Hello everyone,
Thank you ahead of time for your patients. I am slowly getting a better at understanding of what Knime is capable of processing.
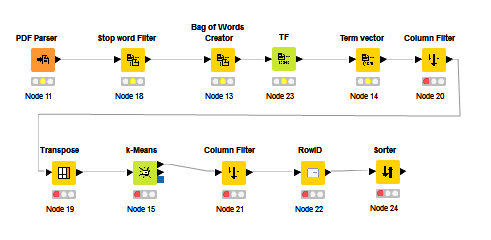
Is there a work flow out there that is similar to one that will generate and compile a list of correlating PDF’s? In other words, a workflow that can compare two PDFs and distinguishes if there is a high correlation between the two. I am currently opening a bunch PDFs in Spanish and then translating them only to find that I am consistently copying over the same text from multiple file PDFs that are only formatted different. I dealing with alot of messy information documented in PDFs and thes PDFs must have been translated and copied over multiple times in the PDF’s lifetime. Ideally, The system would need to loop so I would be comparing 50 or so documents. I know this isnt a simple workflow but I’m trying to figure out where to start. I’ve watched multiple videos on youtube and scrolled through this form. Please tag any previous discussions in here that could possible help me generate some ideas. Anything will be much appreciated.
Thank you
Michael
Graduate Student