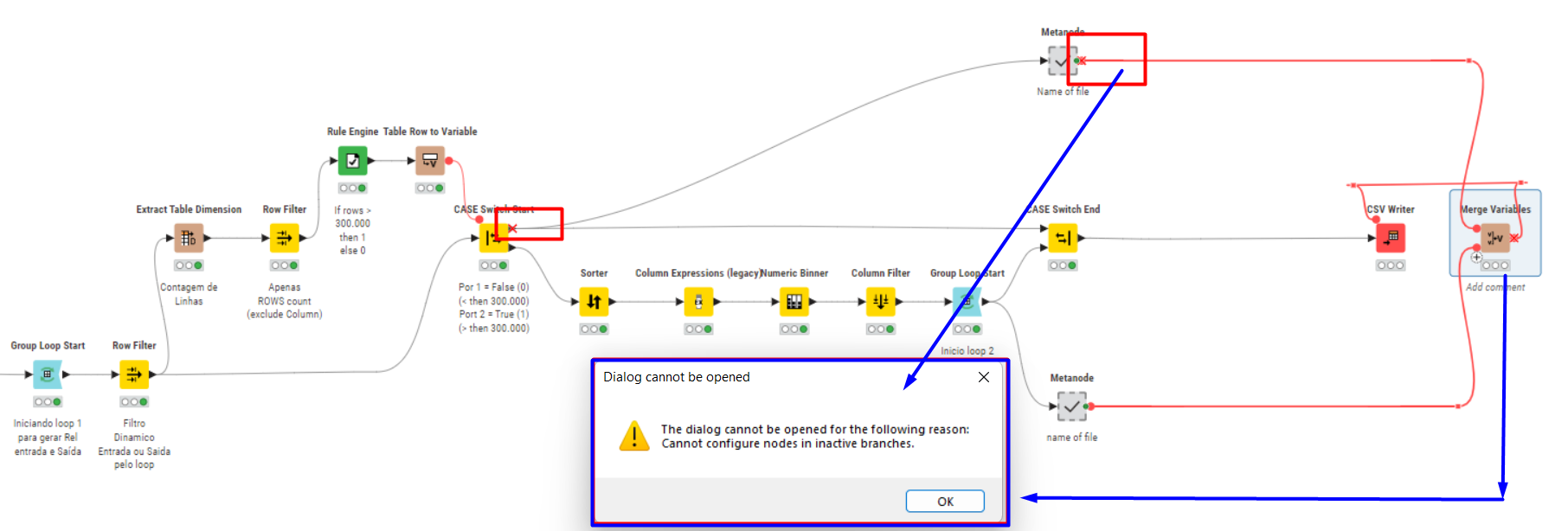
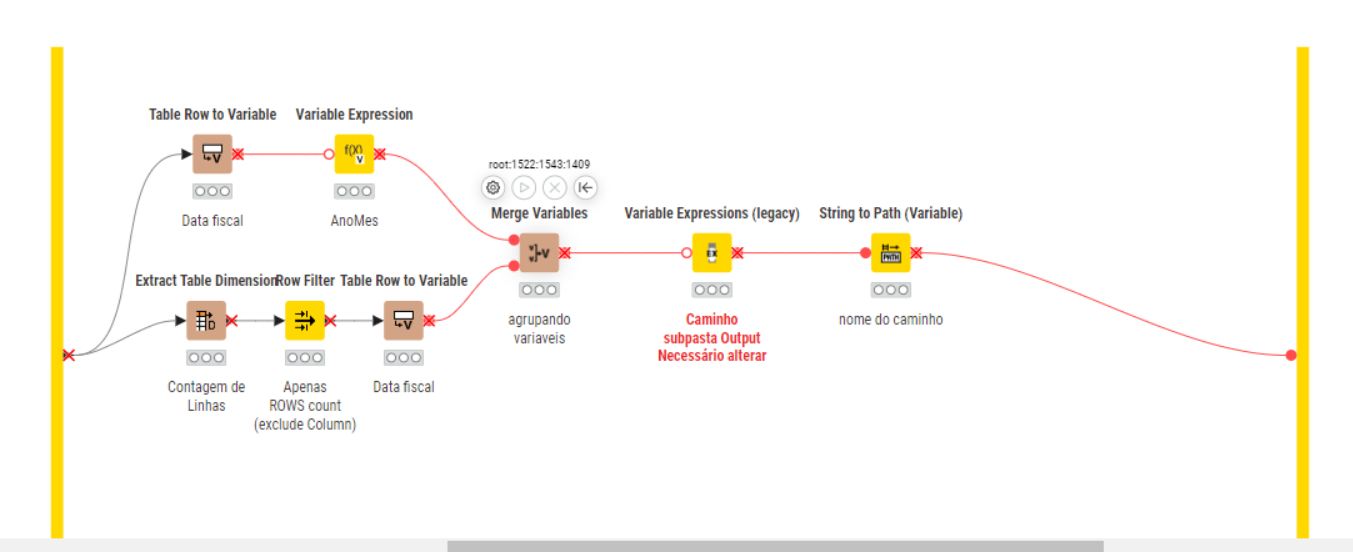
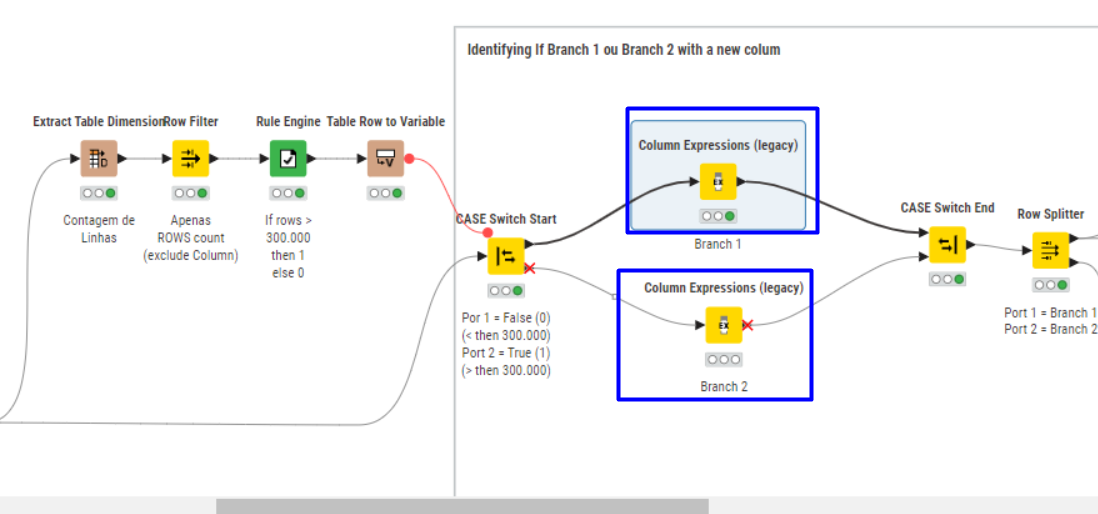
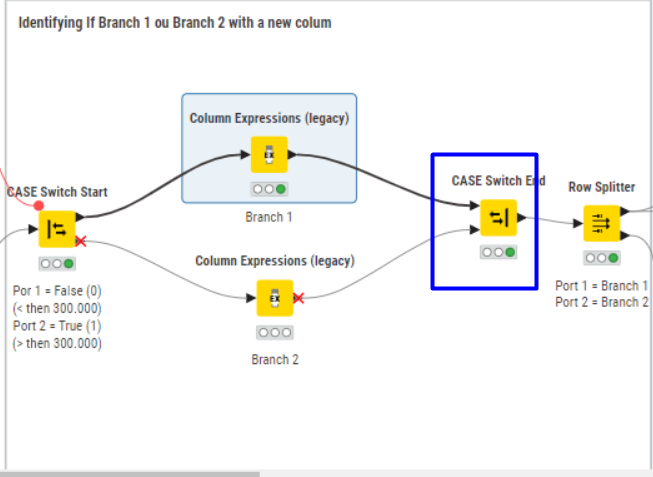
I made several attempts, and my issue always occurred during the finalization of the Group Loop/End Loop.
