I’d like to make a quick thanks to all the Knime contributors to the Knime community form. I have learned a great deal from reading these post over the last month and Knime is one of my favorite analytical platforms now.
I am currently working on a preprocessing work flow to split up the meta data header from LAS (Log ASCII Standard files) http://www.cwls.org/las/
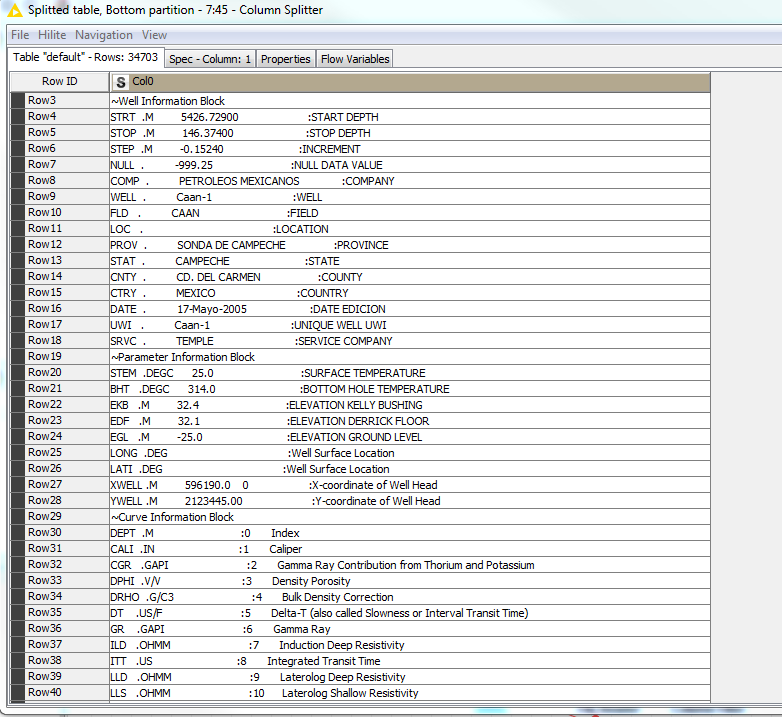
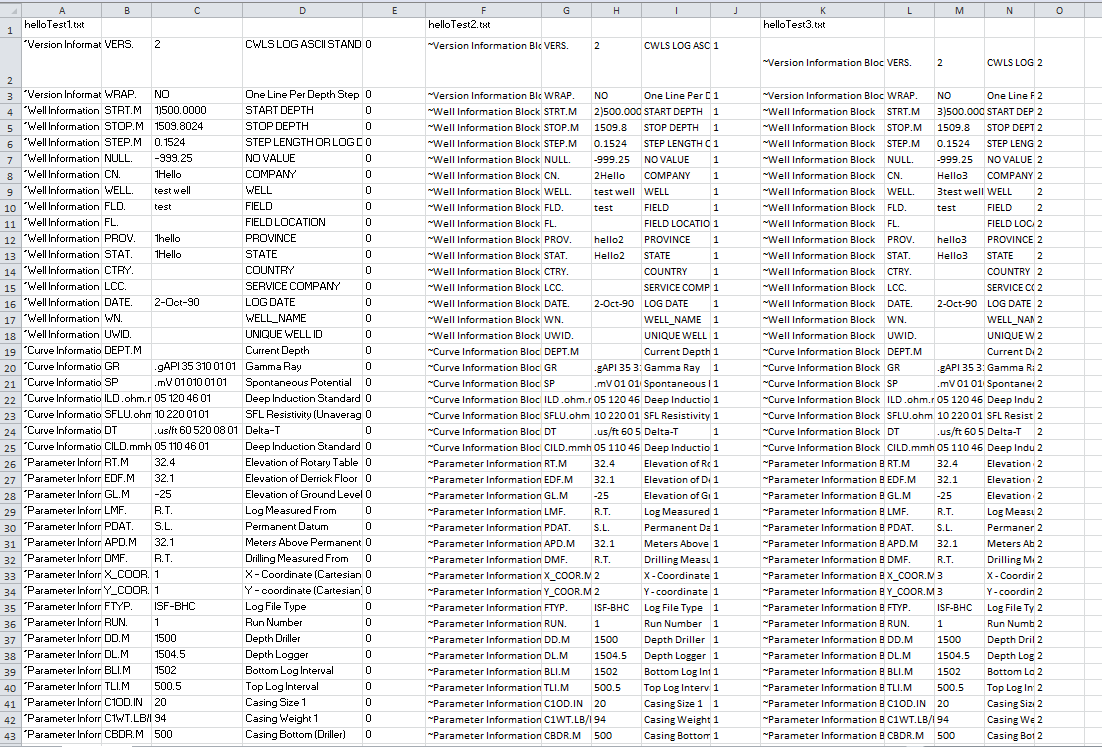
These files can be read by File Reader and placed in a break down of 1 columns and rows for each line of text in the data. An example of .las is opened in notepad shown here.
