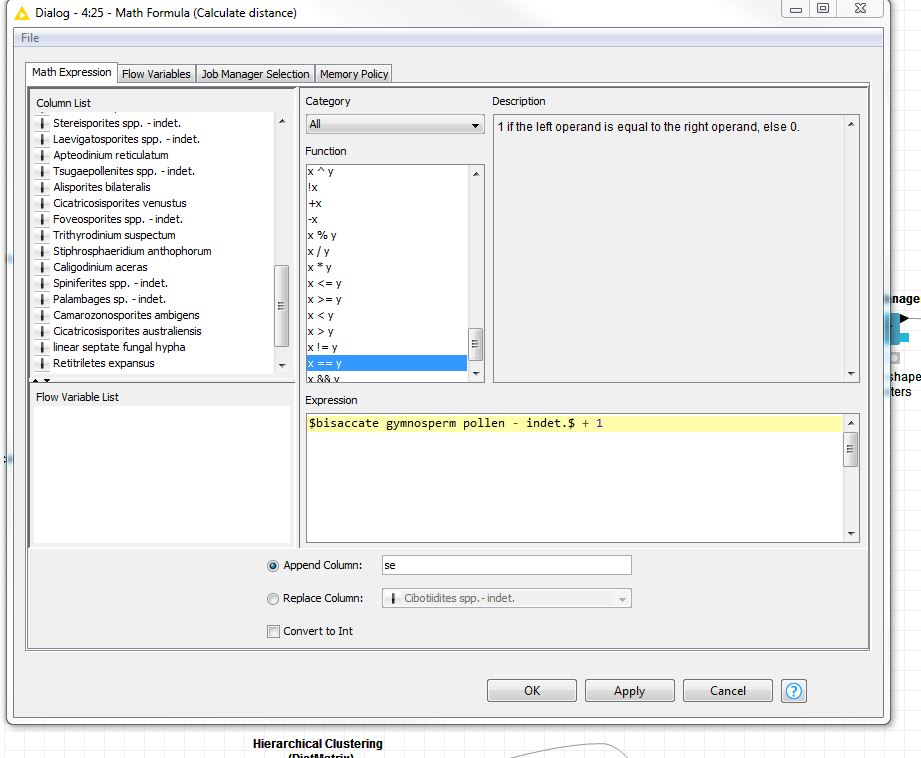
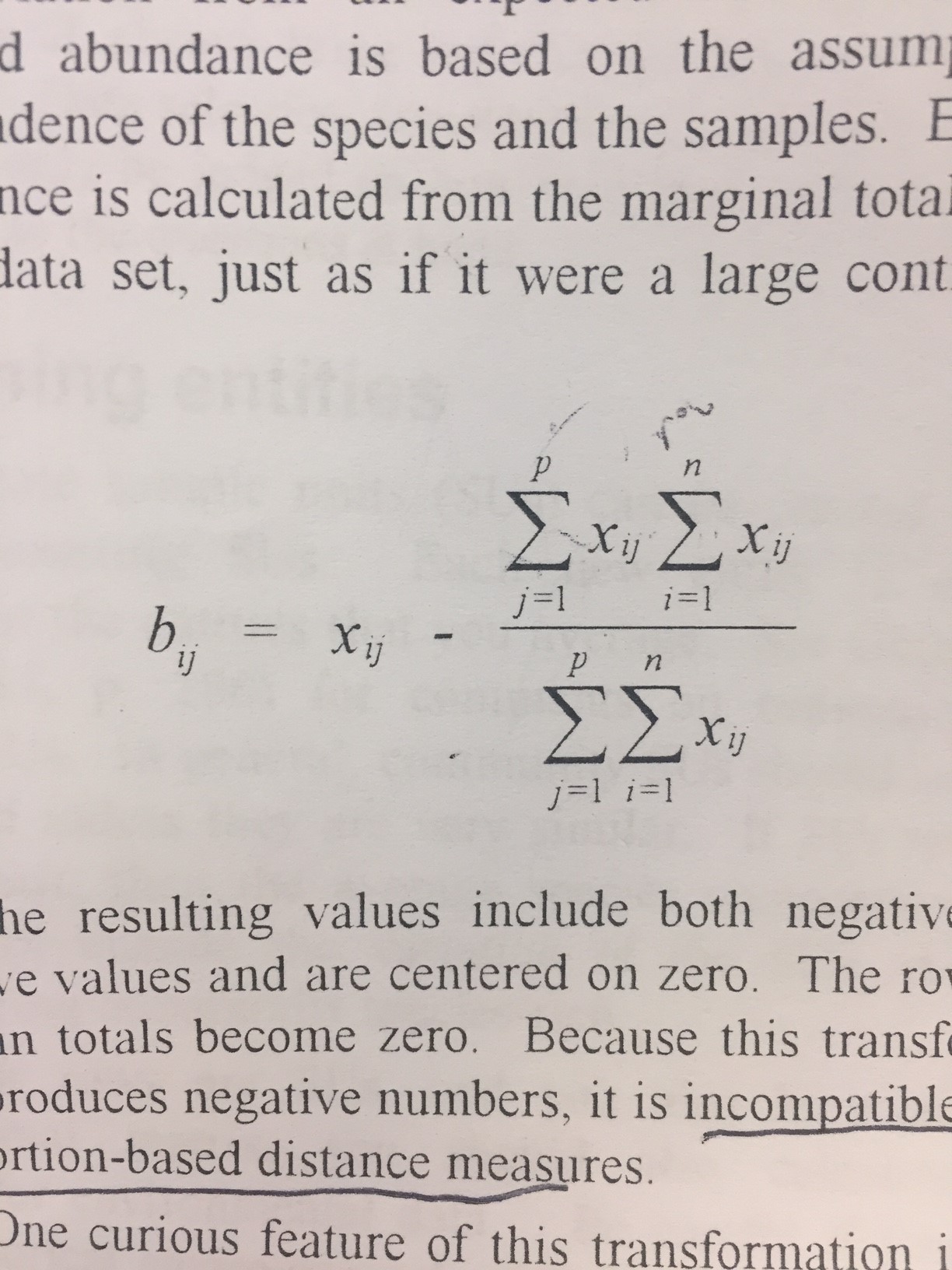I am trying to condition my data sheet for cluster analysis and am coming from R and Excel transitioning to knime.
I have a full matrix of different organism and there counts. I need to add 1 to ever cell for each column then standardize the whole data sheet (logarithmicly) relative to reach other to find significant. I am struggling to understand the the math formula node. Most of the examples are only changing 1 column and I have about 40.
What would my steps be?
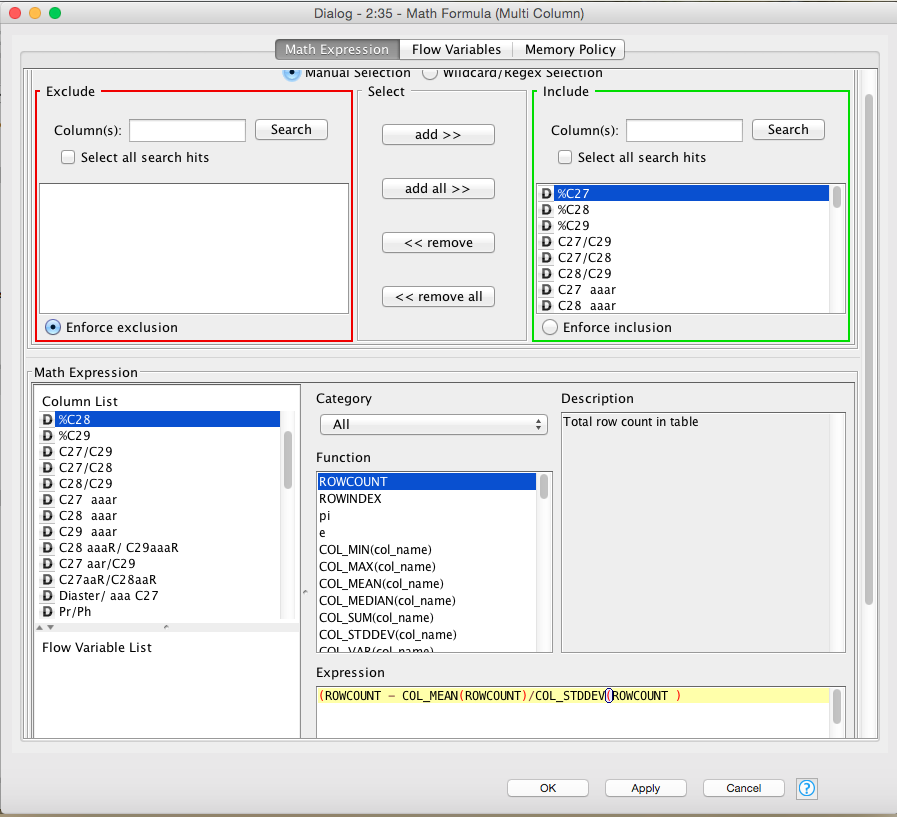
If I use the math formula for multi-column how do I compute an average deviate for each cell?
