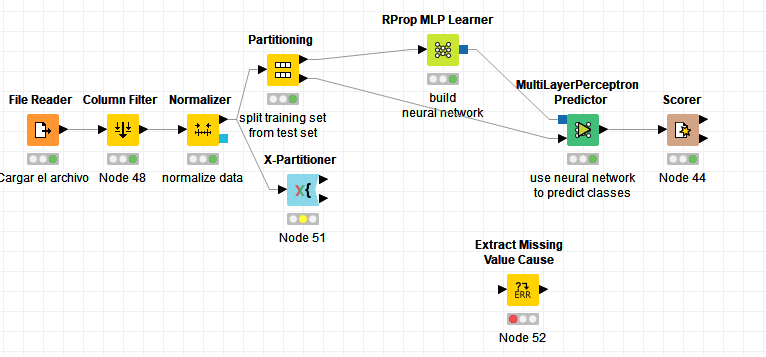
Hi! I’m developing a model who classify a lot of data between at least 220 categories. But don’t find the way to work the model out(I think because there´re a lot of categories). I’m basically doing my first steps in ML models, so if there´s someone who knows a better ways to solve the problem I’ll be pleasant to work on it.
Every row of my DB represent the main characteristics of a single and unique car. My main goal is to make a model to predict the “GRUPO” and as you can note, there are as many groups as cars brands and models. The “GRUPO” can be predicted easelly querying DB but I have 1.2 M records per year.
Thus, What i’m doing is jointing the strings variables and counting the quantity of each letter. I’m using just these and some numerical variables to build my model. I can explain why i’m doing the joint but i don’t want to lose the focus.
OK, tell me if I am wrong but the class you are trying to predict is the combination of car brand and model, right?
Since you are saying that it is easily possible to formulate DB queries for the individual groups, I would assume that each group can be identified by a relatively simple rule.
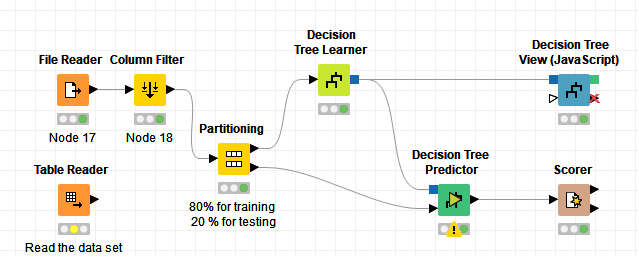
Hence I would suggest to train a decision tree for your classification task.
Decision trees are well suited for this kind of task, and you won’t have to do any complicated feature engineering for your string variables, as decision trees unlike neural networks can deal with categorical values.
Should a simple decision tree not suffice, you could turn towards more complex decision tree based models like Random Forests.
not to dampen your excitement but this result looks a bit too good to be true…
Are you certain that you are testing the accuracy with an independent dataset, i.e. not the table you trained on?
This is not meant as an insult to you but this is the kind of mistake that happens, and I would rather you find it now than later when you present your results (believe me that isn’t much fun).
If you like, you can post a screenshot of your workflow (similar to your first post) and I can tell you if everything makes sense at least from the nodes involved and their order.
You’re right, my results were very good just for 20k raws and skipped 80k. I have 1.2 M but, is a good star! I had not had any result from more than 6 categories before and that’s the real problem to me thus there´re over 13000 categories.