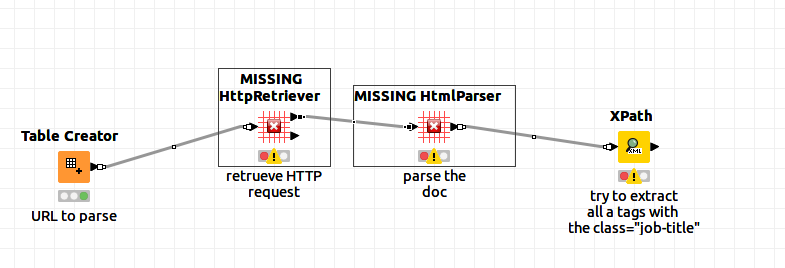
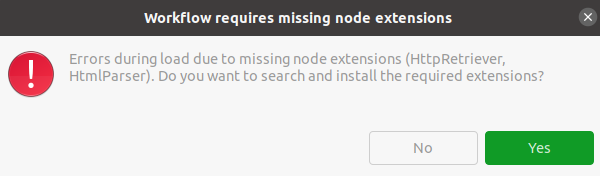
the “HTTP Retriever” Node is contained in Palladian for KNIME. You’d need to add the update site “https://download.nodepit.com/palladian/4.3” as described here
respectively here. Then you can install Palladian for KNIME (or let it install automatically by opening the WF with the missing nodes again), which contain the missing Node(s).
Thank You @LukasS for Solution and it’s Work Properly .
May you give some suggestion about how to start web scraping in knime for beginner.so ,I can follow this and understand the configuration of knime nodes for web scarping and try to implement.
I’m glad it works! I’m no scraping expert myself, but here are some pointers: you can try for example scraping the KNIME Forum or the NYT News feed, but also have a look at this Forum thread. On a first glance, there are quite a few examples out there