Is this something I can do with the manipulations nodes under the Split and Combine Folder or will I have to write a python or java snipping script? The settings for cell splitter are not quite for what I’m looking for.
It looks like the first thing to do here is to deal with multiple whitespace on your rows. @MH posted a good approach for this earlier today:
Once you are down to a single space delimiter, you can use the Cell Splitter node more easily. This probably won’t get you 100% of the way there, but hopefully it helps.
Hi @ScottF
Thank you for pointing me in the right direction. The string manipulation node works very nicely. However, When suing the column splitter and using spaces at \t to separate the column. It only repeats the column over again with brackets ? does the cell splitter repeat split cell for every row? It did not create a new table, only repeated the column over.
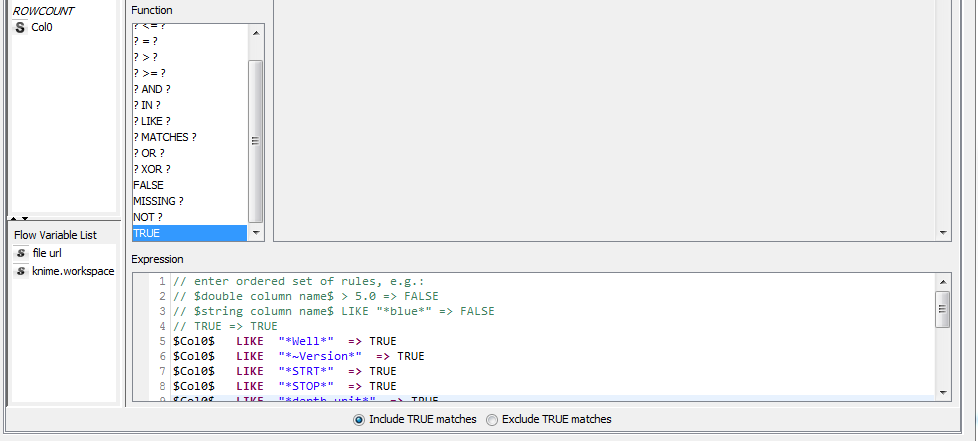
In addition, is their a Rule Base Row Filter expression that select select rows bounded within a rule?
Fore example, in the expression window I would like the row filter to exclude everything from ‘~Well Information Block’ to ‘~Curve Information Block’?
I’m not sure I fully understand your questions, but I’ll try my best.
The Column Splitter node is going to split columns into separate tables entirely. I don’t think that’s what you want to use here. The Cell Splitter node should work to split each row into columns, but depending on how your white space is formatted, you might need two of these nodes - one to deal with spaces, and one for tab characters.
As for splitting the data into separate tables by row, you have a few options here. One is the Rule Based Row Filter node that you have already tried. I think that should work, but you could also use the Reference Row Filter node by providing a list of Col0 values that match up with ~Well, ~Parameter, ~Curve, and so forth.
If it were me, I would tackle this in these steps: load the data, deal with white space, separate data into columns, separate THAT data into different tables by row, and then rename the columns in each table for clarity.
I don’t know that I’ve addressed your issue completely, but if you’re still having trouble, feel free to post a sample workflow with some dummy data and I’ll see what else I can do.
