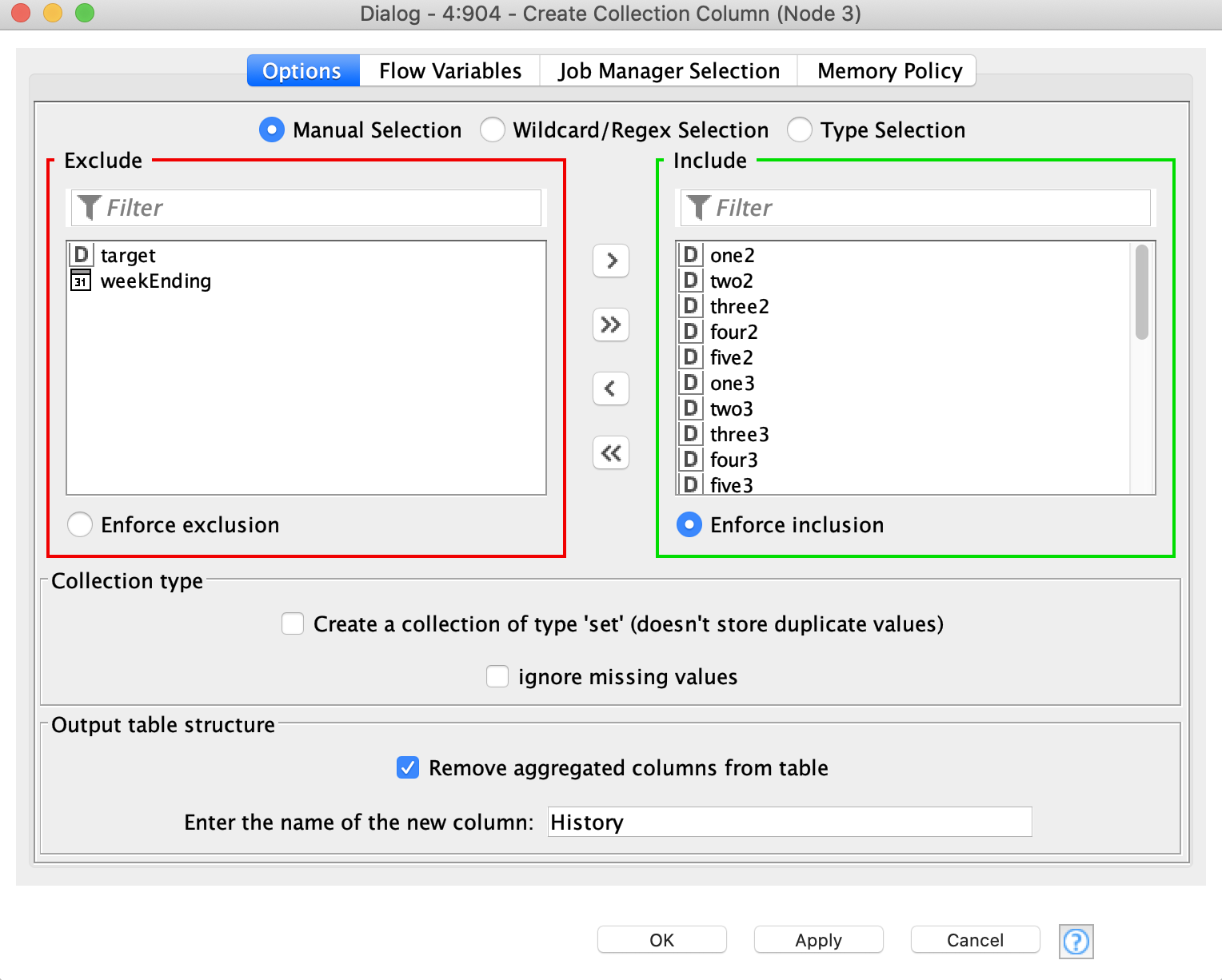
Transformed data: After normalizing the data, created a collection of a single column for these features.
