I’ve created this new topic in its own thread to follow up on an issue that I originally noted here (but turned out to be unrelated to that topic):
2025-02-14 12:42:53,883 : ERROR : KNIME-Worker-27-Variable Loop End 3:670 : : LocalNodeExecutionJob : Variable Loop End : 3:670 : Caught "IllegalStateException": Memory was leaked by query. Memory leaked: (12416)
Allocator(ArrowColumnStore) 0/12416/147521536/4294967296 (res/actual/peak/limit)
java.lang.IllegalStateException: Memory was leaked by query. Memory leaked: (12416)
Allocator(ArrowColumnStore) 0/12416/147521536/4294967296 (res/actual/peak/limit)
at org.apache.arrow.memory.BaseAllocator.close(BaseAllocator.java:477)
at org.knime.core.columnar.arrow.AbstractArrowBatchReadable.close(AbstractArrowBatchReadable.java:100)
at org.knime.core.columnar.arrow.ArrowBatchStore.close(ArrowBatchStore.java:117)
at org.knime.core.columnar.cache.data.ReadDataCache.close(ReadDataCache.java:356)
at org.knime.core.columnar.cache.writable.BatchWritableCache.close(BatchWritableCache.java:292)
at org.knime.core.columnar.data.dictencoding.DictEncodedBatchWritableReadable.close(DictEncodedBatchWritableReadable.java:108)
at org.knime.core.columnar.cache.object.ObjectCache.close(ObjectCache.java:197)
at org.knime.core.data.columnar.table.BatchSizeRecorder$BatchSizeAugmentedReadable.close(BatchSizeRecorder.java:157)
at org.knime.core.data.columnar.table.DefaultColumnarBatchStore.close(DefaultColumnarBatchStore.java:426)
at org.knime.core.data.columnar.table.ColumnarRowReadTable.close(ColumnarRowReadTable.java:213)
at org.knime.core.data.columnar.table.AbstractColumnarContainerTable.clear(AbstractColumnarContainerTable.java:218)
at org.knime.core.node.BufferedDataTable.clearSingle(BufferedDataTable.java:972)
at org.knime.core.node.Node.disposeTables(Node.java:1721)
at org.knime.core.node.Node.cleanOutPorts(Node.java:1685)
at org.knime.core.node.workflow.NativeNodeContainer.cleanOutPorts(NativeNodeContainer.java:634)
at org.knime.core.node.workflow.NativeNodeContainer.performReset(NativeNodeContainer.java:628)
at org.knime.core.node.workflow.SingleNodeContainer.rawReset(SingleNodeContainer.java:553)
at org.knime.core.node.workflow.WorkflowManager.invokeResetOnSingleNodeContainer(WorkflowManager.java:5204)
at org.knime.core.node.workflow.WorkflowManager.resetNodesInWFMConnectedToInPorts(WorkflowManager.java:2826)
at org.knime.core.node.workflow.WorkflowManager.restartLoop(WorkflowManager.java:3793)
at org.knime.core.node.workflow.WorkflowManager.doAfterExecution(WorkflowManager.java:3664)
at org.knime.core.node.workflow.NodeContainer.notifyParentExecuteFinished(NodeContainer.java:689)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:235)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:117)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:367)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:221)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)
at java.base/java.util.concurrent.FutureTask.run(Unknown Source)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
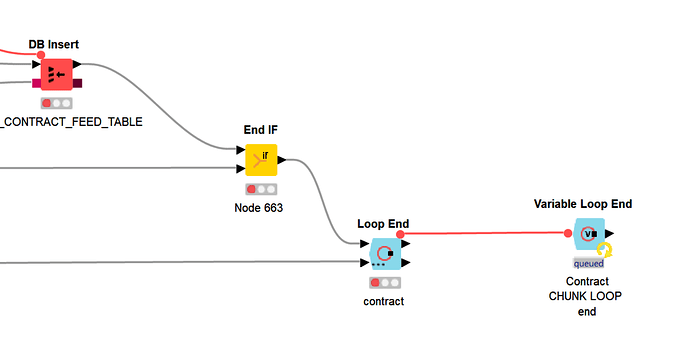
This memory leak error causes the loop to terminate in an abnormal way, and breaks the workflow, so that it cannot be restarted without closing and re-opening.
