Hi,
I have a data set with 3 columns whose header change every month. I need to calculate average of those three variable columns. How do I do that?
Jul (M-1), Jun (M-2), May (M-3) will keep changing as the month passes by
Hi,
I have a data set with 3 columns whose header change every month. I need to calculate average of those three variable columns. How do I do that?
Jul (M-1), Jun (M-2), May (M-3) will keep changing as the month passes by
See this wf mean_of_variable_columns.knwf (63.0 KB)
gr. Hans
@HansS It might just be me but I don’t really see the connection with what is being asked, a mean value of a bunch of doubles. It looks like you concat the value of the month in the mean value output as well.
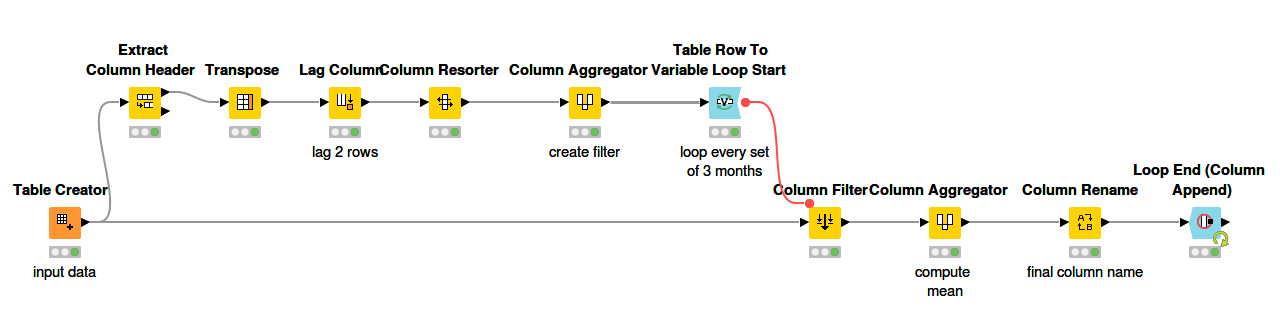
@nidhichirania A more efficient route would be to use patterns or type filters in the GroupBy node, which stays away from loops and only requires one node.
Assume this small data set:

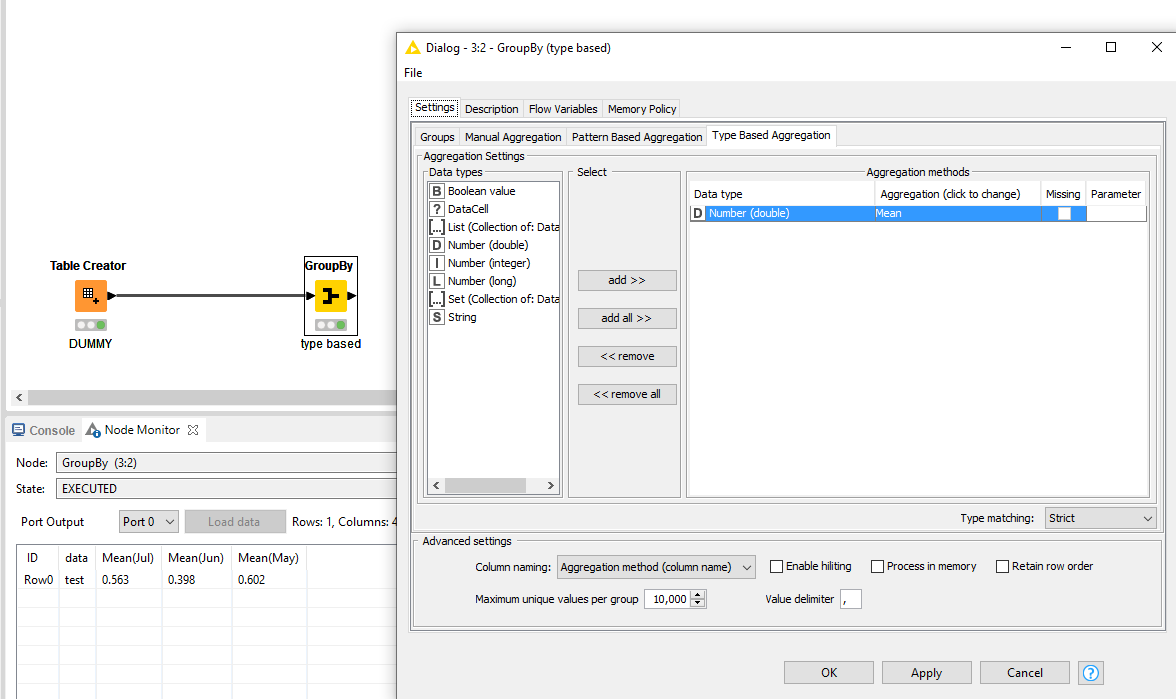
If the months are the only columns that are of type Double, you can use the GroupBy option for Type Based Aggregation.
