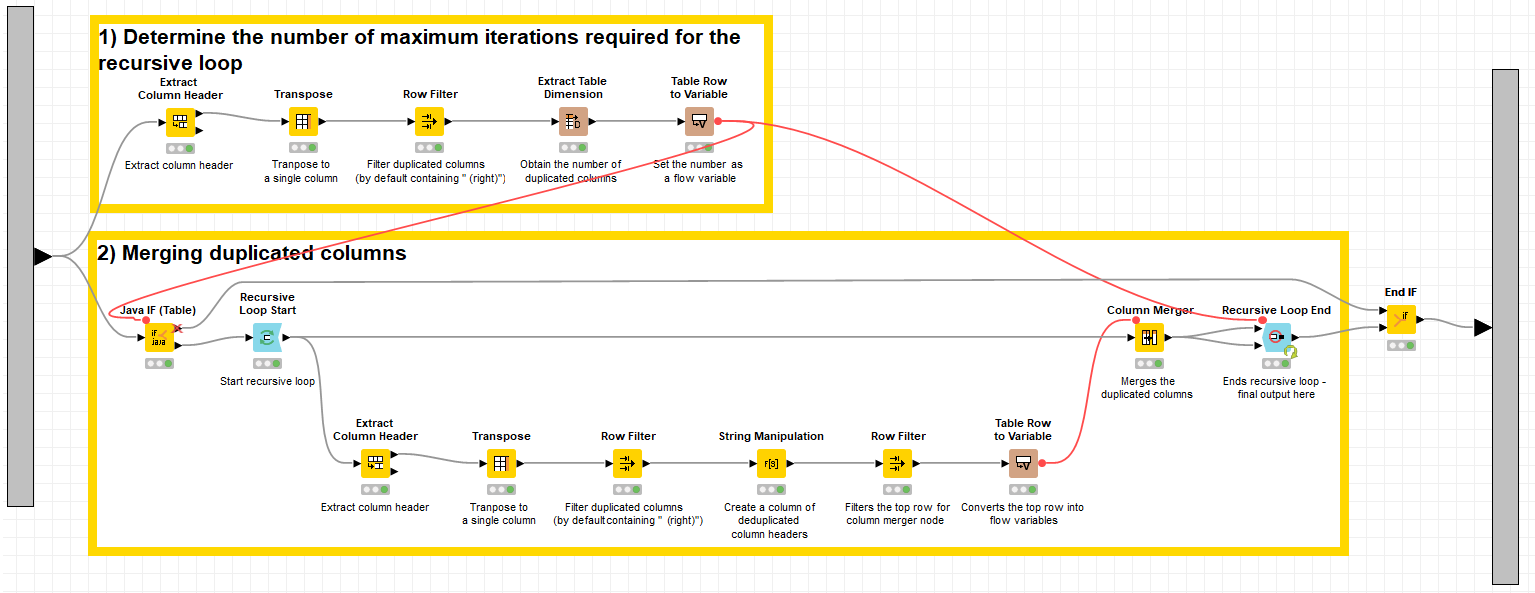
Version 1.1 2021-01-25 Combining two tables with some common columns with some common values is possible using the Full Outer Join mode of the Joiner node. However, to prevent accidental data loss in the common column, the option of removing joining column and filter column duplicates are not possible. As such, the resulting output will contain duplicated columns (with the defaut (#1) tag), and merging these duplicated columns into one unified column would be preferable for good, clean data presentation. It has to be said that that there are other approaches to combining two tables without using the Joiner node. The Concatenate node is very useful in combining two or more tables (Joiner node can only work with two table inputs), with the duplicated rows labelled (by default with _dup) and column union selected for intersected columns. However, the rows need to be deduplicated (i.e. merged into a single row entry) - usually GroupBy node can be useful, but sometimes can be troublesome when setting so many Manual Aggregation options on the rest of the columns. In addition to that, as table inputs change (as thus their respective column headers), the new columns would not be updated in the manual aggregation settings. Flow variables can possibly be created from extracting the column headers although this strategy has not been developed yet. The Column Merger node is a useful node to merge two columns by comparing the values from the primary column, filling it with the values from the secondary column if the it is mssing from the primary columns. The node can only work one pair of columns at a time. While chaining several Column Merger nodes is simpler (4 nodes in this example), this approach may not be practical if there are many columns to deduplicate or if the column pairs changes each time. This workflow utilizes the Column Merger functionality, but at the same time remains dynamic by responding to the number of column pairs and the name of column pairs by utilizing flow variables. The recursive loop allows the column merging process to work on the updated data (with one less duplicated column) while the filter function in the loop determines the remaining duplicated columns to be worked on. However, on its own the recursive loop does not work effectively as it requires a dynamic means to determine the number of iterations for the column merging process. Too low will cause insufficient columns to be merged, and too high will cause an error in the loop as there are not duplicated column headers for the Column Merger node to work on. To solve this issue, the iteration number is calculated by counting the number of duplicated colummns, a workflow which is performed outside the recursive loop, but is still connected to the recursive loop by defining a flow variable for the maximum iteration. It is hope that this workflow can be useful for those who require a dynamic approach to merging columns after a full outer join process. Either that or we hope for a merge columns functionality in the Joiner node being introduced by KNIME in the future!
This is a companion discussion topic for the original entry at https://kni.me/w/MA7IE1-N-s983D11