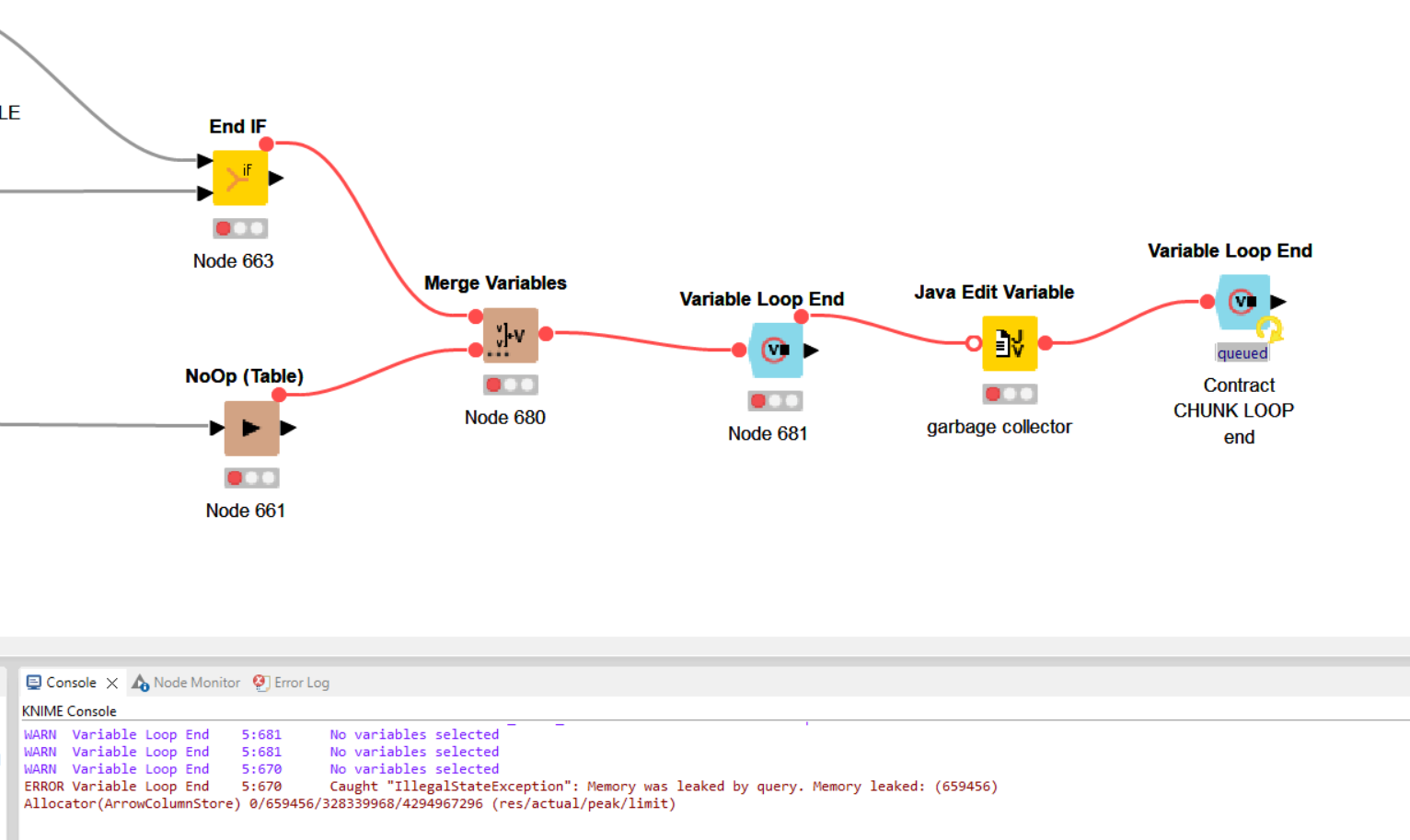
As you can see in this screenshot, the final loop end is still showing as “queued” even though the nodes on which it is dependant have been terminated with “red” status.