Here’s what the configuration of the create collection Column node looks like:
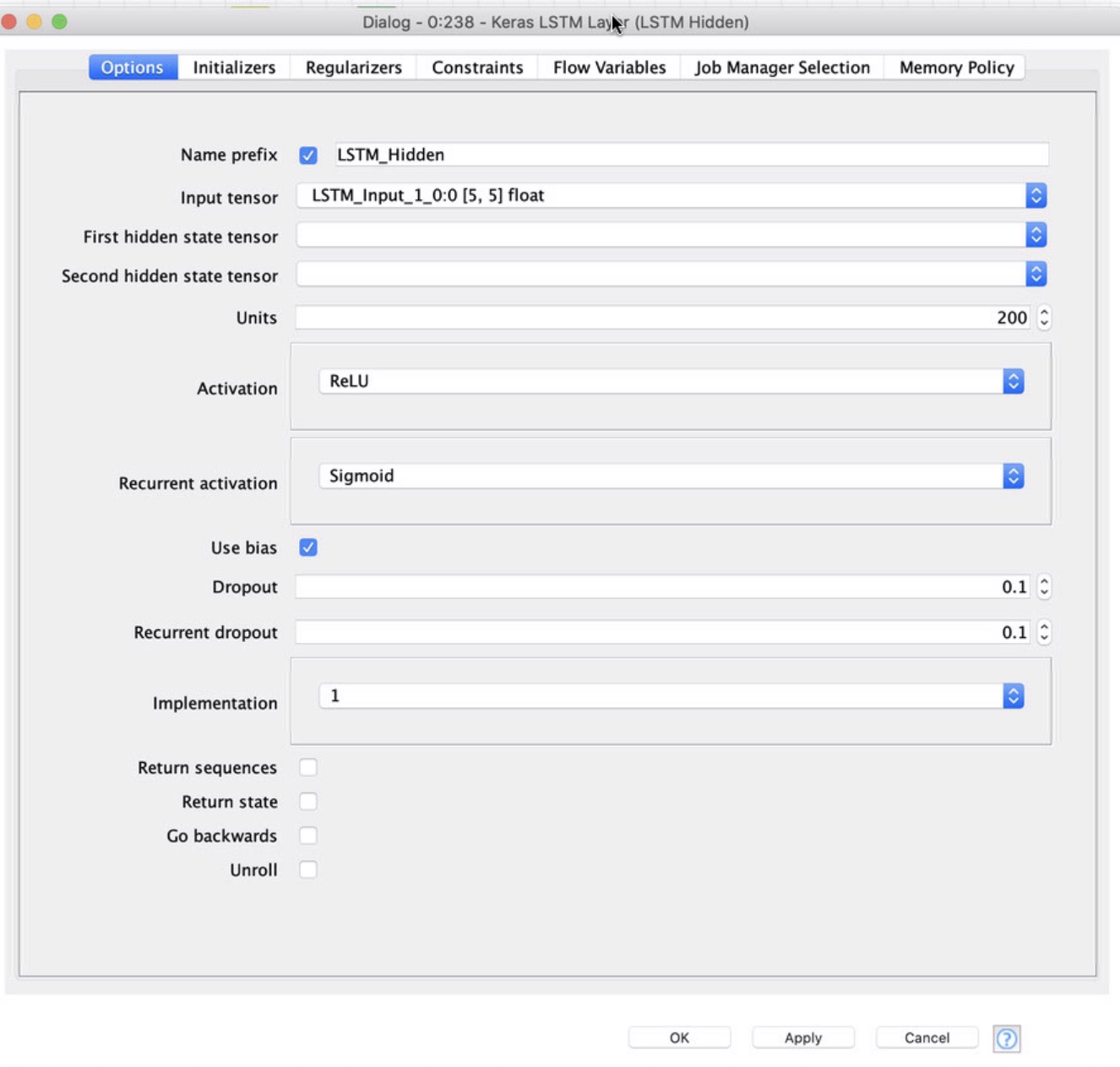
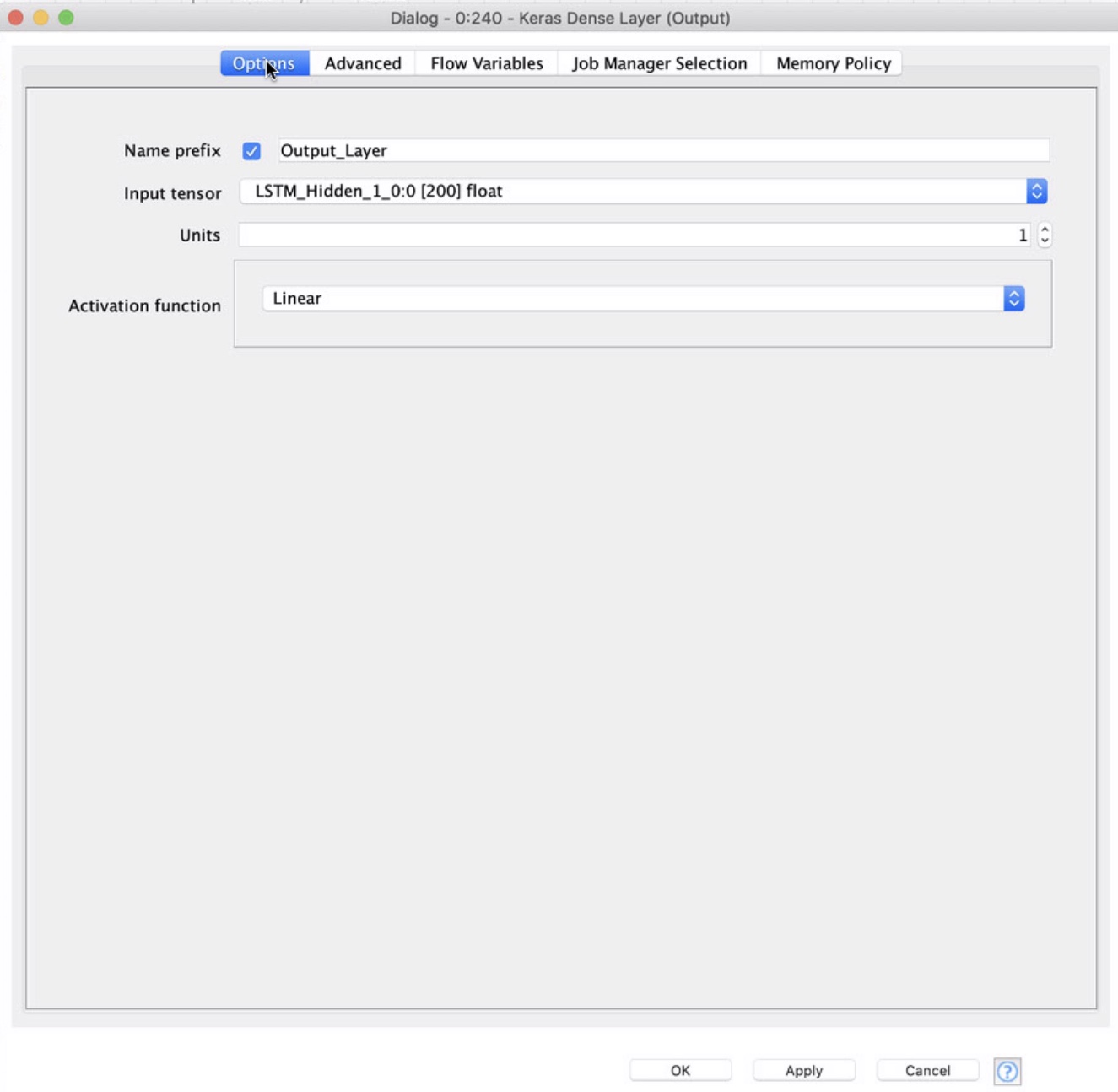
I think that’s a good starting architecture, one thing I may play with is an extra dense layer between the LSTM and intended output. Hard to say if that would ultimately help or hurt though.
That being said your output shape seems a little off, if I’m understanding the use case properly. It looks like you’re trying to build a classification model, with 5 possible output classes.
The most intuitive way to do that would be with an output tensor of shape [5]. One unit for each possible class. To frame your data for that output I would first convert the double column(Target) to a string and then use the One to Many node to one-hot encode it into a vector.
You would then have a collection of inputs and a collection of outputs, [1,0,0,0,0] if the correct target value was one for example.
Finally after setting that final output layer to shape [5], you should use a Softmax activation function. Think of it as a generalized sigmoid that works well with more than 2 classes, this way you output a set of probabilities for each possible class. You train your model to get that probability distribution as close as possible to correct. (I’d recommend Categorical Cross Entropy as your loss function)