This takes the mean value of all columns that are of type double. You can opt to define a group to include other information, but that really depends on your actual use case.
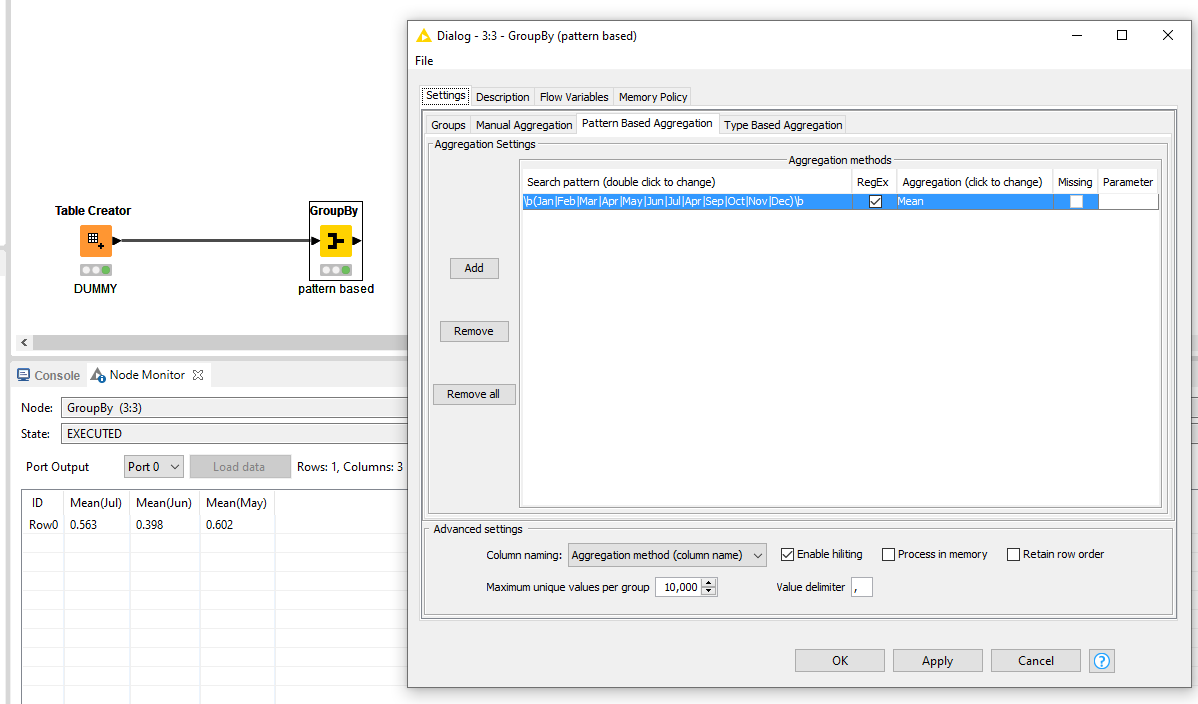
An even safer route is via the Pattern Based Grouping. This will calculate the mean for columns that satisfy the set pattern. Here, you can define a Regex that only allows months by means of \b(Jan|Feb|Mar|Apr|May|Jun|Jul|Apr|Sep|Oct|Nov|Dec)\b
Noticeably, all the other columns are filtered out. If months have different nomenclatures, it’s simply a matter of updating the Search Pattern.
WF:
Mean of variable columns.knwf (20.1 KB)
Hope this helps!
I love this forum. I had fallen into a pattern of immediately using a combo of the Regex Column Select / GroupbBy to solve this kind of thing, completely ignoring Pattern Based Aggregation. Thanks for the reminder that I have been underutilizing the GroupBy node. I love a good 1 node solution!