There is no clear reason why they are red within the UI and the only thing indicating that something is badly wrong is the above inconsistent node states, and the memory leak error in the log file.
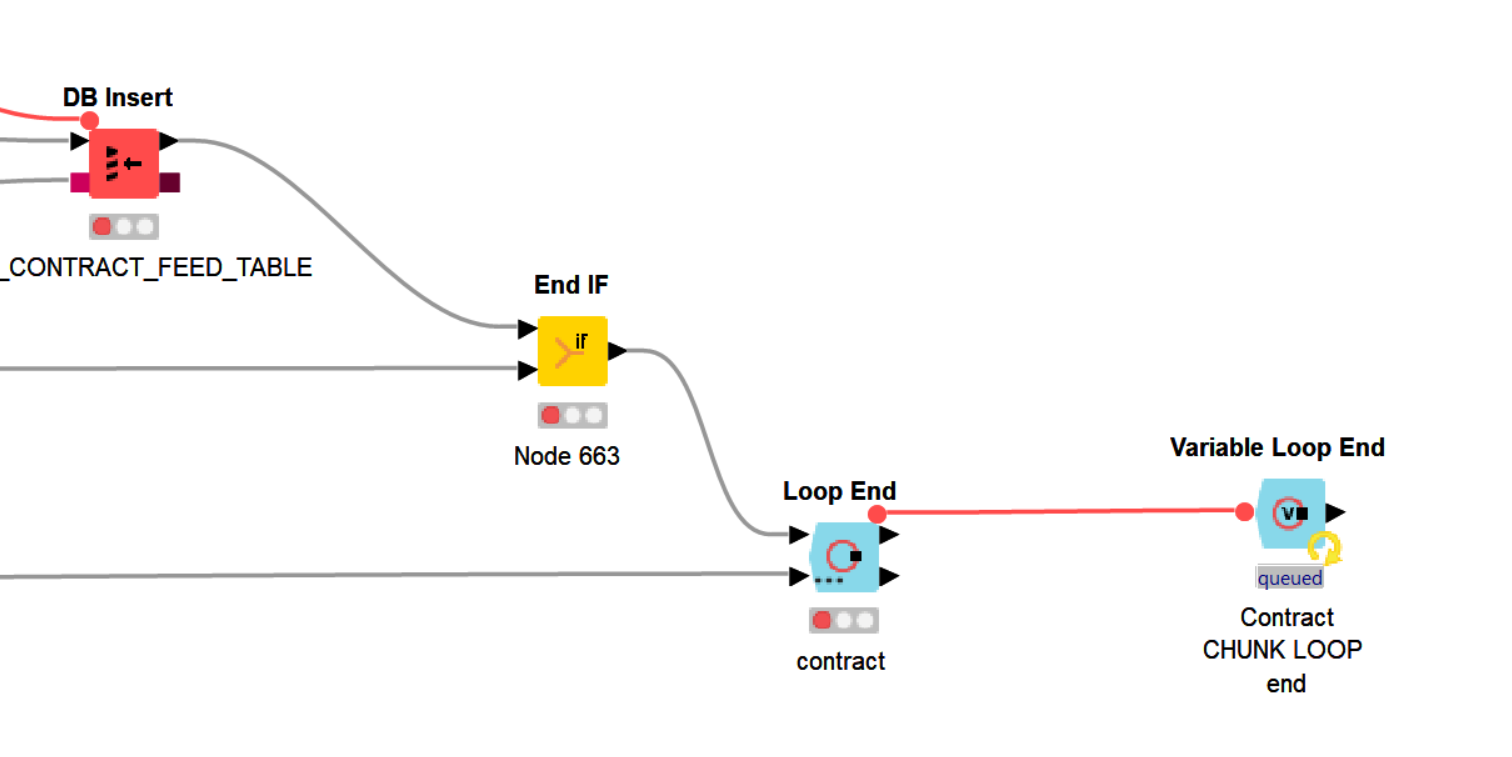
Tracking back through the workflow, we find places where a node is green