In this framework your network would output 5 probabilities so to get the prediction you would simply use a Column Aggregator node to grab the max and presto, classification obtained.
Best of luck! Curious to hear how your project goes
-Corey.
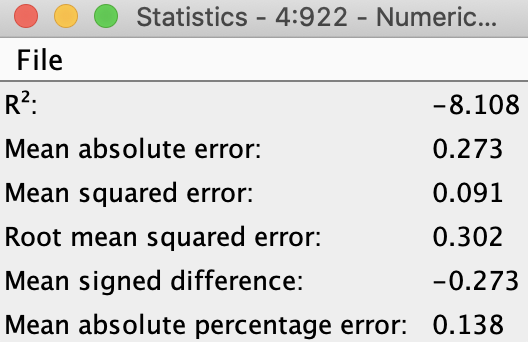
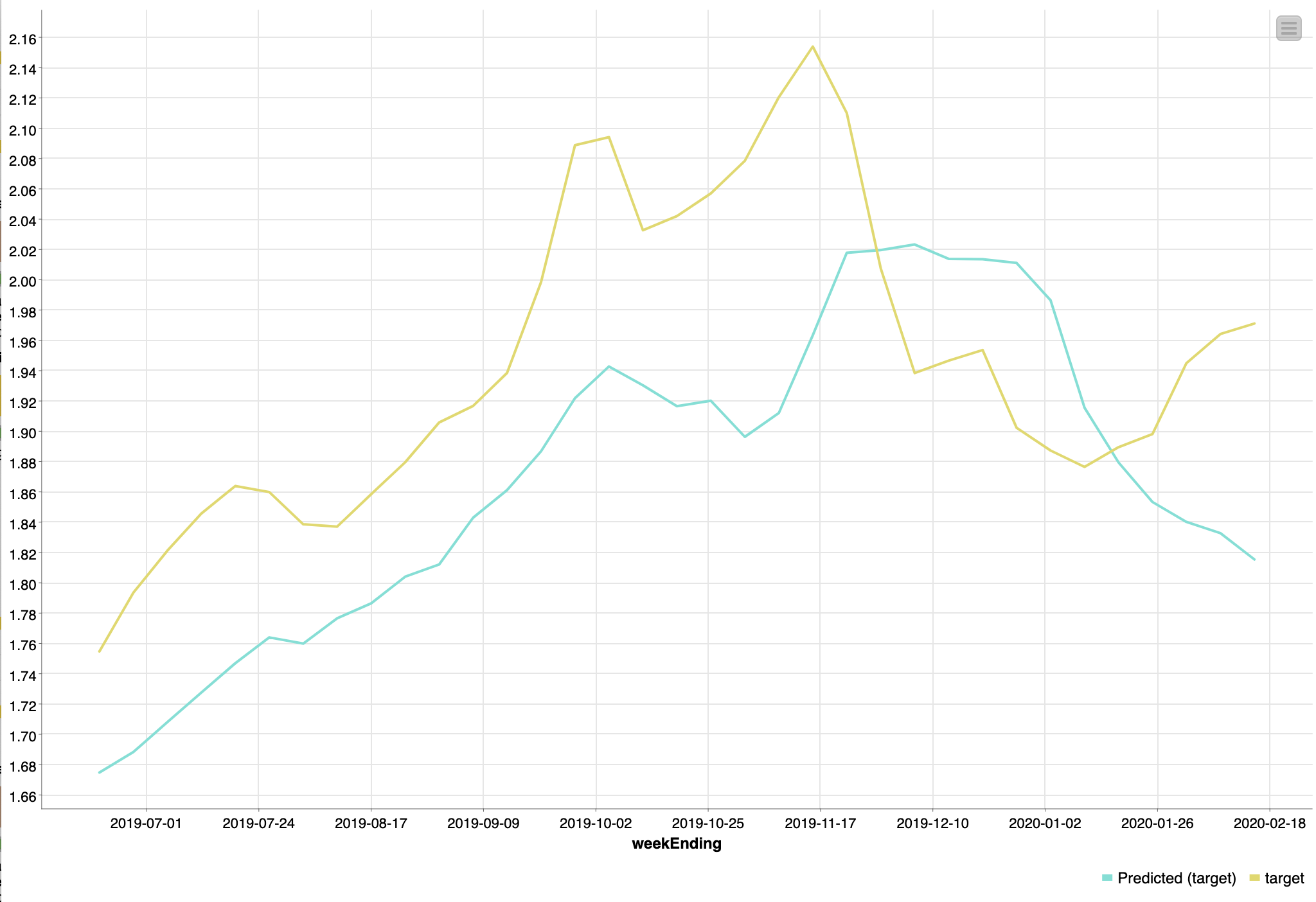
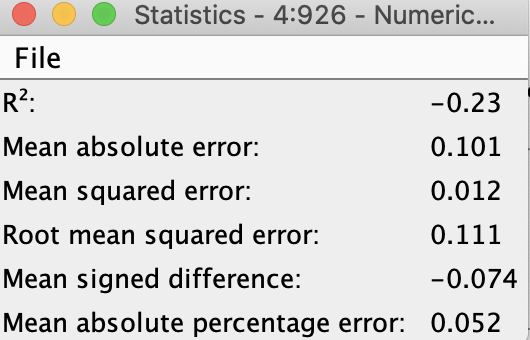
Thanks Corey! Your question on use case makes me think that I may not have set up the data and/or architecture appropriately.
The data is time series with no cross-sections, and use case is to make predictions for each week for a continuous variable (regression problem, not classification).
Based on this info, please do let me know if you would suggest any other changes.
Have attached my workflow, in case you have a few minutes to take a look.
Ah I think I’m on the same page now.
You have a 5 dimensional series(each lagged 6 times) as an input and a 1 dimensional series as an output.
A couple questions:
Is the goal always to predict the 2 week value (not the 3, 4, 5 etc)?
Any practical reason not to use more than 6 lags?
will you have those input series available before generating your prediction?
To add a comment about the LSTM layer here. It’s value comes in when doing more long term forecasting. For example if you predict the 2 week, use that to predict the 3 week, then the 4 week, so on and so forth. It holds past information indefinitely, in a sense. Useful when your forecast horizon is very far out.