I kept looking at the workflow, thinking, and my decision was as follows:
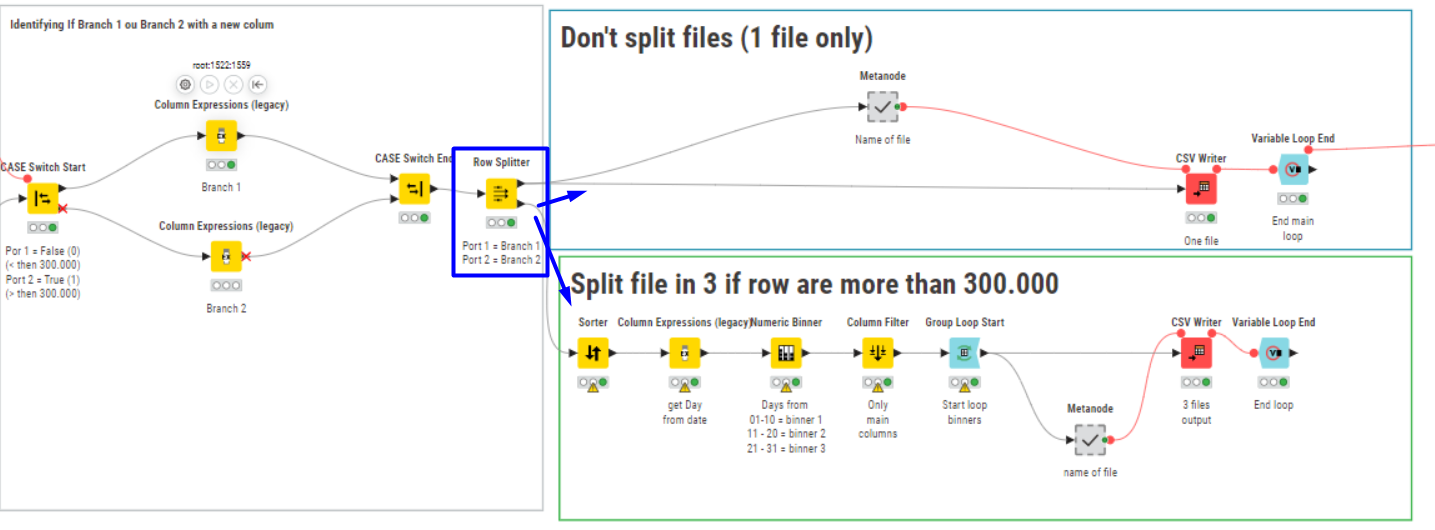
Inside the Case Switch, I identified the rule I set: If the total number of rows is greater than 300,000, then branch 2; otherwise, branch 1. In the Column Expression, I created a column as a string to identify which result was selected.
After that, I followed the rules to create files for each branch. For branch 2, I split the table into three parts (since the file is too large to open in Excel). The main idea is to split only when necessary.
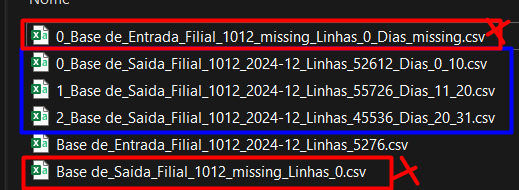
The expected result worked, but my loop ends up creating empty files when passing through the nodes, though it eventually generates the correct files.
To solve this problem, I’ll set a new rule to delete files containing the word “missing.” I think this is easier than adjusting the workflow and getting lost again.
Resume
My initial attempt was to use just one CSV Writer, but when I split the file into three, the file name changes slightly because I need to identify the iteration, number of rows per file, etc.
Either way,I believe the method I used is still not the best. I’m sure there must be a better approach.
I still don’t understand how the Try-Catch works. I tried looking at some examples, but it’s still unclear to me how to handle errors properly. I’ll need to dive deeper because I see it’s a frequently used node, and I really haven’t grasped it yet.
@Felipereis50 great that you found a solution. With knime often there is more than one. Also very good that you wrote about your solution so others could learn.
With loops and switches it will involve some planning and to think about what should happen as an alternative. Things that are used in both (or more) paths should be done before or outside a loop or switch.
Then one should think about the collection of the results.
And the first iteration of a loop can be different to set the stage so to speak.
In general if you discuss a problem on the forum it can help to provide an example that tries to isolate and pin down the core challenge. Once that is solved it can be integrated in your work and can provide solutions for others.