but the following node is an a red state for no reason:
Attempting to modify the config on the “red” node results in the following, indicating that KNIME thinks the workflow is still executing:
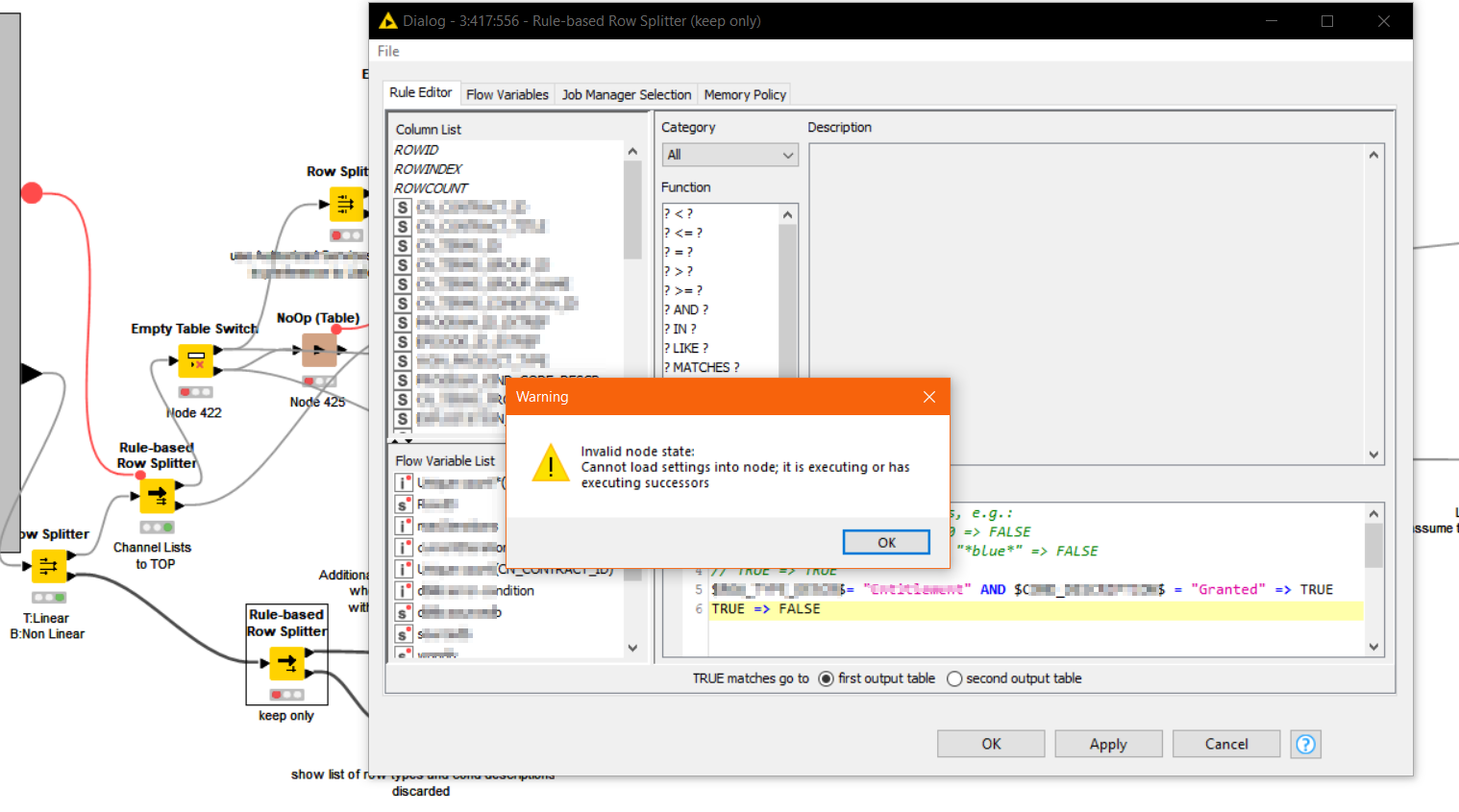
The red node has the option to “Execute” but selecting “execute” does nothing.
