Could you please advise - what would be the best way to achieve that:
I have 2 data sets with points
I have to find a pair for each point from 1st in 2nd
If a point in 2nd data set is found - I would like to exclude it from scan for every next point from 1st data set. Kind of re-send new data set to internal loop
At the end - I would like to have all points that are matching and all points that are not matching in one table
Tried to use:
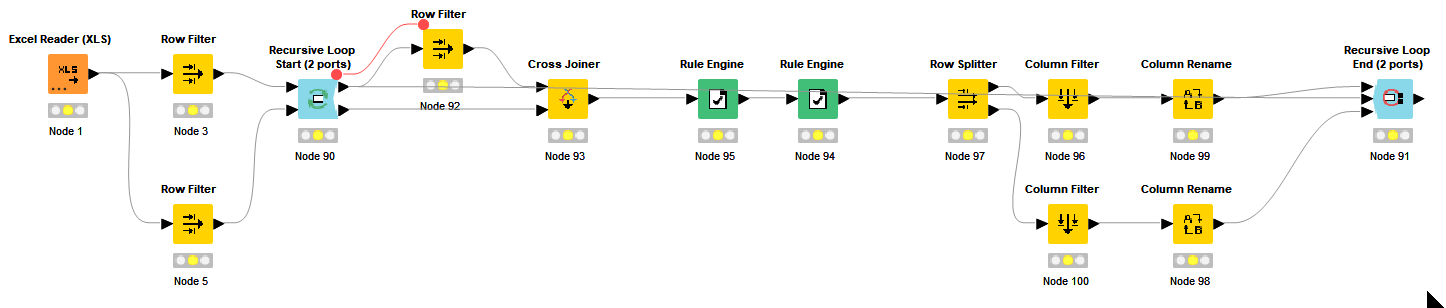
Recursive Loop - the issue is I have to re-run all not matching points after finishing the run of internal loop and send it back to internal loop, but as I’m processing record by record they are not collected. Seems I would need an another internal loop which takes the results of first internal loop and recursive them back to initial internal loop. Too complicated?
Loop end (2 Ports) - Not sure how can I return back collected records to Chunk Loop Start after the run in internal loop
I thought to remember the not matching ids and send them back to update a variable - but not sure how to achieve it. Like Merge Variable or use of Table Row to Variable?
And a huge ask to explain that moment for nested loops:
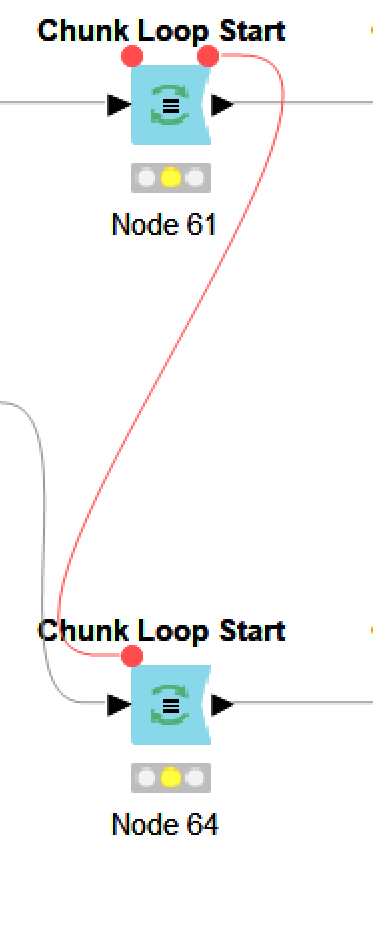
Why do I need to connect variables between nested loops to make it works? I’ve red couple of forum posts but still confused with that scenario.
Without it my Column Appender shows the error: “Can’t Merge FlowVaAriable Stacks! (likely a loop problem)?”
And in Console I can see that: “Unable to merge flow object stacks: Conflicting FlowObjects: <Loop Context (Head 0:61, Tail unassigned)> - iteration 0 vs. <Loop Context (Head 0:64, Tail unassigned)> - iteration 0 (loops/scopes not properly nested?)”
@larine One idea could be to store the results at the end of a loop in a CSV file (append) and reload the file at the start of each loop - use that file to exclude matches already used.
Outside each inner loop you would have to reset (delete) the csv
My goal would be collect somehow all not matching dots after each run of internal loop and pass it back to external loop, reducing the number of comparisons.
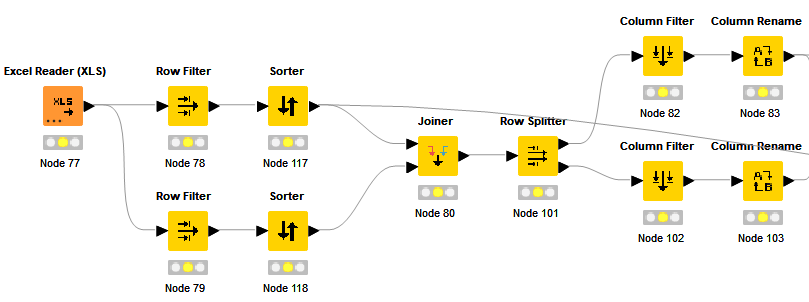
Yes. Join is already known path. I agree.
But I thought to do it via loops instead as I have to learn them. My next steps will require loop usage again.
Actually, using Row Filters you can see that I’ splitting my data into 2 different years.
The result is something that we can achieve via different ways - reorder points and find new neighbours between 2 shape files while do the polygon (actually, polygon border) morphing between years.
So far we can achieve first step in the exercise via:
Join by lon/lat fields
Saving data into a temp file and then read it each new iteration for inner loop
Right now - I’m looking for a solution to optimise matching loop. And learn loops in KNIME:
Instead of sending whole bottom (2nd) table to find a matching pair - exclude matched points from 2nd table for each next iteration while seeking a pair for a point from top (1st) table.
Hope that makes more sense.
Reg loop variables
I see. If it is only one reason - to tell KNIME the order of loop start nodes - I will save it to my mind like that Thanks again!
Regarding your workflow. To achieve what you are trying you would need to use recursive loop with two input ports where from table 1 you always grab first row and from table 2 entire table, then do matching and after matching update both tables and feed to recursive loop end with 3 ports. Considering you are learning give it a go and if any questions feel free to ask.
Regarding learning loops here is link for Lesson 4 of Advanced Course for Data Wranglers:
Regarding loops in general. Although they have been improved in terms of execution loop solutions are by no means comparable to loopless solution so I try to avoid them.
Thanks for link to lessons - did all of them before hitting the forum.
Now, with more practise - I have better understanding of loops and can easier utilise them for my next steps.
I can say that JOIN solution is much easier and shorter @Luca_Italy - it works like a charm
flow variables are available to all downstream nodes regardless of connection type (meaning you don’t need flow variable connection between loop start node an Row Filter node)
give new joiner a try Joiner (Labs) (should be faster)

 Thanks again!
Thanks again!