I’m having trouble understanding why a dataset isn’t concatenating with another. I have 2 work flows from the same database Teradata.
pulls the same query but for 2019-2024 (3GB dataset) to appease the DB admins.
pulls >=2025 (just a date reference change)
Both sequences are written to a .db file using sqlite connector and db writer.
Then using concatenate to merge them using Union and writing as a final Master.db file
Keeping their databases separate up front as this is local to my laptop and if I mess something up I can for a lack of understanding knime and sql, work backwards to where I might have messed up.
only difference is the table names, which I’m not sure how they are assigned otherwise I’d make them the same… hoping someone can help my understanding of what I’m missing or doing wrong.
says that it filtered on 500k duplicates on the concatenate node, which I believe is correct. My row filter in that workflow is before writting the database (which I run weekly to pull updated information, so the row filter in my mind need to be moved after the sql is run and written to the db.
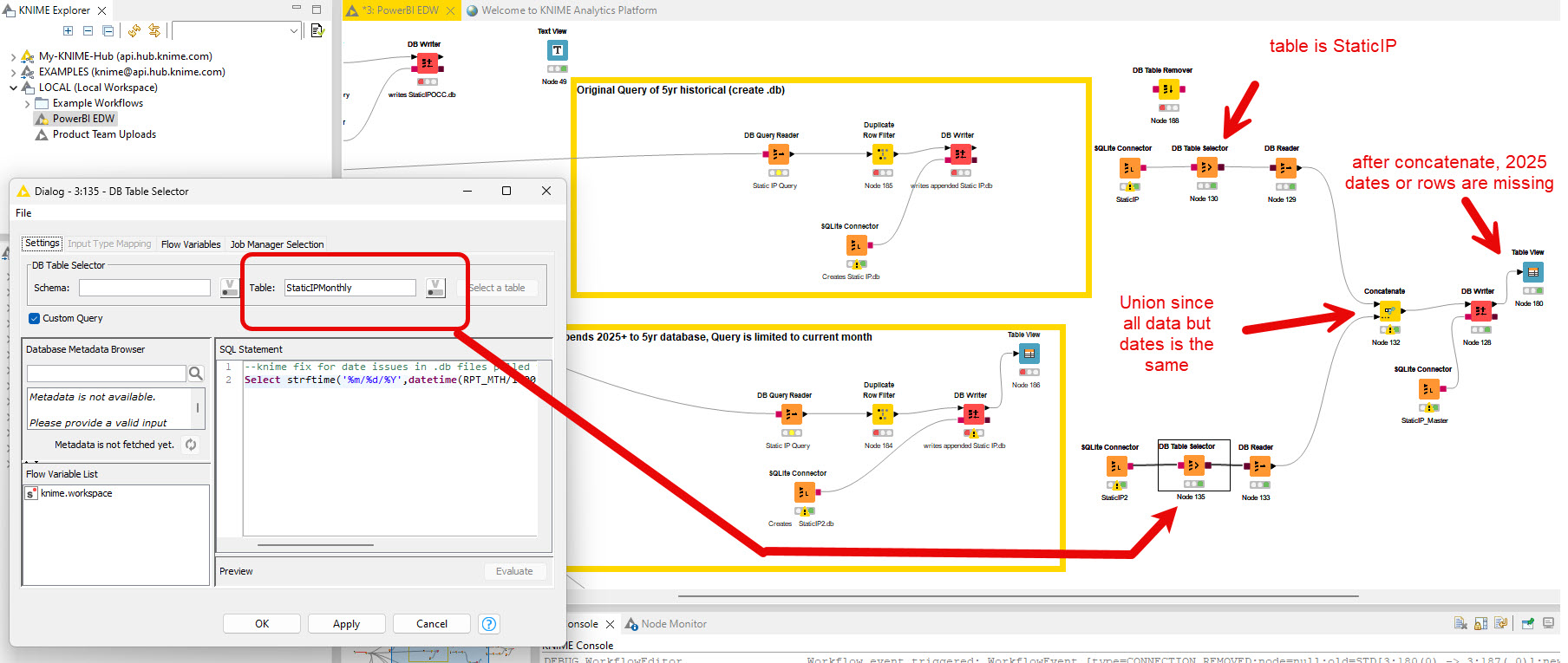
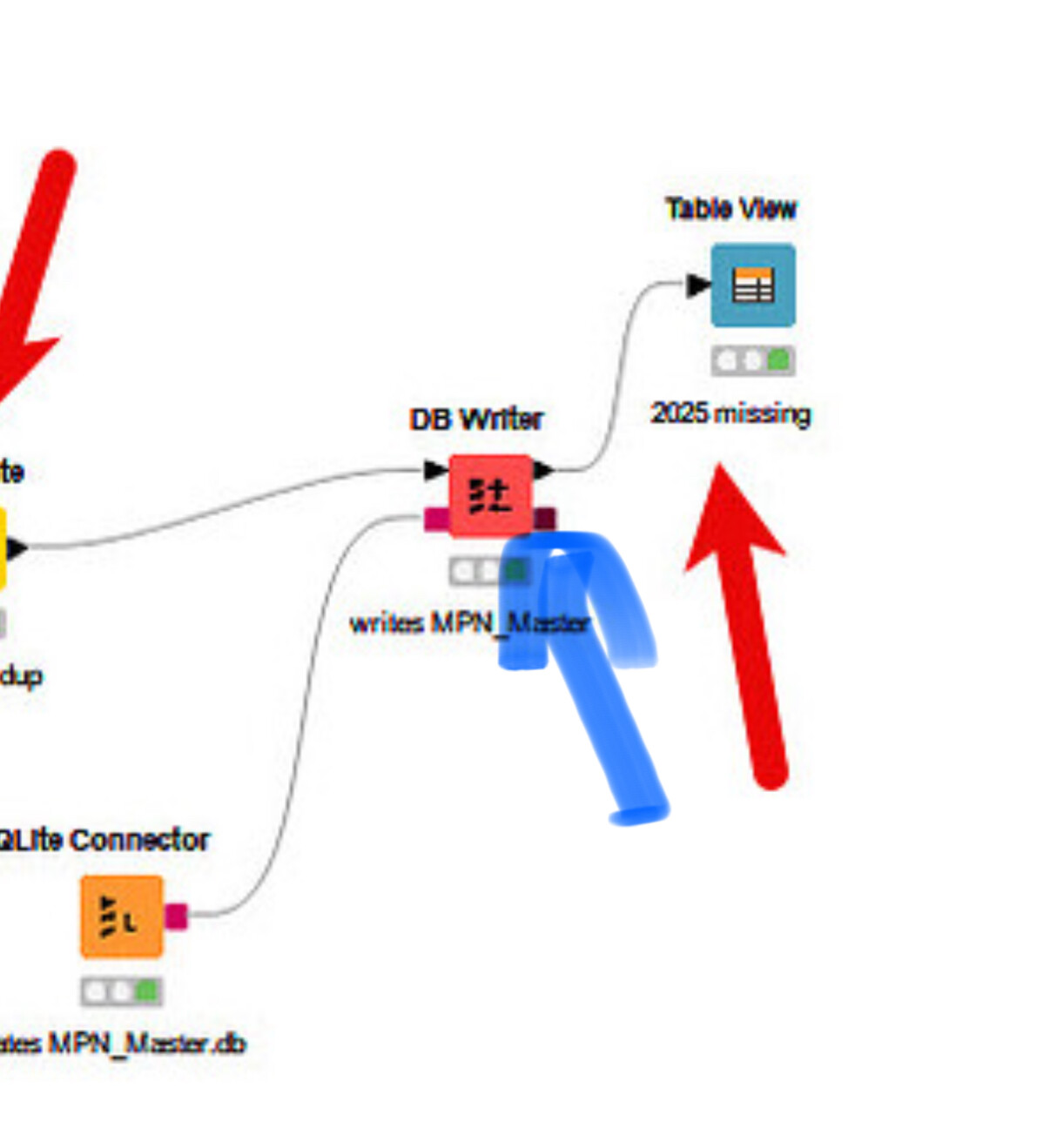
I fixed all table names to be the same now, and still get the same error. I check monthly, the rows are fine, and after concatenate they are just not present in the master.db.
@MichaelB deleting duplicates by concatenating seems messy to be honest. Have you checked the SQLite database itself? In the screenshot the Table VIEW is just about the data before not the SQLite itself.
