Hi all,
first time here writing an topic…, let it be please a positive experience and bare with me
I see a lot of ML examples with one or multiples predictors (input data or the variables) to a target variable. However, such examples are always with singular values or classification.
In simple terms, each target value is correlated to one singular predictor value. See following example:
Event case | Predictor1 | Predictor2 | PredictorX | Target | Classification
A | 1 | 2 | 50 | 1 | ok
B | 3 | 2 | 6 | 2 | Nok
C | 3 | 1 | 5 | -1 | ok
…
Can some one please give me a hint where I can find some examples where the a prediction to target can be calculated from a “list” of values in each predicator to each individual case?
Event case | Predictor1 | … | Target | Classification
A | [0,1,2,…] | … | 1 | ok
B | [0,1,2,…] | … | 2 | Nok
C | [0,1,2,…] | … | -1 | ok
…
The background idea here is to use a whole data from a sensor measuring the state of each “Event case” along an defined time.
In the past i used a feature extraction of this data list (time series–> FFT) to generate a singular predictor value, but i wonder if I cannot avoid it and use the whole signal as input information to the machine learner.
I guess that image processing/classification has some similarities here…anyway, thanks in advance for any support.
Hi @adwilbert & welcome to the KNIME community forum
Some Machine Learning nodes in KNIME directly accept either fingerprints, Bit Vectors and Byte Vectors which are a kind of List data type in KNIME.
For instance, Random Forest, Tree Ensemble & Gradient Boosted nodes do. This is not however a feature that is implemented in all the KNIME ML learner nodes.
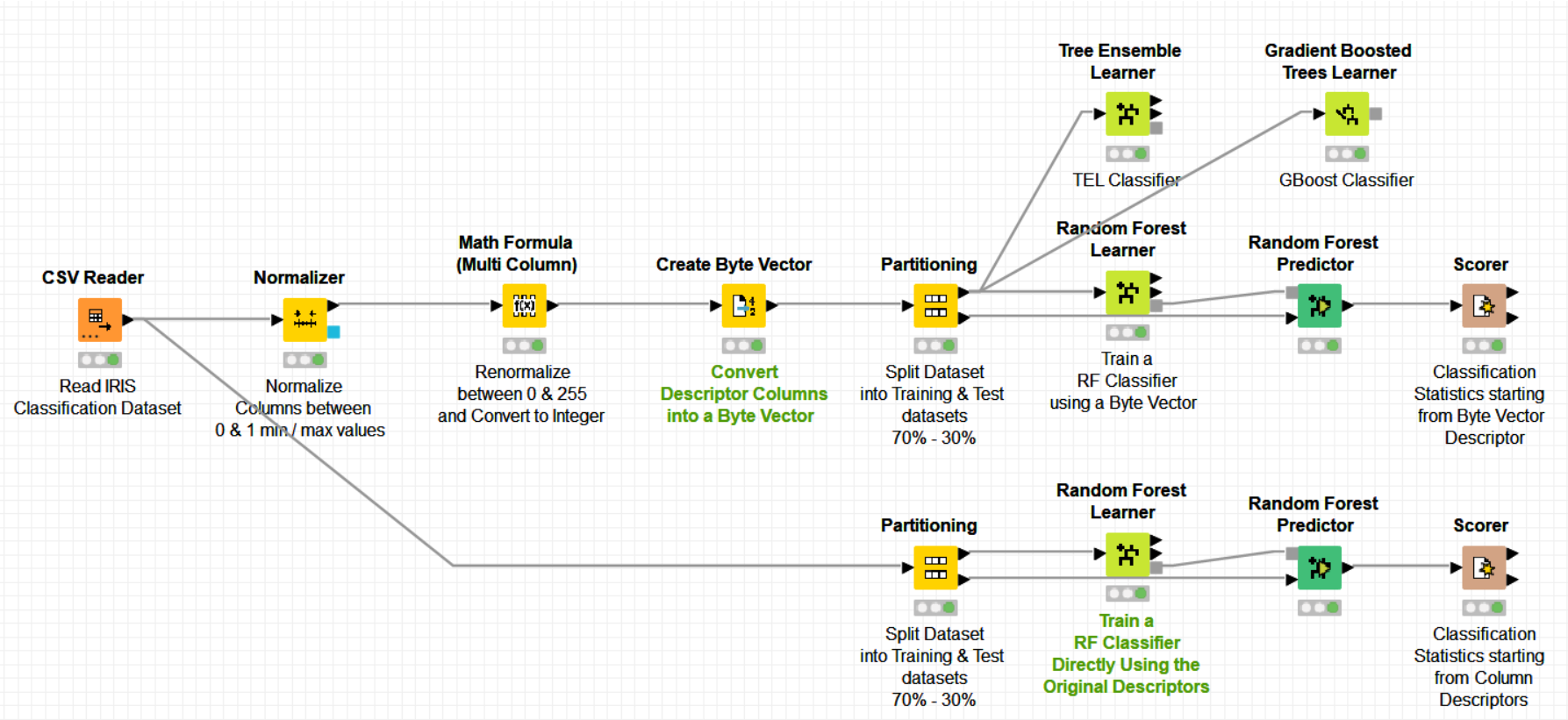
In your case, the values in the list seem to be integers. If the number of total values does not go beyond 256 (coded or renormalized from 0 to 255) then you could convert your columns into a “Byte Vector type” using the -Create Byte Vector- node (mind this is a special list type in KNIME and not exactly of type List) and then use it as input data for your classification learner.
Please find below an example where I’m converting 4 column descriptors into a Byte Vector of 4 values normalized between values 0 & 255:
Hello @aworker thanks for the hint,
I tried your suggestions and I learned new things with that.
The approach with the Byte Vector seems nice, but will not do for me due to the restriction with the total amount of 256 values. And no, the values are not integers, but Number (double).
So, I followed the additional approach path directly partitioning the data. Before partitioning it, I used the node “Split Collection Column” to split the list values in several columns and later even add other predicators to each individual row (EventCase, from my question), which have an already known classification (ok and Nok).
Unfortunately the resulted Confusion Matrix from the node “Scorer” was not good. It classified all known “Nok” event cases wrong. But I think that the problem comes from the actual unbalanced number of “ok” and “Nok” event cases.
I will try to write back in the future if something changes.
Thanks again for the assistance.
Although my workflow example is transforming doubles to integers within the 0-255 range, I understand that most probably, this is not a convenient solution if the resolution of your sampled signal from sensors is higher than one byte (which most probably it is from the A/D signal transducer).
Imbalance data is often a real issue in classification so I understand that this may be affecting the quality of your classification model too. There are quite a few solutions in the KNIME HUB, forum or blog for data balancing before doing classification if this may help in your case. For instance:
Please just let us know if you need any extra hints on that or further help.