Hi,
I want to “match” two column based on numbers, create new column with those matching True and those not matching is False for example, two column are “Node id” and “IDs”
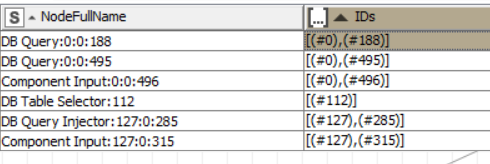
Node id IDs Matching
DB Query:0:0:188 [(#0), (#188)] for eg, here 0 0 188 are matched so its True
DB Query:197:0:122 [(#197), (#0), (#135)] here 197 0 135 not matched so its False
I want to write query in Column Expression or Rule Engine, can anybody help ?
Hello @Muhammad44 and Welcome to the KNIME community!
This looks doable with a Rule Engine, but I’m not sure where one column ends and the next one starts. Can you please post this sample input again, but with separators? Since it’s just two lines, a screenshot would probably be fine as well in this case
Thank you Thyme,
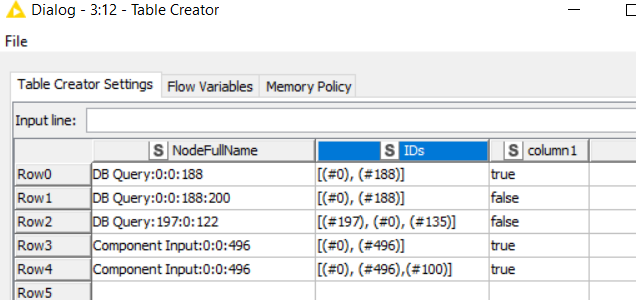
Its something like this, these are the two column here NodeFullName and Ids in the picture.
If its possible could you please write the query then for me in Rule Engine and make a new column with True and False. In this picture all should be True but if its not matching its False
hi @Muhammad44 ,
maybe this Column Expression can help. I assume IDs are collections of length n>=1
NFNs = split(column("NodeFullName"),":")
result = true
for (i=0;i<arrayLength(column("IDs"));i++) {
if(column("IDs")[i]) {
id = regexReplace(column("IDs")[i],"^.*?(\\d+).*","$1")
result = and(result, arrayContains(NFNs,id))
}
}
result
NFNs = column("NodeFullName")+":"
result = true
for (i=0;i<arrayLength(column("IDs"));i++) {
if(column("IDs")[i]) {
id = regexReplace(column("IDs")[i],"^.*?(\\d+).*$","^.*:$1:.*\\$")
result = and(result, regexMatcher(NFNs,id ))
}
}
result
Hi @duristef@Muhammad44 , just an advice when doing for loops. While it is quite common that programmers usually write for loops as @duristef did, it’s better to evaluate the expression arrayLength(column("IDs")) outside of the loop.
For example:
array_length = arrayLength(column("IDs"))
for (i=0;i<array_length;i++)
What happens in my case is that the expression arrayLength(column("IDs")) will be executed only once, as opposed to each time that the for loop will execute. This value does not change, so it is inefficient to execute it in each iteration of the for loop. It only needs to be executed once.
@bruno29a , you’re absolutely right, the loop can be optimized:
NFNs = split(column("NodeFullName"),":")
for (i=0, result = true, last=arrayLength(column("IDs")); i<last; i++) {
if(column("IDs")[i]) {
id = regexReplace(column("IDs")[i],"^.*?(\\d+).*","$1")
result = and(result, arrayContains(NFNs,id))
}
}
result
The regex, too, can be modified so that there’s no need to add a “:” to column(“NodeFullName”)
for (i=0, result = true, last=arrayLength(column("IDs")); i<last; i++) {
if(column("IDs")[i]) {
id = regexReplace(column("IDs")[i],"^.*?(\\d+).*$","^.*:$1(:.+\\$|\\$)")
result = and(result, regexMatcher(column("NodeFullName"),id ))
}
}
result
Maybe even better is a “while” loop, because it breaks as soon as a non-matching string is met, avoiding useless checks :
result = true, i = 0, last = arrayLength(column("IDs"))
while (result && i<last) {
if(column("IDs")[i]) {
id = regexReplace(column("IDs")[i],"^.*?(\\d+).*$","^.*:$1(:.+\\$|\\$)")
result = and(result, regexMatcher(column("NodeFullName"),id ))
}
i++
}
result
@bruno29a I am amazed to see that, this is what Knime really is, and great to have another solution which already said so → without expression and loops. Interesting and Brilliant analysis.
