Hi @nightsky3 , since you are not just checking columns, but rows also this is better done via a Join, and best done via a Group By.
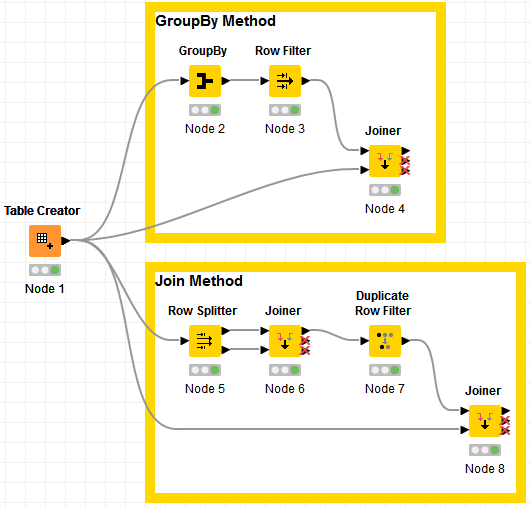
I created a workflow that does both methods and looks like this:
Both gives the same results, but the GroupBy is much more faster.
Explanation as follows.
GroupBy Method:
The idea here is to do a Group By Country and Crash Cause and just do a unique count on Transport. If the unique count is greater than 1, it means you have both Car and Bus as Transport for the same Country and same Crash Cause:
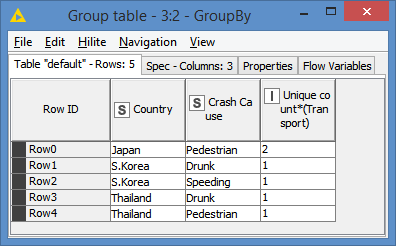
And since it is what we want, just need to filter on those that have unique count 2 via a Row Filter:
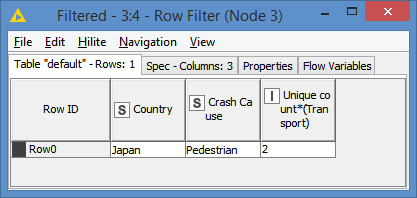
Then just join back with the original data, on Country and Crash Cause, and we get:

Join Method:
As with the GroupBy, we want to check which Country and Crash Cause combination have both Car and Bus as Transport. We just Split via the Row Splitter the data into 2 tables, one for Car records and one for Bus records:
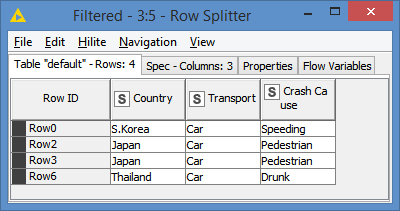
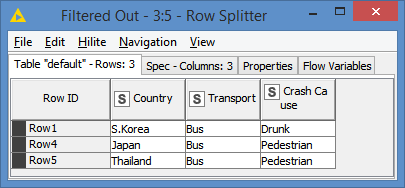
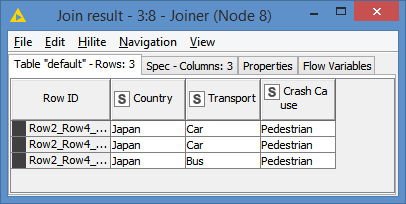
We then join both tables on Country and Crash Cause. Whatever results we get will be the Country and Crash Cause that have both Car and Bus as Transport:

If you compare with the GroupBy Results, that’s what we got there too (2 x {Japan + Pedestrian}).
We do a de-duplication, as we just want to know that it’s Japan and Pedestrian.
After that, we just join back with the original data on Country and Crash Cause, as we did in the Group By method, and we get the same results:
Here’s the workflow: Match with items in a list between columns.knwf (21.8 KB)