Hi Scott,
Thank you for being so prompt with assisting me.
I am not sure if understand Column Splitter? Cell splitter could work however I’m afraid it could change depending on the row and I need the column to be consistent with tab delineated data.
For Reference Row, after I add my Table Creator, the node only pulls the rows with the items that match it exactly, not every row between. Is there a command symbol that will explain the node to gather everything in between?
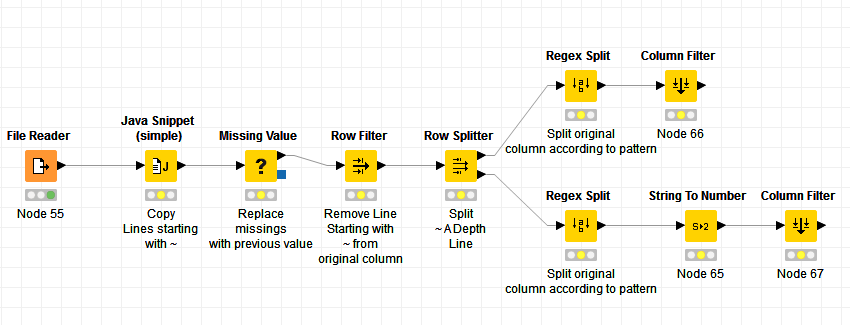
The Java Snippet Node copys the values of a line starting with “~” into a different column. All other rows that do not start with the pattern will be null or missing.
Use the missing value node to remove the missings in the new column with the “previous value” which is the ~Line. Now filter the ~ Lines from the original column. You can now select those sections individually by the newly created column.
I split the table at the “~A Depth…” line cause the table structure seemed to differ from there on.
Create individual columns with the Regex Split Node. The pattern is quite simple: (.*?)\s{2,}(.*?)\:\s{2,}(.*)
Thank you very much, this was super useful and gave me a better understanding for Java Snippet and Regex Split.
The split at “~A Depth” was right what I was looking for to separate the header at the Row Splitter to the main data past “~A Depth”
Could you explain the " (.?)\s{2,}(.?):\s{2,}(.*)" pattern for me? I do not understand that syntax.
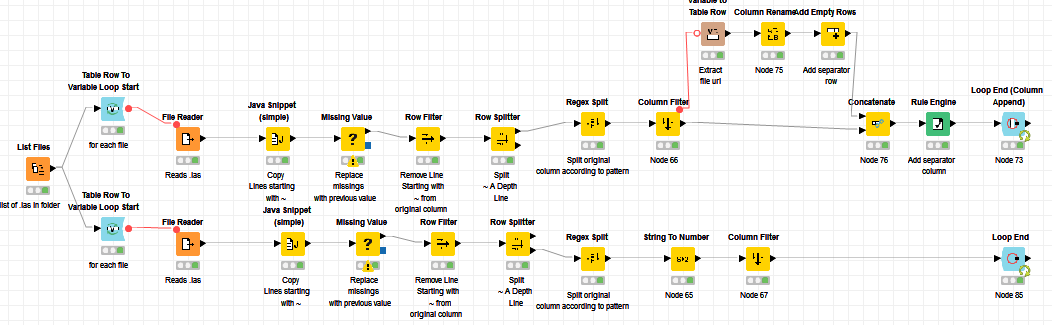
With this similar workflow set as my pre processing, I want to implement a variable loop start loop end to open multiple .las files. Then line the header information next to each other, rotating the rows to a new column. Is this possible with the Transform Pivoting node?(example below) Also by doing this, I dont wan to mix up information and I am trying to keep the URL(or file name) to string incorporated with each header. What is the best way to approach this loop function?
A
B
C
D
E
Pivoting node
A B C D E —( each with a header naming its file name)
With the loop function I created, I noticed that the the same file gets repeated over and over rather than reading the new file from the list and then adding it to the final column at the loop end.
I posted the work flow again. Thank you so much for your help.
Michael
1.) the regular expression consists of the following elements:
. (dot) can represent anything (character, symbol, whitespace etc.) except a line break (per default)
.*? extends the dot to say, represent anything until you encounter the next part of the pattern (which will be the \s)
() The brackets are used to define capturing groups. Everything inside a capturing group will be separated into a different column by the Regex Split Node.
