I have setup an MLP to predict sales at a retail store 30 days into the future. The MLP learner node has a number of parameters that can be adjusted including:-
Number of hidden layers,
Number of hidden neurons per layer, and
Max number of iterations.
I would like to use “Parameter Optimization” to flex the above parameters and see what gives me the best “accuracy” in a scorer node.
For some reason the “Scorer node” which is comparing “actual sales that occurred 30 days into the future” against “Predicted sales” is having trouble producing an “accuracy value” so I think the parameter optimization is getting confused.
Has anyone managed to get this to work with an MLP? For linear regression I can get it work, but there isn’t much info on MLP’s out there. Any help would be appreciated.
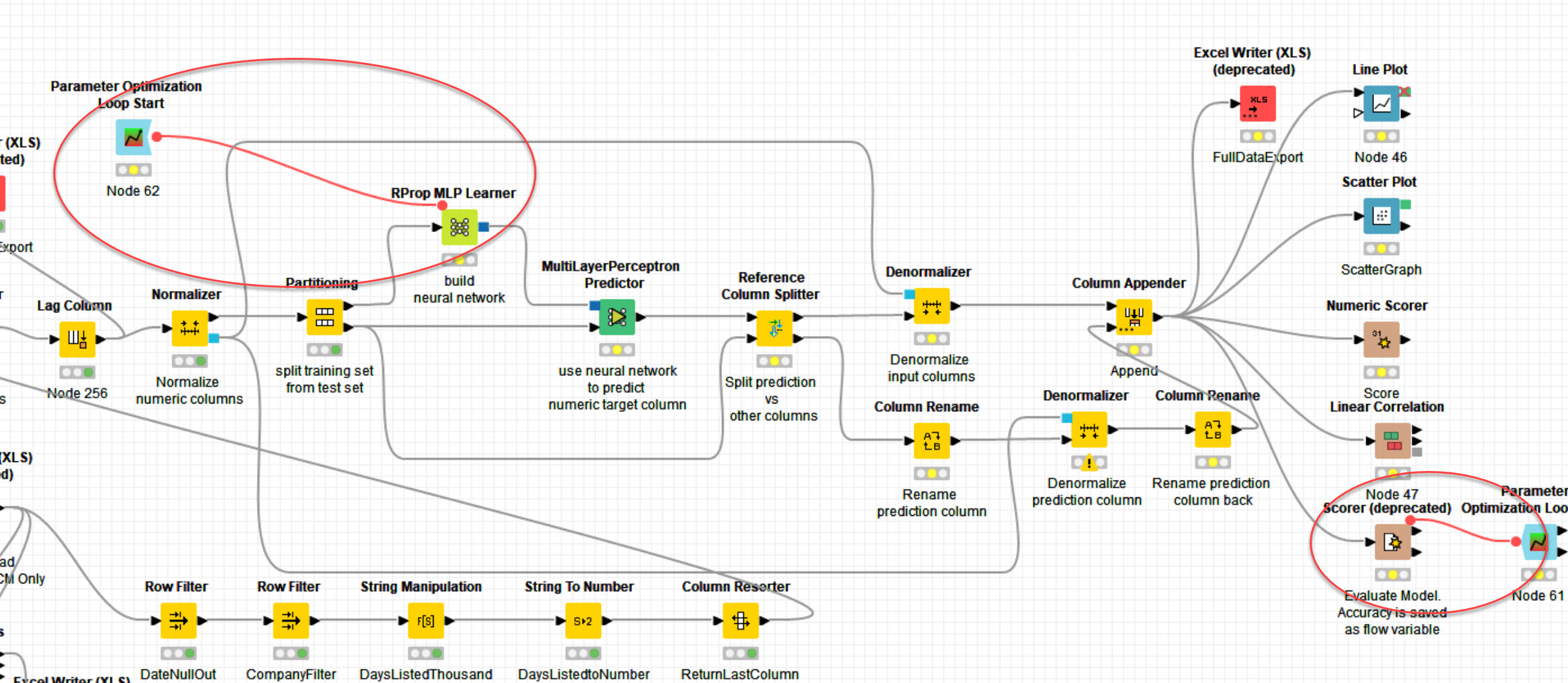
without knowing details, I would assume that you don’t have to do the denormalization steps before applying the scorer - since both the training and the test set are normalized, they can be compared directly. Without being an expert on MLPs, I just tried to apply the optimization loop to a Multi Layer Perceptron – KNIME Hub and it worked just fine. This is the optimization workflow, in case you want to build off of that:
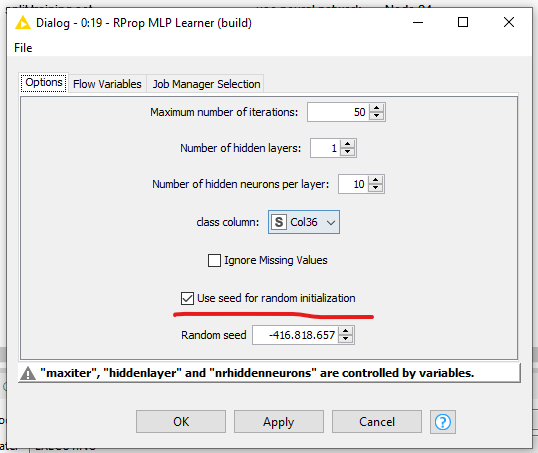
Theres one subtlety: The MLP uses randomness, which makes it hard to compare two different runs. That’s why you’d have to tick the “Use seed for random initialization” option:
In case you want to find the very optimum (I really have no idea how sensible the accuracy metric is in parameter-space), you could use an inner counting loop (and use the iteration n umber as a seed) and take the average accuracy to somewhat mitigate the effects from randomness - I would suspect, however, that this is too much computational effort for too little improvement in results.
I would also argue that an optimization via the parameter optimization route is a questionable Ansatz for MLPs: Isn’t more neurons, layers and iterations always better, i.e. maximum accuracy is reached for an infinite amount of neurons, layers and iterations? Or would that result in over-fitting? So the quantity to would want to maximize is accuracy/learning time (or something like that)? But again, I’m not an MLP expert, so these are just my 2 cents The optimization loop will most definitely give you an idea about how each parameter performs
Thanks for the detailed reply @LukasS. Interestingly my dataset does not allow the “Scorer” node to be used as i get an error message “no column in spec compatible…”. I revert to “Scorer Deprecated”.
The new “Scorer” node does not allow to compare doubles by default (because you have potentially a lot of different values, i.e. a huge confusion matrix). In other words, at least two string/integer/long columns are expected as input, as the error message suggests. You can use the “Number to String” on your double columns beforehand to get back the original behavior (if you are sure you have a low finite number of different values in these columns - otherwise the view takes quite a while to load)
If you normalize before the split you take the test data into account when calculating the values for normalization. That is data leakage which we want to avoid
br
 The optimization loop will most definitely give you an idea about how each parameter performs
The optimization loop will most definitely give you an idea about how each parameter performs