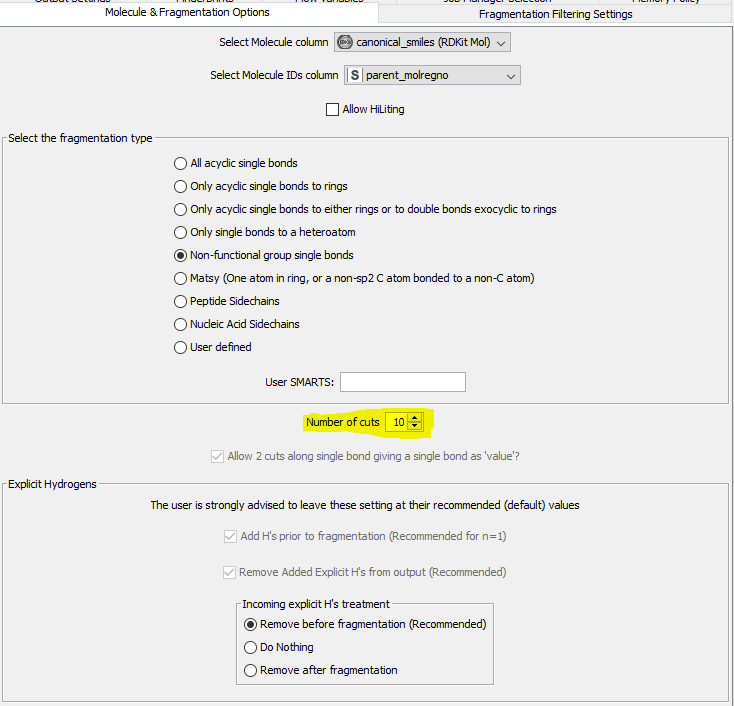
Am a bit puzzled by why the MMP Molecule Fragment (RDKit) node yields an empty table from approx 7000 hERG inhibitors that I pulled from ChEMBL. The node chews on the data set for quite some time, is stuck at 86%, then finishes…but without any results or error messages. All output is directed to the second port and states ‘No fragmentations generated’ for all compounds. I use the ‘non-functional group single bonds’ setting, rest is default. As far as I know all my structures are devoid of counter ions, unique, and have unique identifiers.
The version I have is 1.26.0.v202003171242 running on Windows. I noted that the node itself is plain yellow, i.e. it doesn’t have the red-green-blue diamond graphics, while the succeeding Fragments to MMPs node has this.
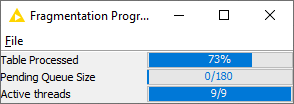
A couple of points - when the node was hanging on 48%, if you look at the node view (Right-click on the node and select View: Fragmentation Progress then you can see that the buffer of processed rows has filled up - this happens when there is row which is taking a lot of time to process. In the example below, the pending queue is empty - i.e. all the rows processed have been added to the output table:
Also, you dont actually need the RDKit from Molecule node - the MMP Molecule Fragment (RDKit) node will do the conversion from any of the common formats for you directly.