If we’re always using known data to forecast the 2 week out value we can use a dense layer instead of an LSTM layer.
Thanks Corey! That’s correct - the 5 series are lagged and I removed the “minus sign” that gets appended as a part of the numerical suffix when using the lag column node.
To answer your questions:
Am initially predicting 2 weeks out, but if the predictions are accurate, would love to predict out further, and of course update the model as new data becomes available each week. Quick point - since the goal is to predict 2 weeks out, have excluded the 1 period lag for all features.
Had done a quick correlation analysis and noticed that beyond 6 or so lags, the correlations were low-ish. Happy to extend further, if you think it would help
Yes, I will have the observed data for the lagged values (2 through 6) for each of the 5 inputs.
Thanks again. Am new to DL so please do let me know what adjustments/changes you might suggest.
Hi Corey, just wanted to see if you had any thoughts based on my answers.
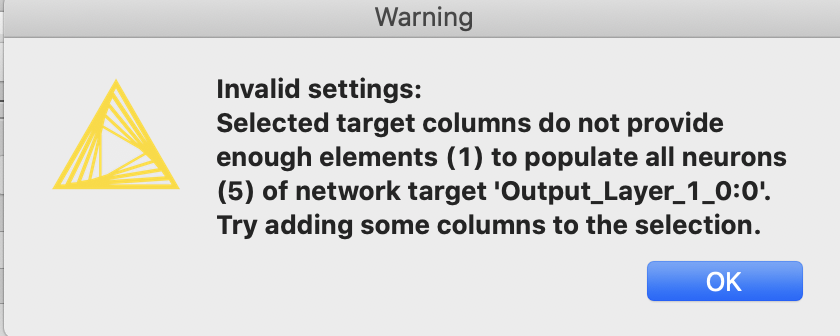
Also would love to your input on how to configure the network without the LSTM node (dense layer only). Seems like I have to make some changes based on this message after deleting the LSTM node:
Did you replace the LSTM layer with a Dense layer or did you just remove it?
