I’m trying, and failing, to figure out how to use the MLP predictor to create some simple what-if scenarios.
I have 3 numerical variables generating a numerical target (so regression) . I might add additional input variables when I have the workflow running properly. The predictor works fine on the partitioned test data. In parallel I also take the full input dataset from before the partition and run the predictor on that. So I’m happy with the MLP model and predictor.
I now want to use the model to analyse different scenarios and would be grateful for help in how to do this. As an example use case, I would like to be able to input a single row of input variables (using table creator) and generate the model prediction. So input 3 numbers, and output 1 number. How can I do this?
I’ve set up a small workflow with “table creator” for the input variables then “math formula” with manually entered calcs to normalise input based on the normaliser model from the learner workflow, but is there a way to do this without the manual step?
A follow on question - using the network model data to run calcs gives different answers to those from Knime. Have I understood the model data correctly?
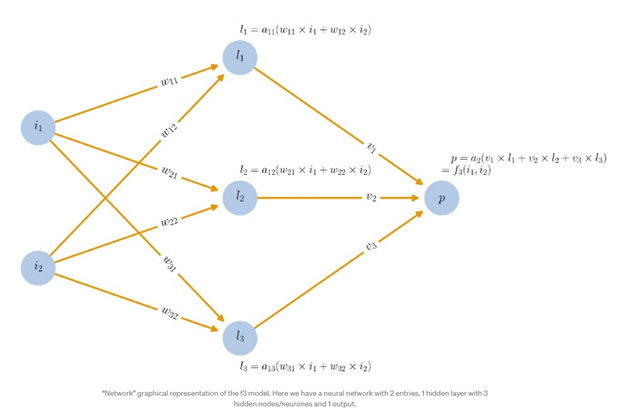
I set up a simple data set and model with 2 inputs, 1 hidden layer with 3 neurons, and 1 output (as in the model in the attached image).
An extract from the Knime neural network data is:
|NeuralLayer
|Neuron id|1,0 bias|0.232956752|
|Con from|0,0 weight|-2.137778058|
|Con from|0,1 weight|0.519551589|
Comparing this to the attached diagram, I’d assumed that “w” (weight) in the diagram = “weight” in the data, and that “a” (activation function) = “bias” in the data?
But if I run calculations (in Excel) I get different answers to the predicted values from Knime MLP node.
For info in case anybody else has same questions:
For my “part 2” question: a node value = σ(w1.i1 + w2.i2 + … + wn.in + “bias”), where σ is logistic function and = 1/(1+e^-x) [where x is the sum of the weighted links + bias, as above).
For my “part 1” question, I found the “Normalizer (Apply)” node which has a link for the model map from the original normaliser node (the blue square output/input connectors). But this still leaves me with the question of how do you use a model to predict values when new input data are outside the original data ranges used to “learn” the model? Thanks for any help with this.