Note to self and others, the second Apr should be Aug off course ![]()
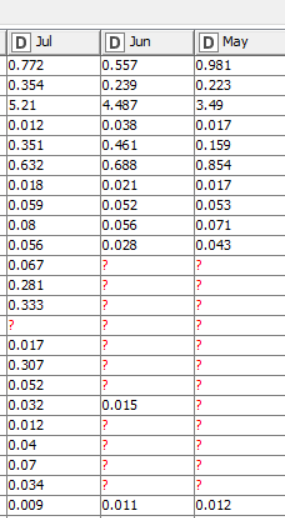
Hi Thanks a lot for response. I too got to know a brilliant use of group by today. Though you are aggregating all the rows of a single column together, my requirement here was calculating mean of columns:
Input table:
| Jul | June | May |
|---|---|---|
| 0.7720045 | 0.5572995 | 0.981212222 |
| 0.354341042 | 0.239390889 | 0.222717542 |
| 5.209707917 | 4.4872722 | 3.489734167 |
| 0.01216675 | 0.038087 | 0.01692725 |
| 0.350684833 | 0.461149 | 0.158695 |
| 0.632433 | 0.688442 | 0.854134 |
| 0.017579333 | 0.020602 | 0.016646 |
| 0.058993556 | 0.051526333 | 0.052870633 |
| 0.080202 | 0.0559178 | 0.0708382 |
| 0.055620333 | 0.027738 | 0.042978833 |
Output Table:
| Jul | June | May | Average |
|---|---|---|---|
| 0.7720045 | 0.5572995 | 0.981212222 | 0.770172074 |
| 0.354341042 | 0.239390889 | 0.222717542 | 0.272149824 |
| 5.209707917 | 4.4872722 | 3.489734167 | 4.395571428 |
| 0.01216675 | 0.038087 | 0.01692725 | 0.022393667 |
| 0.350684833 | 0.461149 | 0.158695 | 0.323509611 |
| 0.632433 | 0.688442 | 0.854134 | 0.725003 |
| 0.017579333 | 0.020602 | 0.016646 | 0.018275778 |
| 0.058993556 | 0.051526333 | 0.052870633 | 0.054463507 |
| 0.080202 | 0.0559178 | 0.0708382 | 0.068986 |
| 0.055620333 | 0.027738 | 0.042978833 | 0.042112389 |
Where Header of Jul, June, May keeps changing
From @HansS response, I understood that changing the header name to some nomenclature like M0,M-1,M-2 this can be carried out.
Thanks @ArjenEX / @HansS for your time and response ![]()
@iCFO I too love this forum ![]()
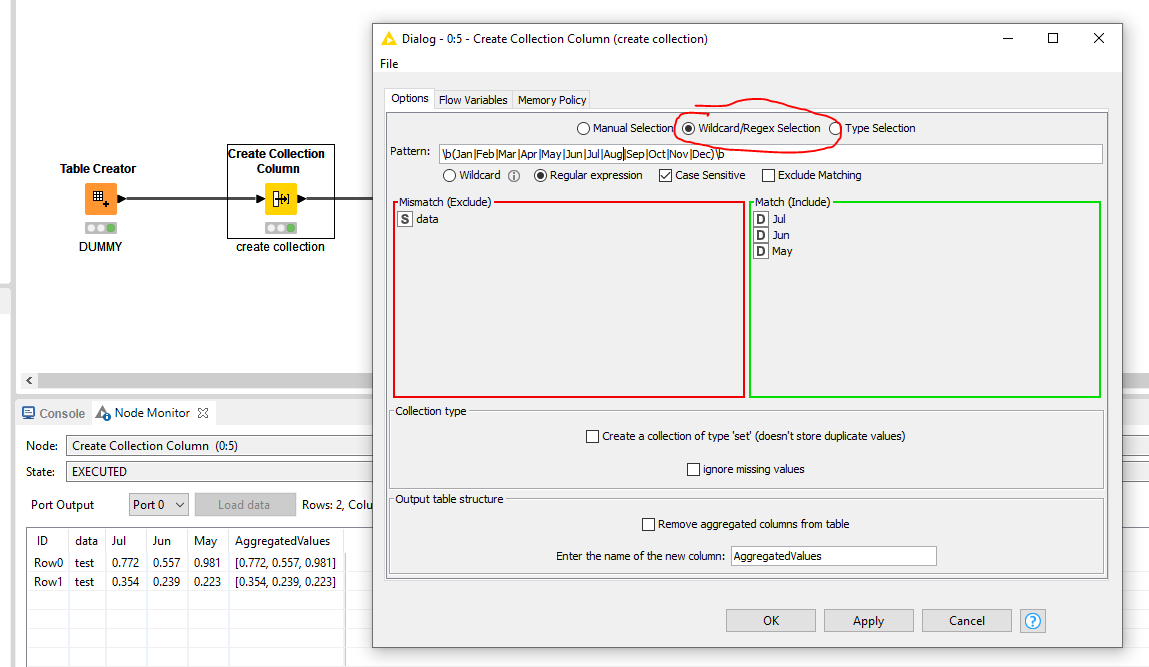
I see @nidhichirania. In that case:
I would create a collection with the Create Collection Column node, use Wildcard/Regex Selection and use the beforementioned filter.
