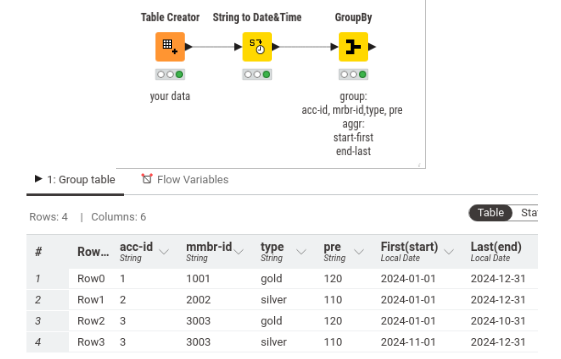
I am looking for a way to merge rows with matching data where the start date of the next row follows on from the end date of the previous row as shown below:
This is great the only issue and I know I did not cite this clearly, is that if there happened to be a gap between the end and start date for the next row it can’t merge into one row. I am wondering if it would be something along the lines of counting the days between the end date of the prior row and the start date of the next row? I appreciate your help.
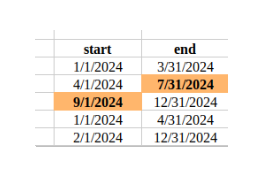
is this what you mean by a gap?
the workflow is still okay because the groupby node is looking at the first and the last date data on the grouping. if this is not what you meant, maybe you can provide a ‘dummy’ sample of the gap you encounter and the required expectation (counting days) , using spreadsheet, text writer, or etc …
Yes I will add to the additional data. What I mean is that if there is a gap of let’s say a month they should not merge and instead stay as a separate rows. Otherwise it creates the impression that the coverage dates ran without any gaps.
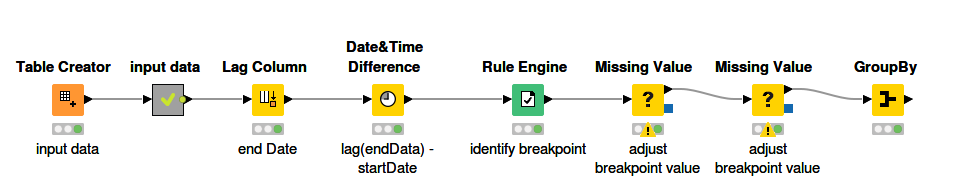
You could use the lag node to drop the end date from the row above and then the date time difference node set to the granularity of days. A positive number of more than 1 days should be a gap and 1 or less days should be no gap.Then a formula to change numbers 1 or less to zero and positive numbers greater than 1 should be turned to 1. Then the moving aggregation node to turn those zeros and ones into a running count that could be used as a group ID. Then group by on that new group id column to merge dates with an overlap.
Indeed as @iCFO mentioned you need to identify the “break-points” in the date-sequence. As always there a different approaches in KNIME to do that. Here is an other one merge_rows_with_continious_dates.knwf (57.6 KB)