Hello,
I am to Machine Learning but I want to explore the possible applications. I have completed L1-DS which also includes a few ML flows.
What I was wondering about: in that course you teach a decision tree to predict a certain outcome based on a dataset in which the outcome has already been given. That makes sense to me, otherwise you can’t train the model.
However, I understand that the added value of ML is that it allows you to map unclassified data. I would like to learn that step. Is that included somewhere in another course or are there additional pages explaining it?
In short, I am quite new to this topic and I am wondering: how do you train a model and then let it work with a new dataset?
Hopefully you can point me in the right direction!
@StefanPlanning a good basic example of a Decision Tree with some description you will find in the Beginners Space of the KNIME Hub:
To score new data you will have to provide the same data with all the columns as before but without the (unknown) target. So for example a collection of customers where you know their ‘features’ but not if they want to buy something.
If you want to learn more about machine learning and KNIME I have collected these hints and links:
@mlauber71 Thanks a lot! That is more than enough material to continue the selfstudy
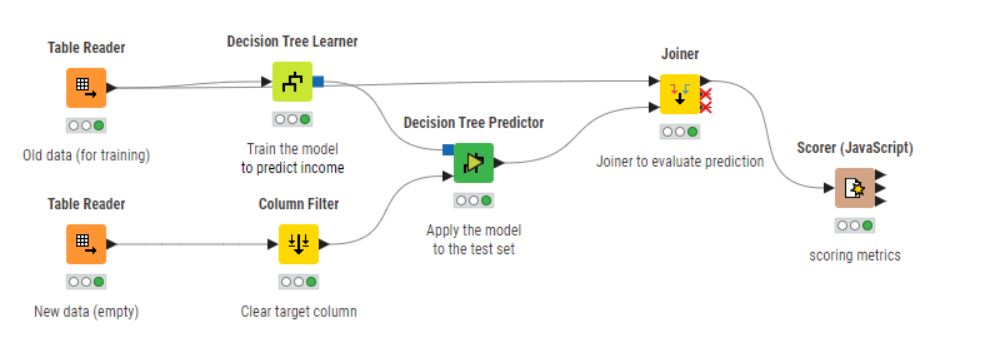
Just to make sure I am thinking in the right direction… Below I changed the solution from the Basic Course into something that could be suitable for our situation.
In reality it is a direct copy but what I try to illustrate is that we have a training set (with actual outcomes) and a new dataset for which we want a prediction. It is oversimplified, but it this a flow that represents this kind of use case?
After the prediction I add a joiner so the scorer can evaluate the decision tree.
@StefanPlanning if you want to explore the new data you would have to provide the truth for them in order to see how a model would perform. Typically you would set aside a portion of the training data in order to see if the model can make sense for your existing data already. There are other techniques to make a model more stable.
When you have data stretching a long time back and you expect a very robust scenario you can use data from one period (Month, year) as training and another month or year as Test to get a stability.
I would recommend taking more courses and reading about the basics of machine learning.