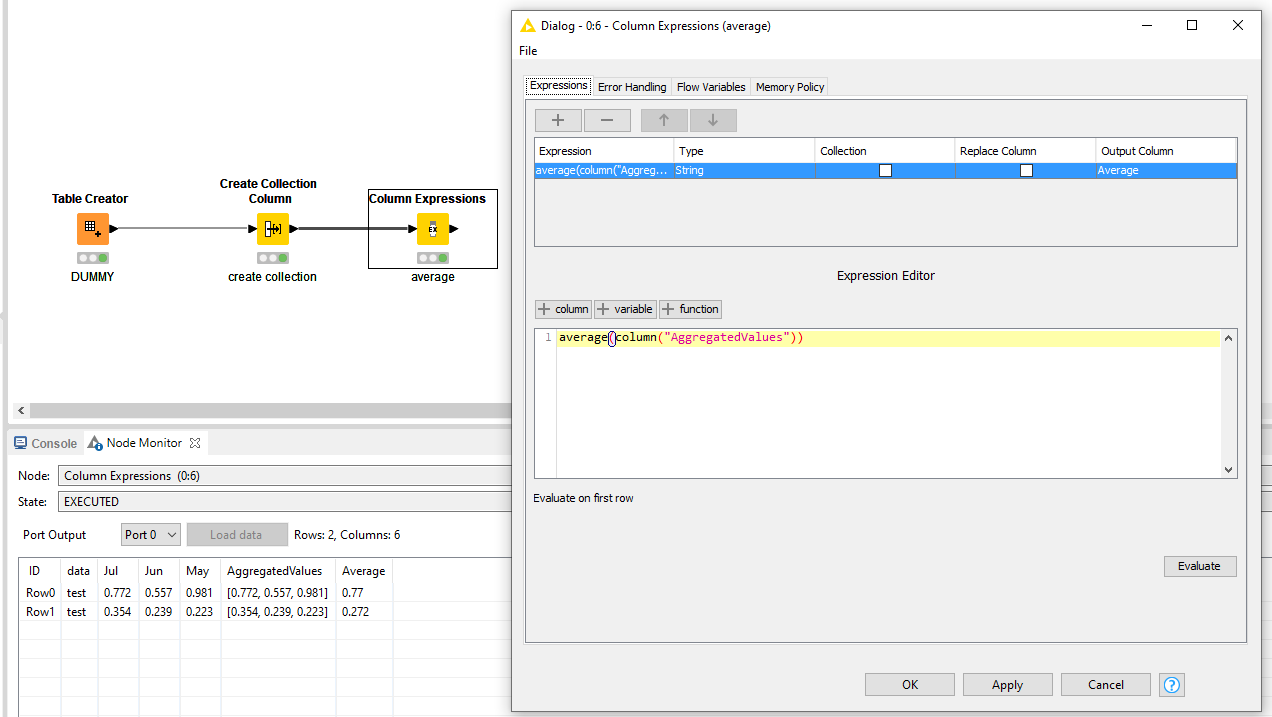
Next, add a Column Expression node and average the AggregatedValue collection
If you don’t have it, I highly recommend getting it. It’s one of the most versatile nodes out there.
The output seems to match your expected output (whereby yours has higher precision off course due to my dummy setup) .
