There have been a number of posts on the forum regarding reading XML files. I think reading XML is one aspect of KNIME where I don’t feel it is quite as easy as it ought to be. To be fair, the reading of XML is simple (you just load it with an XML Reader) but it’s what you do with it after that that presents the challenges.
The XPath node is very capable but in my view is fine for a handful of columns, but just doesn’t scale well (in practical/human terms). Maybe I just get bored too easily. Doubtless it’s a clever node, it’s handling of XPath is I’m sure wonderful, but I’ll never really appreciate it because if I have a large XML file to be read, I will lose interest in trying to configure every Xpath long before my coffee has gone cold!
Turning to JSON to do the job just doesn’t do it for me, especially as I still then have to overcome the issue of handling those many-to-one relationships that I would like to easily break out into separate tables.
Ultimately, for the average person who just wants to read a very basic XML file in and get on with the actual job of analysing the data, it should be (almost) as straightforward as loading a CSV file.
Now, I accept that XML files and tables don’t make easy friends under all circumstances, but after seeing a few recent forum posts, it got me wondering why should it be any more difficult to load an XML file into KNIME than it is to load it into Excel? Why do we need to resort to “convert to JSON” and back again in what I would suggest is not-particularly friendly or intuitive process. If my XML has 5 columns, why do I need to spell out the XPaths? Yes, why? 
So over the past week or so, I’ve been looking through the forum, seeing what other people have suggested over the recent months, and years. Ultimately to do anything programmatically with the XPath Node is I feel a non-starter. If it allowed me to pass in the XPath info as arrays, then maybe it could work (and I’ve looked at some interesting and useful posts on the subject) , but as it stands, you are swimming upstream the entire way and even then you have no guarantee of success - and its a lot of nodes, and it’s just not generic!
So what are the other options if not the standard nodes? Well… I thought…would it be possible to write a component to do it? Why not… we’ve got Python… so the day before yesterday, and yesterday, and today… I’ve been researching… and writing… and testing… 
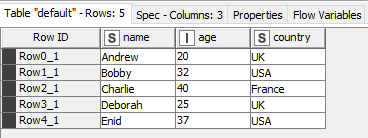
Let’s say we had a piece of XML, that looked like this?

Wouldn’t it be great if (with approximately zero configuration) it turned into this:
or if this:

turned into this:
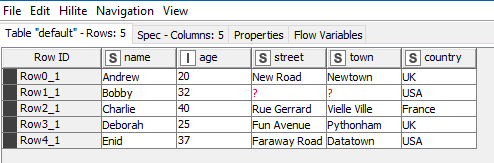
or if, with only a minor piece of configuration
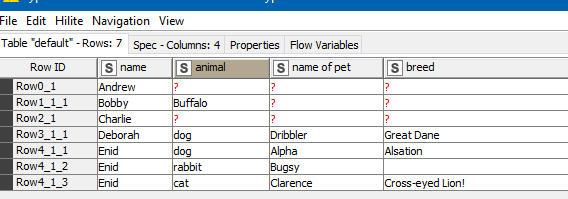
this piece of xml: demo5.xml (1.4 KB)
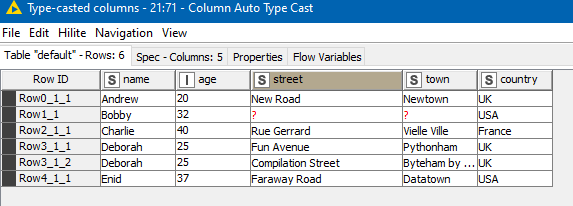
which contains two nested many-to-one data structures (addresses, and pets) which don’t lend themselves to being in a single table without creating repeating groups, could be turned into
this:
and this:
Well… that’s what my new toy does ;-), and if you’d like to try it out for yourself (and have fun with XML again…  ) you can.
) you can.
I’ve uploaded a demo workflow here:
and the XML Easy Reader 1 (prototype version 1!) can be downloaded from here:
I’d welcome feedback and obviously it’s still early days so if you find any bugs please let me know. There are some config options - see the documentation on the component, but if it’s not clear how to make it work, please let me know. Doubtless there are situations I’ve not yet considered but my hope is that it works really easily for basic (row-column style) XML, but also allows me/you to work more easily with reading more complex structures without lots of configuration. Enjoy!
 ), but the python code itself is reasonably small and the ideas ought to be reasonably easy to port to Java. I’ve yet to look at writing an actual node for KNIME. I decided to wait until the next release of KNIME before I download the sdk and have a play. I’m more a java programmer than a python one, so I guess it should really be my next step, but I find that prototyping an idea in Python to be really easy with KNIME.
), but the python code itself is reasonably small and the ideas ought to be reasonably easy to port to Java. I’ve yet to look at writing an actual node for KNIME. I decided to wait until the next release of KNIME before I download the sdk and have a play. I’m more a java programmer than a python one, so I guess it should really be my next step, but I find that prototyping an idea in Python to be really easy with KNIME.