@duristef thanks for another soln. Its getting more interesting, I followed your approach too which you wrote in Rule Engine, that you combine both syntax query but having pbs with that as because I am not very familiar of javascript. When I saw yours , I was like ahh thats where I was doing wrong. but big thanks to you guys.
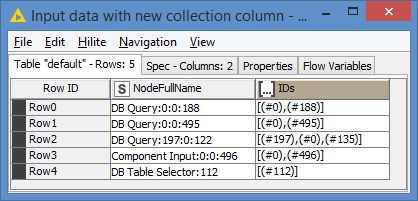
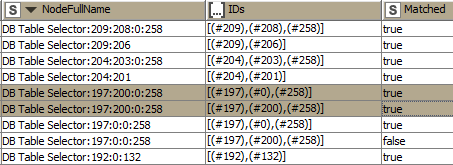
@duristef , there is one problem with your code that I attached the picture, with highlighted ones “one is correct which is True but the other one is not correct, it should be false” as its not showing false.
@yes sure, the thing is that those who are not matched should be false or else true.
So here 197 200 258 matches with IDs column i.e. with this one #197#0#258 but
another one is not matching there is
197 200 258 where as in ID column it is 197 0 258 (no 200 in it ) so if its not matching then it should be false instead of true. thats what I meant
I still don’t get it: in both the rows you highlighted the NodeFullName is DB Table Selector:197:200:0:258. This NodeFullName matches with both[(#197),(#0),(#258)]and[(#197),(#200),(#258)], so Matched=true in both cases
you have to match by row to row. you mentioned right one row IDs matching with Node Full name which is true. The other one is not matching so it should be false. instead of true.
There are two highlighted. So the second one is matching so it should be true
the first one is not matching so it should be false (but its written true) which is wrong
I don’t understand it either. I suspected it has to to with missing IDs in the collection, but there several rows (1, 3, 5, 6, 7, 8, 9) where that’s the case, in fact most of them.
Since there’re multiple people that don’t see the pattern, maybe you can tell us more about what you’re trying to accomplish?
Also, which one of the proposed solutions are you refering to? Are all three of them showing the same behaviour or does one of them get it right?
Maybe we’ve read the whole problem in the wrong direction: row match when the numbers > 0 in the NodeFullName column (i.e. 197,200,258) are present in the IDs column, not the other way round. If this is the case, the results in this table would be correct. @Muhammad44 do you confirm it?
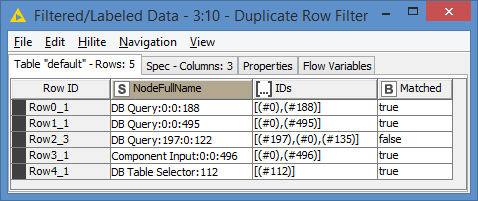
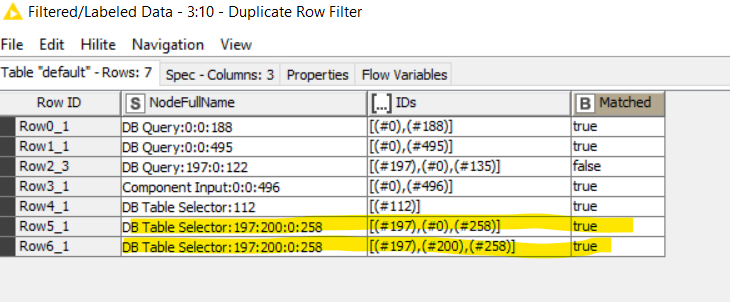
@duristef the second picture all are correct, except the Row4.
because
NFN is 0 0 496 and IDs is 0 496 100 ( it shows true , it should show FALSE, because 100 is not in NFN).
Other than this, all T/F are correct.
p.s all number fron NFN should match IDs column (that is what I was looking for) and dont bother about 0s.