For each cell, I want to ((Xi-Xjmean)/ Xjstanddiv) j being the whole column of values? screenshot posted below
CURRENT_COLUMN (in the column list) is what you missed. Use it as Xi. And you can calculate the column average by using COL_MEAN() as you did and using CURRENT_COLUMN as column name. And the same for COL_STDDEV().
Use parentheses around parts of your expression if you want it to be calculated the same as the formula you provided: (Xi-Xjmean)/ Xjstanddiv
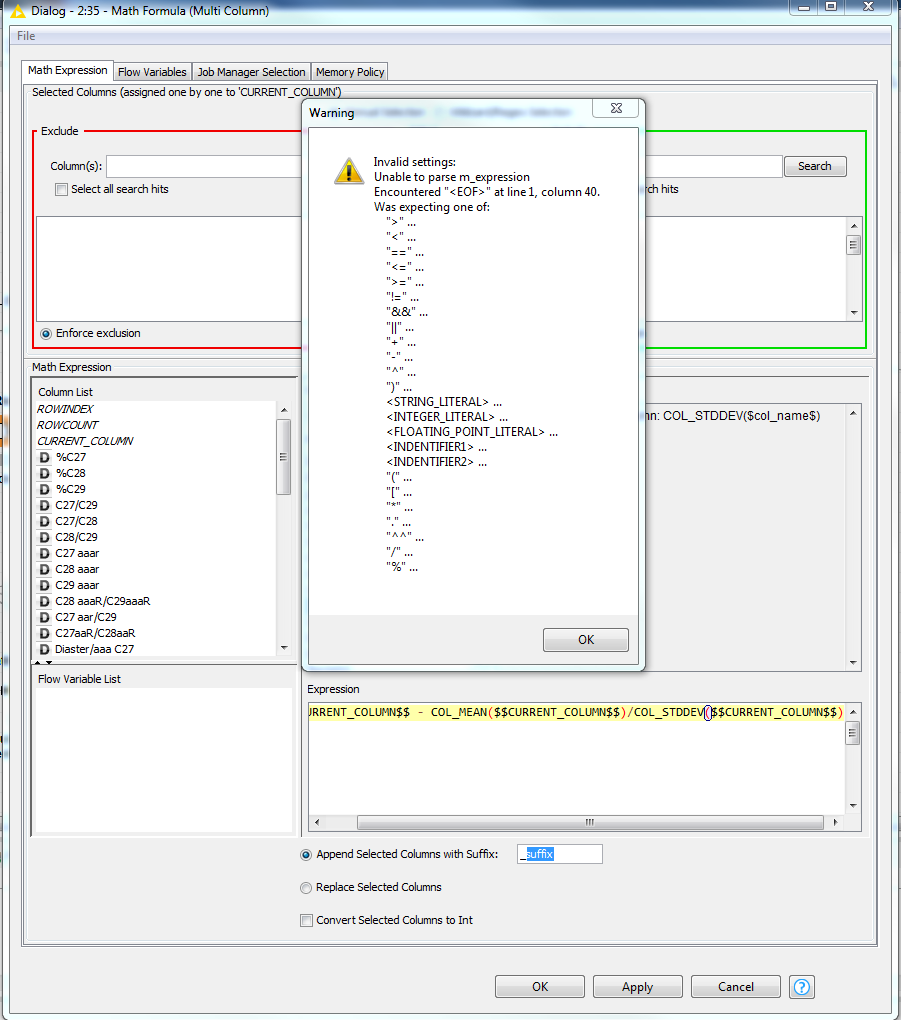
($$CURRENT_COLUMN$$ - COL_MEAN($$CURRENT_COLUMN$$)) / COL_STDDEV($$CURRENT_COLUMN$$)
Use this expression and let me know if the error occurs again.