You’ll want to replace the LSTM layer with a Dense layer of the same shape.
Although if you move to dynamic forecasting (recursively evaluating your model to evaluate farther into the future) the LSTM layer may still be helpful.
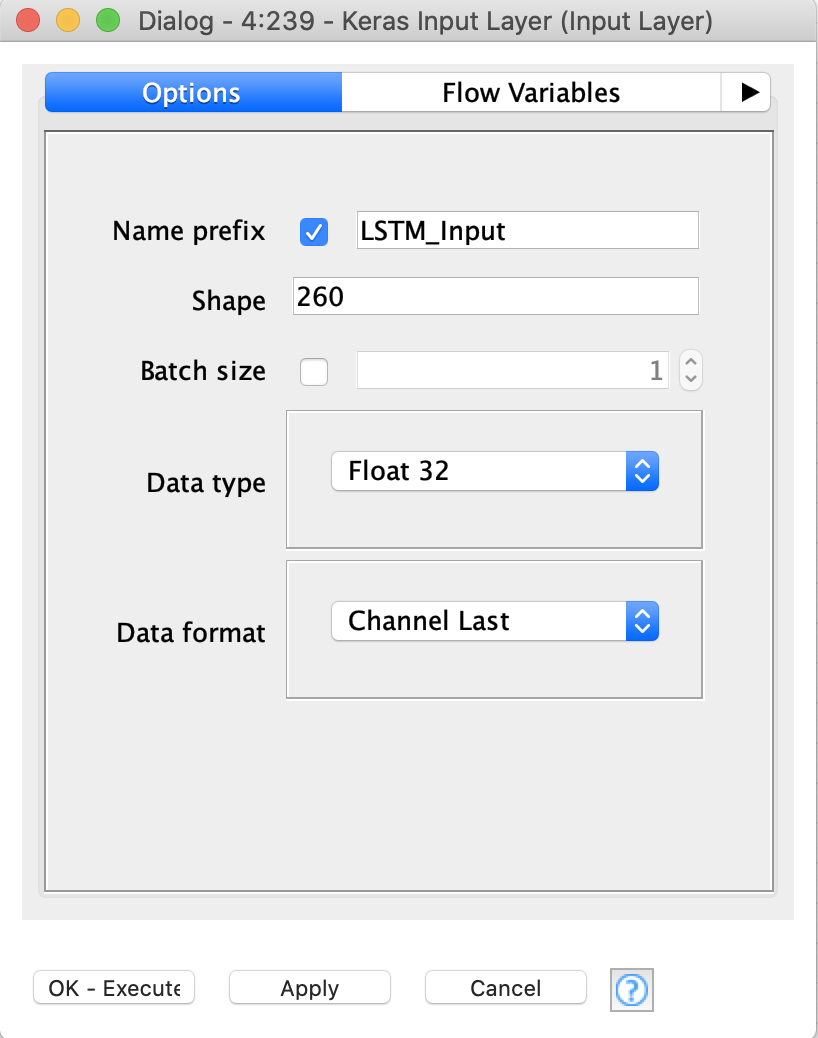
That error is basically saying your Input layer isn’t shaped the same as your input data.
I had removed the LSTM layer and not replaced it with a Dense layer - thanks for the pointer, Corey!
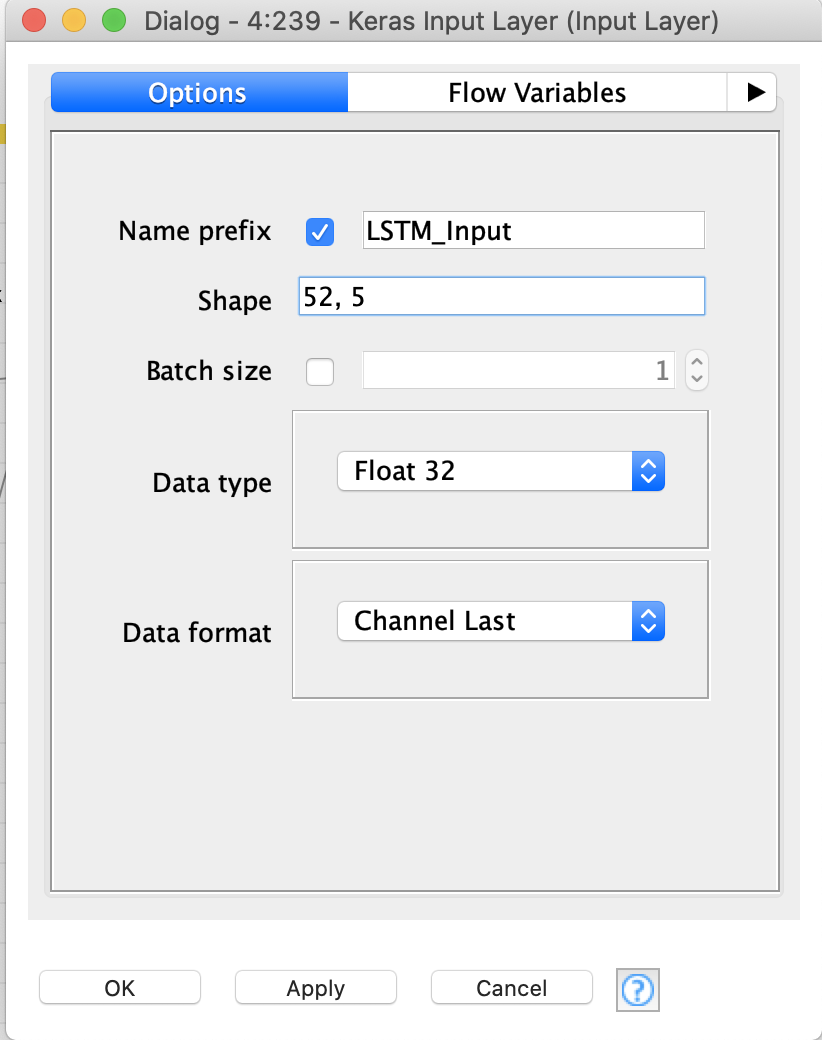
Will also take your input on LSTM’s by including longer lags (52 weeks) and predicting further out (13 weeks).