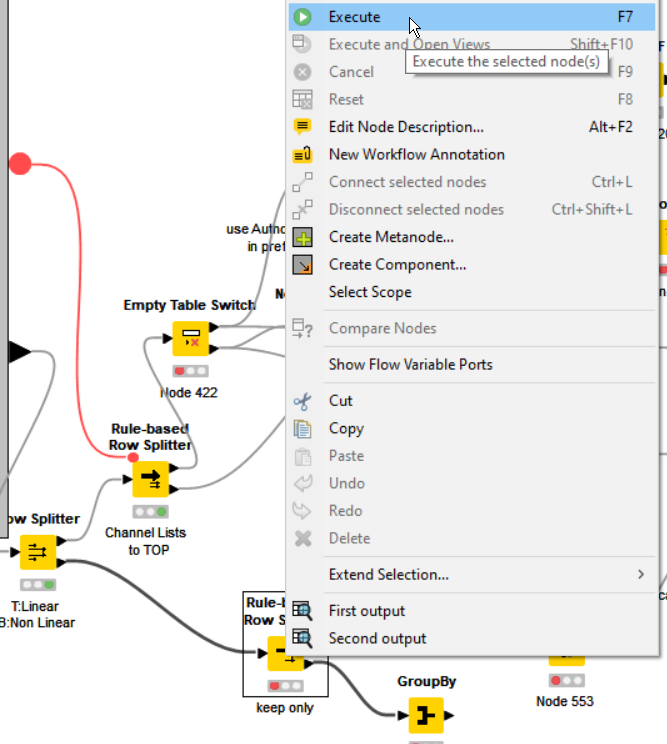
The final loop end node can be cancelled, but any attempts to execute it again, or execute any other node does nothing.
This appears to be similar to the following from KNIME 4.5, but then it was suggested it was resolve in KNIME 4.5.2
It also appeared here
I am seeing this in Classic UI on KNIME 5.3.3, 5.4 and 5.4.1.
I had reverted to 5.3.3 because I was seeing the error in 5.4. I don’t know if the error would also occur in MUI. I tried the workflow in MUI in 5.4 and 5.4.1 but unfortunately it won’t work because KNIME constantly pops up the “An unresponsive user interface has been detected” and eventually the UI becomes unresponsive with the only option available being “save and close”.
I will try it in MUI in 5.3.3 to see if I can progress.