Thank you @armingrudd
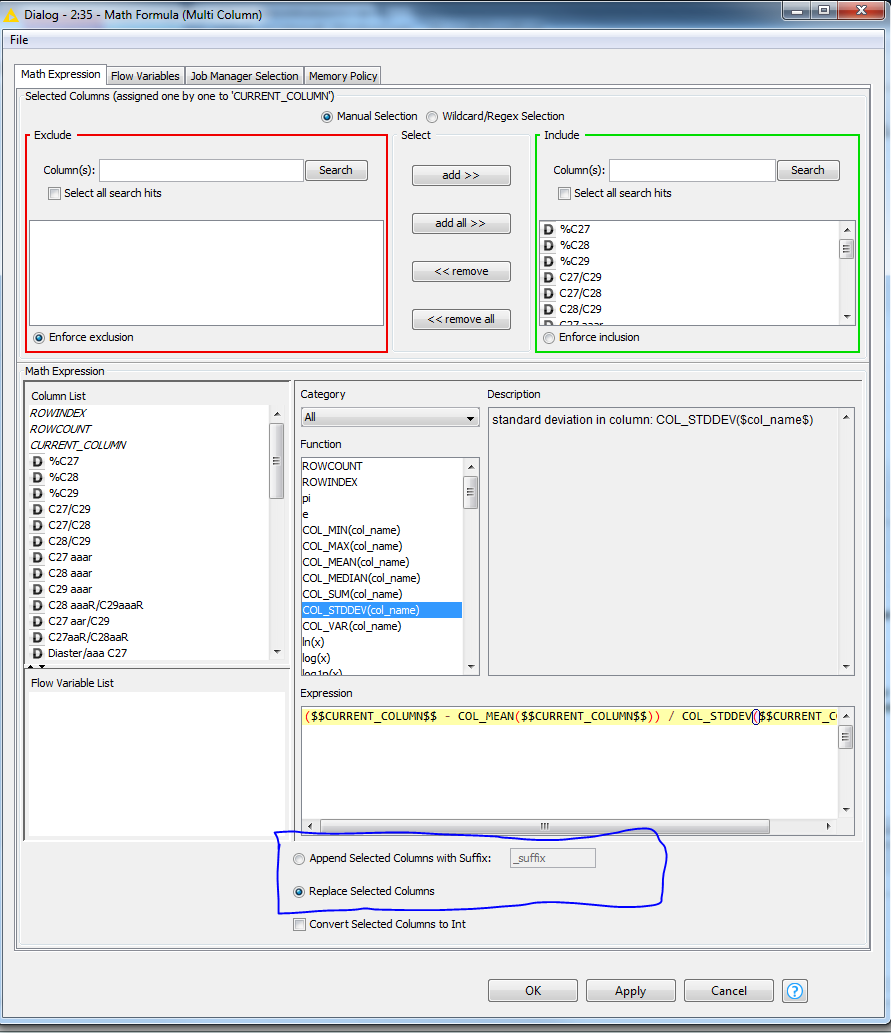
It seems to work well simmilar to (R table to Table R ) configuration. I noticed that if I don not have the Replace Selected Columns checked, it wont Output the formatted data. Why is that?
Still I’m not sure if I got your point perfectly, but the difference between the 2 options is that the first option (append) adds new columns for the calculations and keeps the original columns as well. On the other hand, the second option (replace) removes the original values from existing columns and overwrites the new values.
Hi @armingrudd
Thank you that makes it very clear.
Now I am trying to do another data transformation with the data table prior to the standard diviate you showed me above. I want to double relativization with
bij = Xij - (columnSigmaXij * rocSigmaXij)/ (ColumnSigmaRowSigmaXiJ)
I am not sure how to sum the rows in the data sheet outside the column
Here is the workflow: math formula.knwf (19.2 KB)
Dear @Iris, when I was creating the workflow to calculate the formula, I noticed that I cannot calculate ΣΣXij (which is the sum of all values in the table) in a single formula with other calculations (Check second math formula node in my workflow - you cannot use “COL_SUM($Row Sum$)” at the end instead of $Row Sum_suffix$ which I had to calculate in the previous math formula node). Why is that?