Have a few more questions for you before I get started:
In the create column collection node, am assuming that columns need to be ordered first by time and then variable, not first by variable and then time, is that correct?
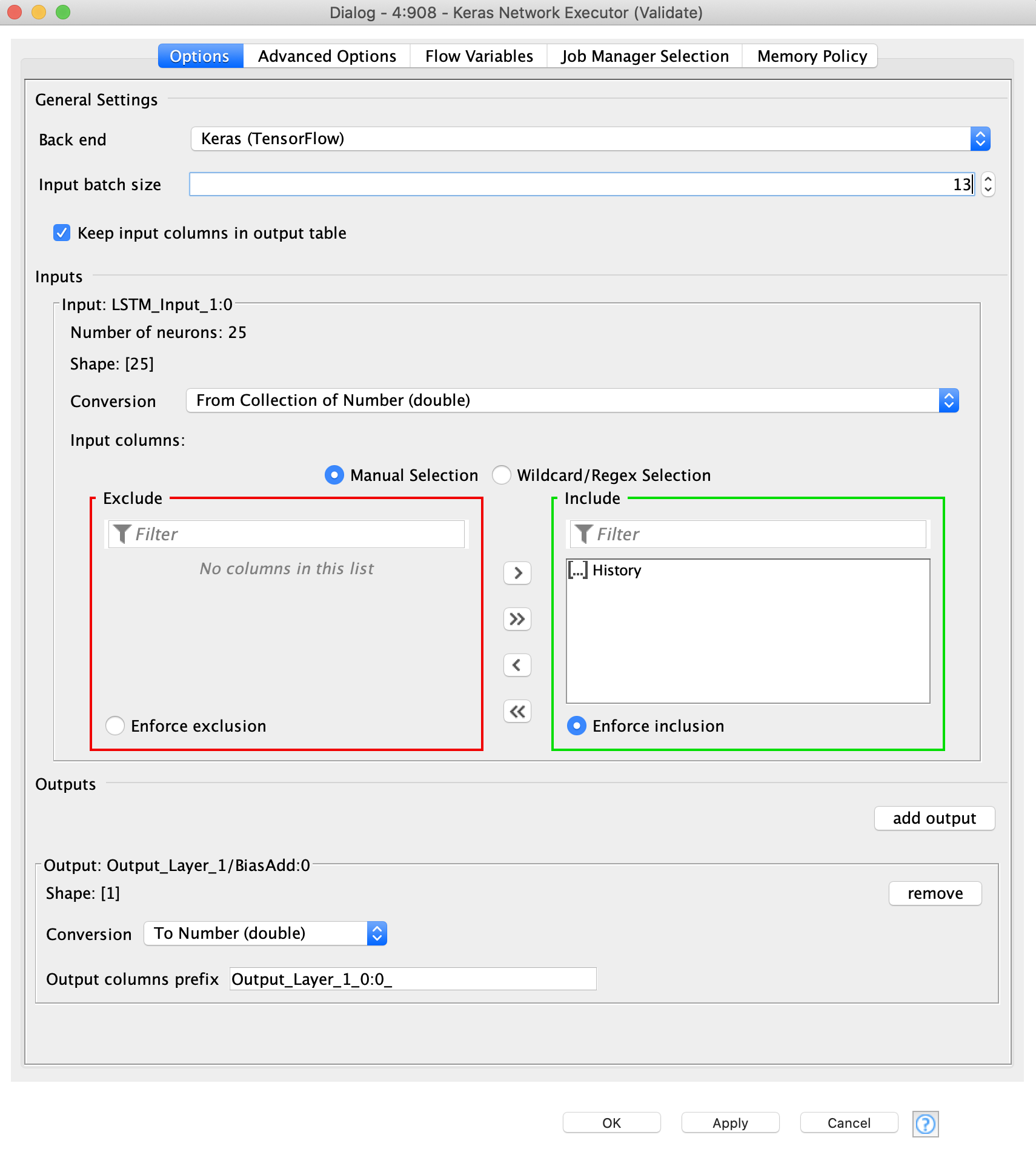
For predicting 13 weeks out, am assuming I should change the training and validation batch size to 13, is that correct? Do the training and validation batch sizes have to be equal?
