Is there a way to manipulate all cells in a dataset without considering columns
Example: “fully agree”–>1, “agree”-> 2 …I have only discovered the rule node, but where you have to work column by column.
Is there a way to manipulate all cells in a dataset without considering columns
Example: “fully agree”–>1, “agree”-> 2 …I have only discovered the rule node, but where you have to work column by column.
Welcome to the forum, @wkoenig.
For this, I’d use a column list loop to loop over all columns one by one. Inside the loop, I’d use a Rule Engine node but instead of specifying a column name to manipulate, I’d use the currentColumnName flow variable.
Thanx, may you refer to an example workflow?
Hi @wkoenig and welcome to the Knime Community.
You should try what @elsamuel has mentioned, that would be a good way to do this. It’ll also be an excellent way to learn it.
Which part of the instructions are you struggling with?
Also, if you want an example workflow, please provide some sample data to work with.
You could also use a python snippet and replace with a dictionary
br
Dear @elsamuel & @bruno29a,
thank you very much for your feedback. As I am a complete newbie and so far not at all familiar with the configuration of “flow variable” or loops, I would be very grateful if I could view a workflow to follow along. Attached is a sample dataset. I would be very happy if I could learn from you guys. Thanks ![]()
example-Data.txt (677 Bytes)
Hello @wkoenig,
I would use Unpivot, apply logic (Rule Engine in this case), Pivot approach. See here workflow example:
To learn more about looping over list of columns see this example:
Welcome to KNIME Community!
Br,
Ivan
Hi @wkoenig , thank you for the data sample.
It’s great that you are willing to learn. The first thing you should know is that there are more than 1 way of reaching the same data results in Knime, as you can see already, you are presented with different directions, all of which are valid, so if you are willing to learn, you should explore them all.
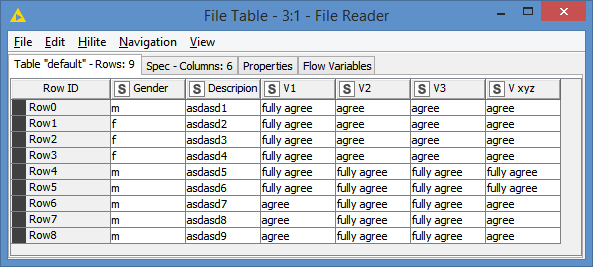
On my side, seeing how your data is, I’m going with a String Manipulation to do a replace, and I’m going to use the Multi Column version as it would allow me to manipulate the strings in multiple columns at once and within 1 node.
First of all, your input file was not 100% clean:
I fixed these to start with.
Here’s what my workflow looks like:
Input data (from the clean file):
Results:
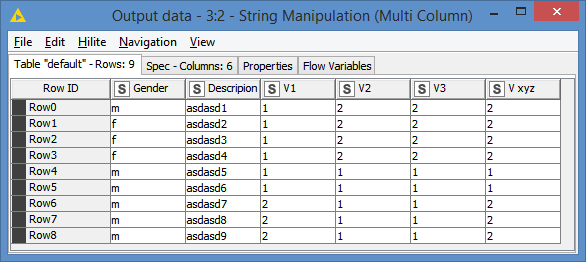
The important thing here is to first replace “fully agree” by 1, and then replace “agree” by 2. If I do it in the other order, the “fully agree” will be changed to “fully 2” and I will then not be able to find any “fully agree”.
So, the order of the replace matters. Do you “fully agree” with this? 
Here’s the workflow: Manipulate all cells in a dataset.knwf (9.0 KB)
Again, if you really want to learn, you can try doing this in loops, @ipazin has provided useful demos to help.
Hello @bruno29a,
thank you very much for the support. I tried to customize the node to add a new operation,
This is what the code looks like now:
replace(replace(replace($$CURRENTCOLUMN$$
, “fully agree”, “1”)
, “do not agree”, “3”)
, “agree”, “2”)
→ Is it correct that for each further replacement a "(replace " comes in front of the parenthesis?
If I want to replace all quotes in the record, how do I do it with this node?
In any case, thanks a lot and I have already learned a little bit
Hi @wkoenig , no problem.
1). Is it correct that for each further replacement a "(replace " comes in front of the parenthesis?
Yes, that is correct. It’s just the way I write it so that we can see what’s being replaced and by what.
It’s really just this replace(replace(replace($$CURRENTCOLUMN$$, "fully agree", "1"), "do not agree", "3"), "agree", "2"), but as you can see, it’s not obvious what’s being replaced with what.
But if you look at it in this format, if you need to add more replace statement, you would basically add these: replace( replace(replace(replace($$CURRENTCOLUMN$$, "fully agree", "1"), "do not agree", "3"), "agree", "2") , “”, “”) so, you can see the pattern there.
2). If I want to replace all quotes in the record, how do I do it with this node?
Since quotes are used to delimit a string, you have to simply escape the quotes if it’s part of the string like this \". So, in a replace function, it would look like this:
replace($$CURRENTCOLUMN$$, "\"", "")
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.