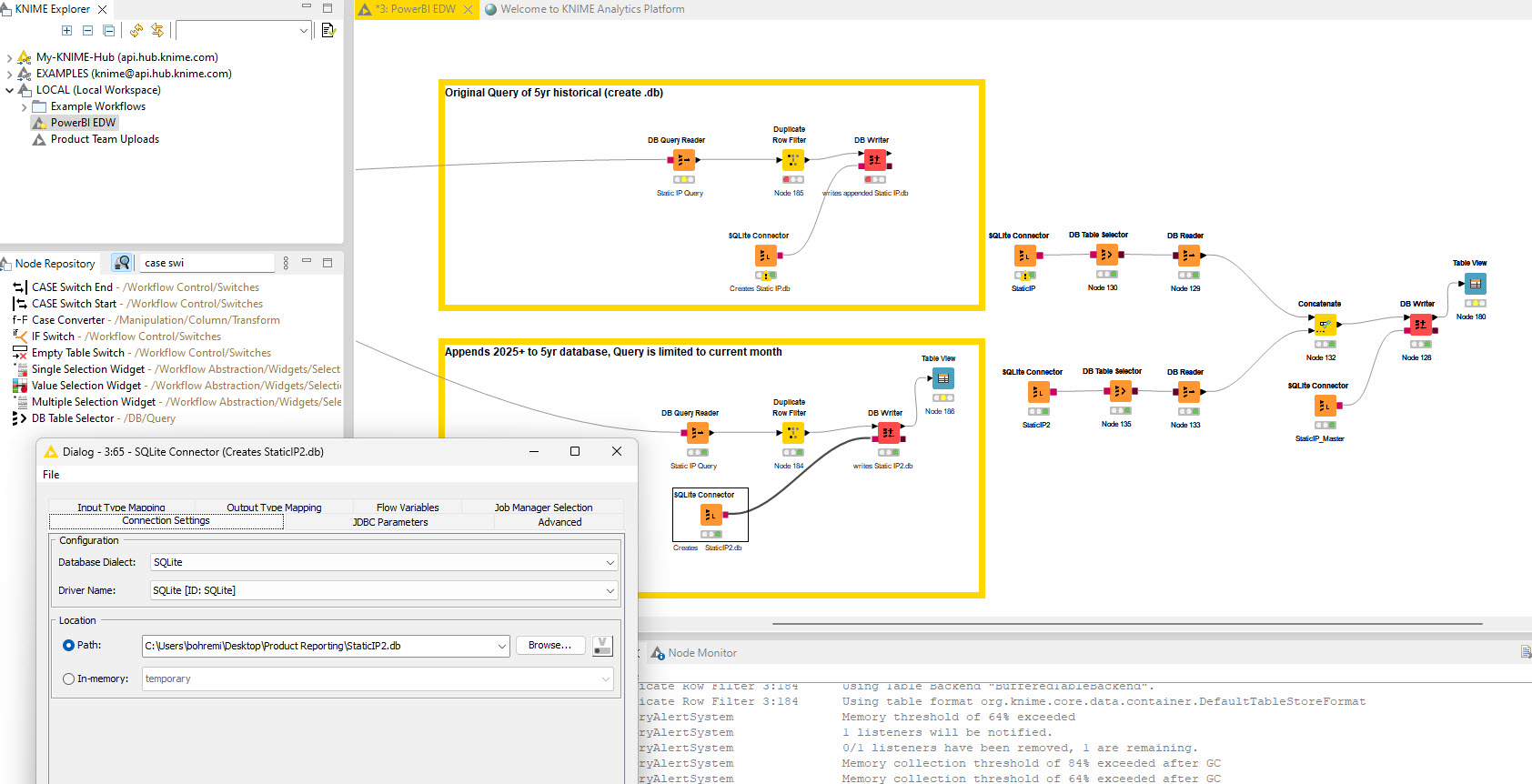
Maybe you can provide a screenshot of the SQLite settings.
the table view was after the DB Writer for StaticIP2.db for example was just be validating that I could see 2025 report month data. Below is the screenshot of the sqlite node settings. Since I only run the historical once, I’ll never run that again.
The same SQL is used in both queries, just the date range it’s pulling are different. Table names are the same in both DB Writers (StaticIP).
Since I’m running the Monthly query (lower one) weekly. I had it drop dup’s via the concatenate node as an option so that it’s not stacking weekly run data.
Am I doing that wrong? I set it up this was as trying to get two .db files to merge this was the only option I could find in the forums and or online in general.
@MichaelB you might want to check from the results from within SQLite at the end to see if the data is there. If the data is not being pulled from SQLite in the first place you will have to check the syntax and maybe do some calculation with SQL code (counts) to see if SQLite returns the data.
It is difficult to understand where there might be a problem. Next option would be to provide a full example that follows the structure of your data without spelling g any secrets and show where data is missing.
The individual DB’s pull the right information. Each sql flow is writing the right data.
Historical.db = 2019-2024
Current.db = >=2025
It’s at the concatenate stage where it finishes and the 2025 data is not in the new DB I’m creating called Master.db
I’m keeping the files separate so that if something goes wrong or I need to update the current year I don’t upset the database administrators with crushing them with compute resources. The historical alone is 3GB, 40+m rows each month for 5 years.