V2 WF:
Mean of variable columns V2.knwf (16.9 KB)
PS: @iCFO While we’re at it, maybe another one for your cook book as I don’t see the Create Collection node being used a lot around here and you can do useful stuff with it pretty quickly ![]()
Hi @nidhichirania @ArjenEX , there is really no need to create a Collection for this.
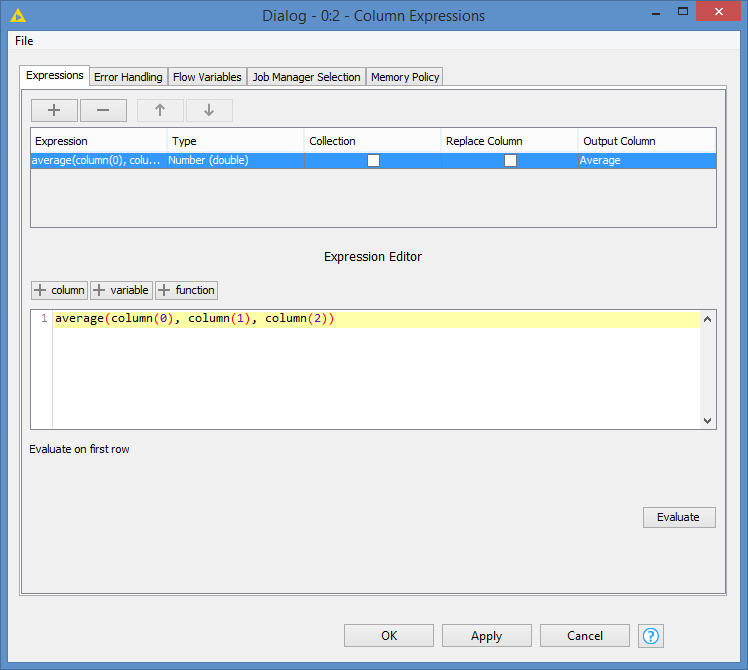
Since you are already using the Column Expressions node, and since it’ll always be 3 columns, you can access nodes without having to bother about their names by using their index.
Here’s a demo I did about this a while ago as someone asked about it:
So, for your case, something like this will work:
average(column(0), column(1), column(2))
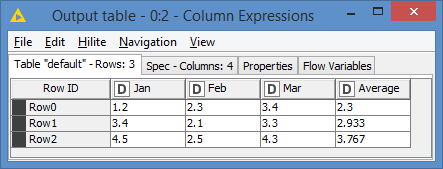
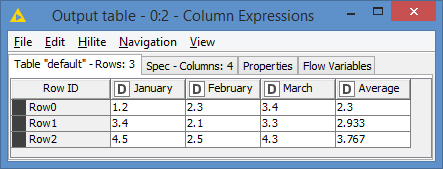
It does not matter what the headers of these 3 columns are or will be.
Input:
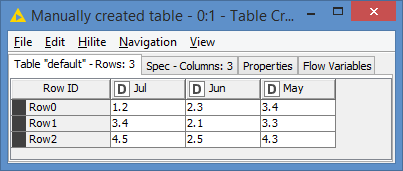
Results:
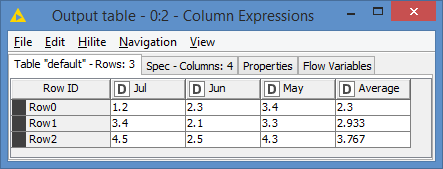
Even if the names are different, it will calculate average on the 3 columns:
@ArjenEX , @bruno29a
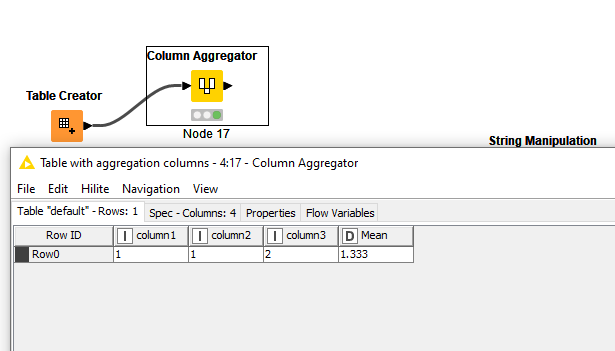
I like both your solutions (Thanks for sharing) but I still go with the column aggregator ![]()
br
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.