\s represents a whitespace, with the addtion of {2,} it means that it needs to occur at least twice up to an infinite amount.
So the entire pattern basically extracts everything between at least two whitespaces and puts the split contents into separate columns.
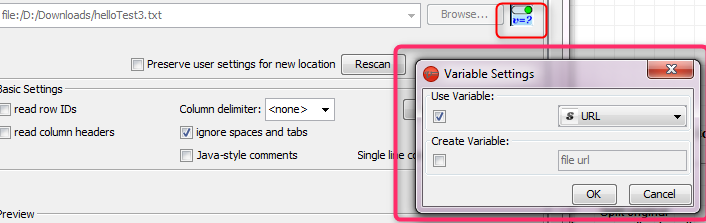
2.) The reason your loop reads only one file is because you forgot to set the FlowVariable “URL” created by the Loop Start, to be the File Input. See the following screenshot:
3.) If you want to work with the file url of the current loop iteration, you can also use the “Variable to Table Column” (or Row) Node, depending on what you want to achieve. Just select the “file url” FlowVariable within the loop to be the variable you want to extract.
I’m sorry but i did not get the rest of what you wanted to achieve. How do you want your final table to look like? What part do you want to transform and what part should remain the way it is? Maybe you can provide an example that is more similar to your current data.
Thank you for explanations over questions 1) and 2)
For my final table, I want to be able to have each data file header lined with the next file. Currently my work flow has each file stacked in chronological order of how they were open in the loop. But it would be easy to read and compare files if they were next to each other. I posted a photo below.
In addition to this, I want have the file name posted at the top of each column.
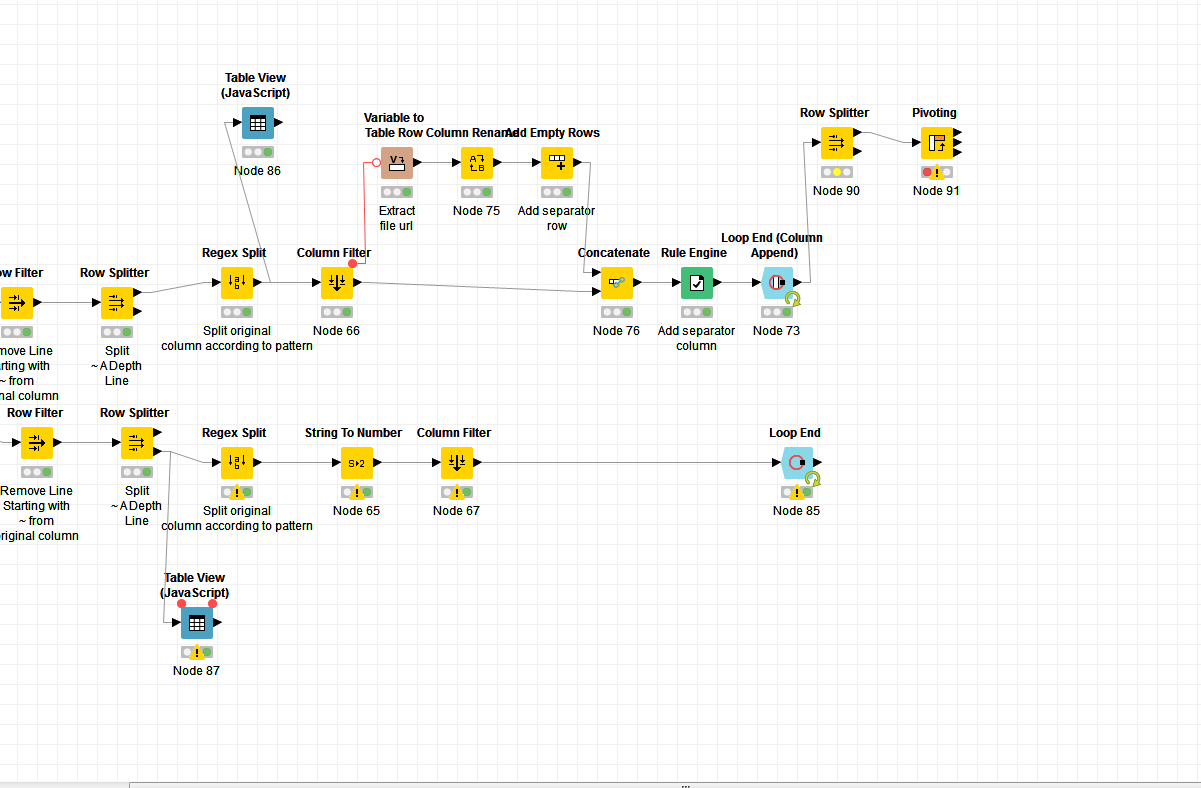
Hi @michaellis, this is doable with a Loop End (Column Append) Node.