I am using Windows 10, with max 10G memory allocated to KNIME, and the table backend is set to “Columnar”
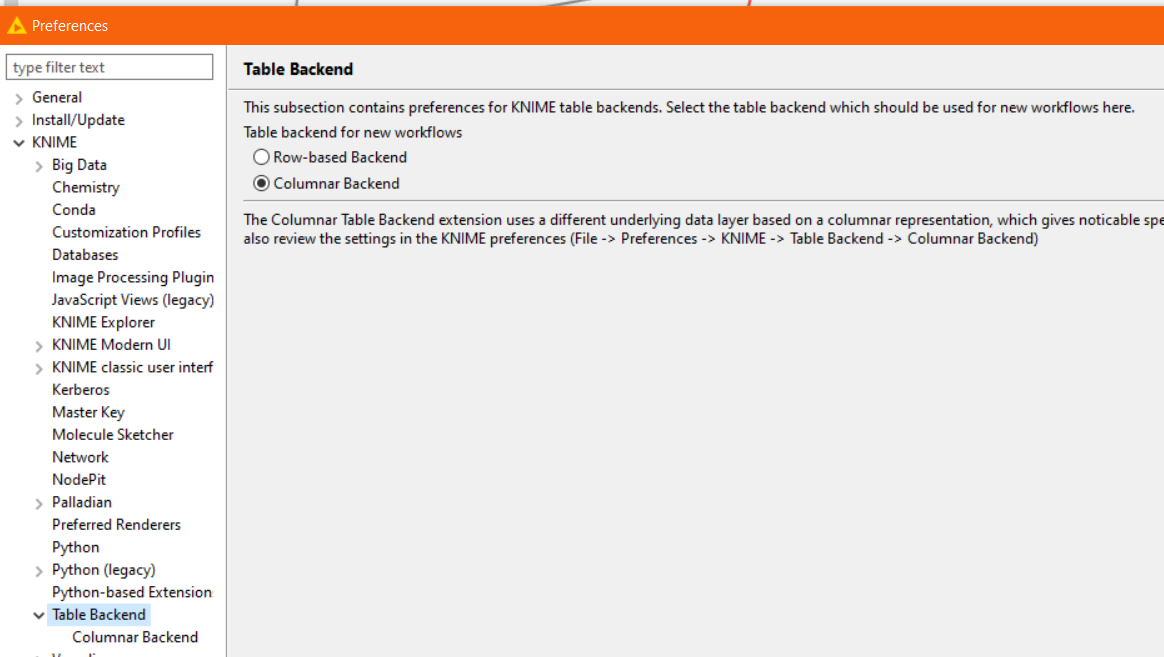
It would be good to know what might be causing this issue, or anything I should look out for that might be triggering it? The workflow is quite large but the total data volumes being processed is not excessive. We’re talking thousands of rows overall.
I will try replacing the loop ends with the following, since I don’t actually need to collect the results.
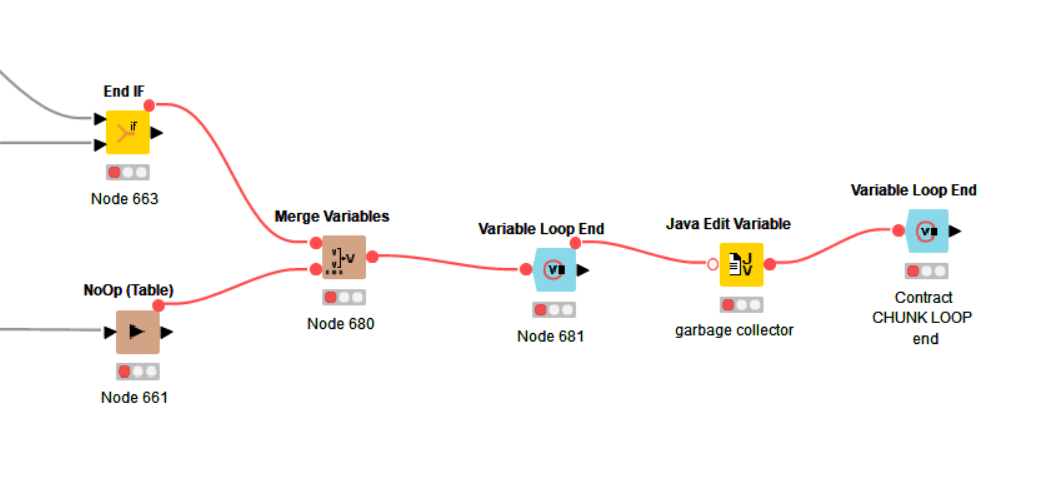
Maybe that will help if it is a memory issue, but it would be good to know root cause.