Since the predictions will be normalized, how do I scale them to real space and evaluate the predictions - do I connect a denormalizer and then a numeric scorer node?
Thanks again, Corey. Will post the updated workflow here.
Oh finally caught me online, can get to this one without making you wait haha.
The order here actually doesn’t matter. In the image below you’ll see some dense layers. Note that after the input every input unit connects to every unit in the second layer. The great (and awful) thing about deep learning is that it learns for itself how your features relate. This is why it is so good at feature extraction but also why it requires so much data.
the input shape can be any combination that matches data you pass in. In your case it would be easiest to make the input 52*5 = [260]. However if you wanted to organize your data by combining the 52 lags into a collection separately for each feature, then further combing those into the 5 by 52 array that would be the 52, 5 input shape here.
Think of units in terms of dimensionality reduction. You’re compressing your feature space into a smaller dimension to, hopefully, learn latent features and train a model that can generalize. This blog post describes the idea in terms of manifolds which I really like: https://colah.github.io/posts/2014-03-NN-Manifolds-Topology/
I wouldn’t adjust the batch size for this reason, but it is something to play with. When training a network you run several “data points” through the model, this is the batch. You then use those to approximate a gradient for the network and update your network weights. Larger batches might create better gradient approximations, smaller ones might allow for more variety in the types of batches the network learns. I doubt it will have a large effect on your performance but can be played with.
For the executor this just determines how many inputs are run through the model at a given time. Changing this lets you leverage a cpu or gpu more effectively during the deployment stage. No impact on the actual values output etc.
The denormalizer is probably the right choice here, if you were using the normalizer node itself the denormalizer can just plug right into it.
As to the batch size, I would just leave the box unchecked in the input layer node. The default value in the options tab of the Keras Network Learner is 100. I’d leave it there for now. Sometimes I make this smaller if I’m using very large inputs (like images).
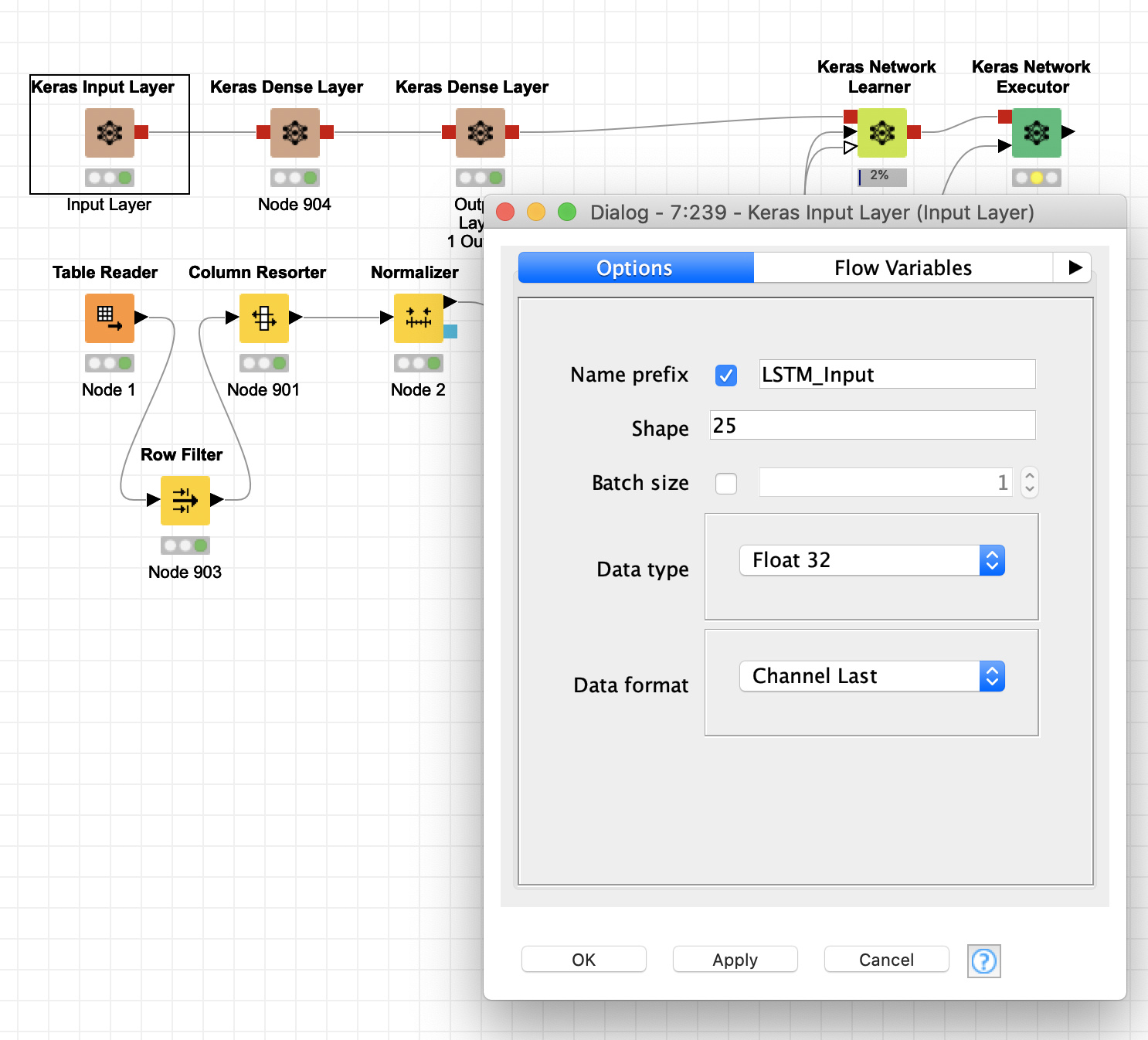
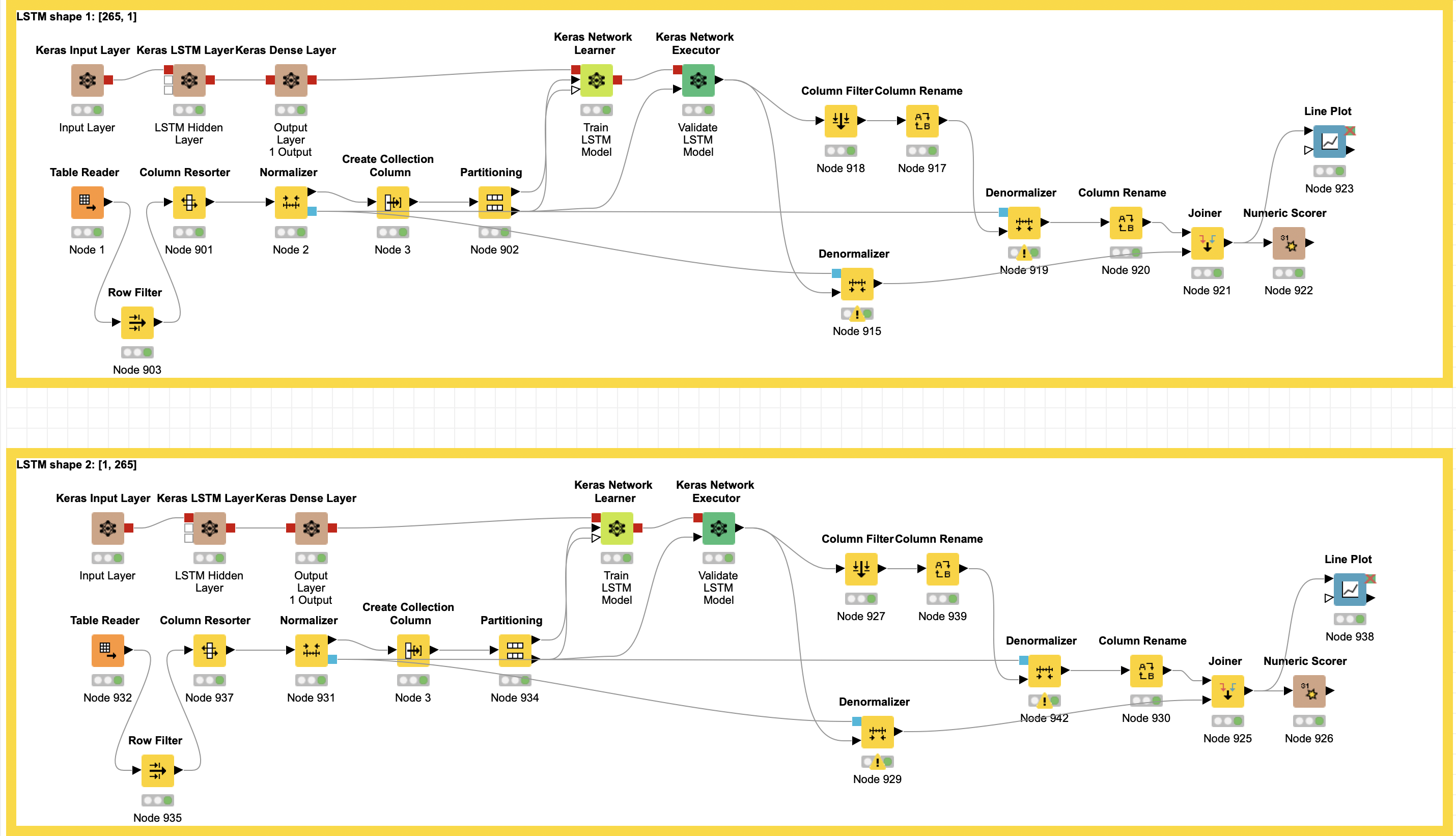
Hi Corey, looks like for the LSTM I have to specify the shape with a comma and since I wasn’t sure, I ran 2 versions - [265, 1] and [1, 265] - not sure if either are correct. In this example, I used 53 lags for each of the 5 features.