You can extract the file url from the FlowVariables in the Loop. Just use the Variable to table Row Node and
extract the file url, rename the column so that it matches the name of your first column and append it.
I added empty rows and an empty column as visual separators, but that is not necessary.
One problem is the loop. You are not allowed to create a branch within a loop. This is why i had to create two separate workflows for the data. Las.file.header.test3.knwf (77.6 KB)
Thank you, This has been very helpful so far. It makes sense to split up the loop into two separate preprocessing steps outside the loop.
And up to this point everything makes sense.
However, outside my test data sets, there seems to be more issues with how the data is read at the Regex Split, which is odd because the format is exactly the same for every file. When I added more files to the folder. The split product gave more unknown values and did not divide the data set. Is this something embedded in the data file instead of a problem with the work flow? What I’m curious is, Is there a way to tell the Regex Split node not to process the data file if does not follow the pattern? Or is there a way to have more variety in the pattern split so you don’t receive errors?46628_VEC_11232_shoot…txt (197.1 KB) 30830__VEC_33-94.txt (196.4 KB) 30837__VEC_36-75.txt (242.2 KB) 30838__VEC_37-28.txt (397.2 KB) helloTest1.txt (652.0 KB) helloTest2.txt (652.0 KB) helloTest3.txt (652.0 KB) Las.file.header.test3.knwf (42.3 KB)
I added the same workflow with the new data files and the old ones attached.
Thank you,
Ok this is because your new files are structured a little bit differently.
In order to make the workflow work on the new data, you need to tweak the workflow in two places.
First change the Row Splitter configuration. Remove the setting “case sensitive match” and add “contains wild cards” then change the pattern to ~A DEPTH*.
The other tweak is necessary within the Regex Split Node. Change the pattern to:
(.*?)\s{2,}(.*?):?(\s{2,}.*)?
The only thing that changed is the last capturing group. This is because one of your files contains 2 instead of 3 columns, which is why i declare the last capturing group to be optional by adding a ? at the end of the brackets.
Great! Is the “*” a deliminator and make everything after the * a wild card? Sometimes I still see the information repeated after the ~ A DEPTH however I think its because its not ambiguous.
And for the Regex Splitter the “?” makes the rule optional for it follows the pattern? I think more ambiguity could help for this info if I run into a different version of the file.Could adding more "? "slow the processing of the node?
A second task, I am trying to manipulate the header data by using row filters and dividing the columns and placing all the information into readable rows. Similar to the photo below
By using the Row Splitter can I only select the top rows containing information assigned to “~Well Information Block” and then line that information into its own single row pertaining to that file?
I was trying to use the pivoting node to shift the data
In addition to my last question the Row Splitter, I am still getting the same issue with the wild card. By using patter matching is it possible to just have rows that start with the character “~A” the A stands for Ascii which can be abbreviated occasionally. Is there a way to right a Boolean combinations of abbreviation for the row splitter by using pattern matching.
After doing a little bit more digging, I finally have a better understanding for using the Regex expressions and patters. The real challenges are how can I create a pattern that doesn’t have to be debugged every time it encounters a slightly altered format format? Weather its 2 spaces or 3, I can control the format of every file for the spacing between columns. The break likes between each section is always followed by ~