hello people…
I am working with tables from a postgres database, I have these queries;
1-the bases have 4 and 16 millions of regristos
what steps do i have to do to work on a data model?
i want a model to be able to design the transformation, groupings, joins etc.
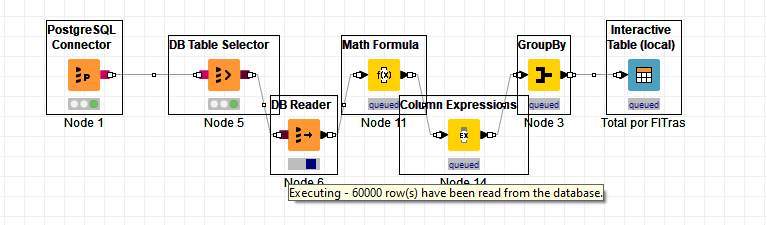
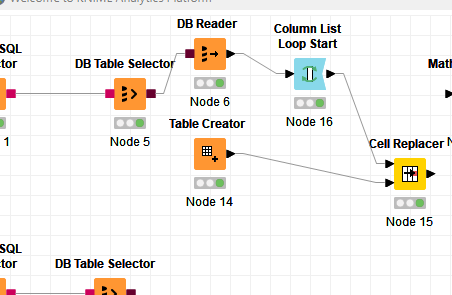
I am passing a model of what I have put together.
The database reading node, has a exesivamtne long time, I want to shorten it to make the model and then leave it running… (as I am very new I have a lot of errors and mistakes to correct).
can be in English or Spanish.
KNIME tiene una comunidad hispanoparlante muy activa si prefieres expresarte en español. Si asi es, quizás sea preferible que nos escribas en esta lengua.
Con respecto a tu solicitud, nos haría falta un poco más de información para saber exactamente lo que quieres hacer. Personalmente no me queda muy claro. Por ejemplo, seria de ayuda que subieras aquí un poco de la data para que veamos de que está hecha. Según lo que veo en tu workflow, estas leyendo una sola tabla. Quizás una opción fuera hacer las cónsultas (queries) en PostgreSQL directamente con los nodos dedicados a ello en KNIME, para que así las operaciones sean más eficaces. Es una sugerencia, pero estaría bien conocer al menos la estructura de la tabla que quieres leer y la configuración de las operaciones.
Gracias por tus comentarios y guía, con lo que respecta a expresar en Español, mejor…
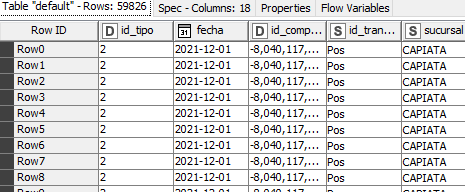
sobre la solicitud, mira sobre al data es muy sencillo es cabecera y detalle de ticket Caja
cabecera, datos de los totales, cliente, fecha local etc.
Detalle datos de los SKU (código barra) cantidad y plata…
no hay más de ello.
Al ser de un mes la cantidad de registro se hace de millones, por eso mi pregunta si puedo hacer desde Knime una extracción para armar el modelo de reporte. (que nodo debo de usar)
esto de armar reporte el concepto no es complicado, por ahora es lento dado que lo estoy trabajando en una notebook y entiendo que es un factor de lentitud…
una vez que tenga por ejemplo toda la venta de un día para varios locales, puedo avanzar rápido entre pruebas y errores… es una opción hacer la extracción con una sentencia de sql… a mi gusto prefiero trabajarlo con un nodo (nos e cual)
gracias
Gracias por las explicaciones. He pasado la categoria de tu mensaje al grupo dedicado al español para que vaya directamente a esta audiencia.
Creo que la primera cosa a hacer es limitar el numero de registros leidos desde la BdD. Segun lo que describes, esto no afectaria al objetivo inicial tuyo que es general un reporte.
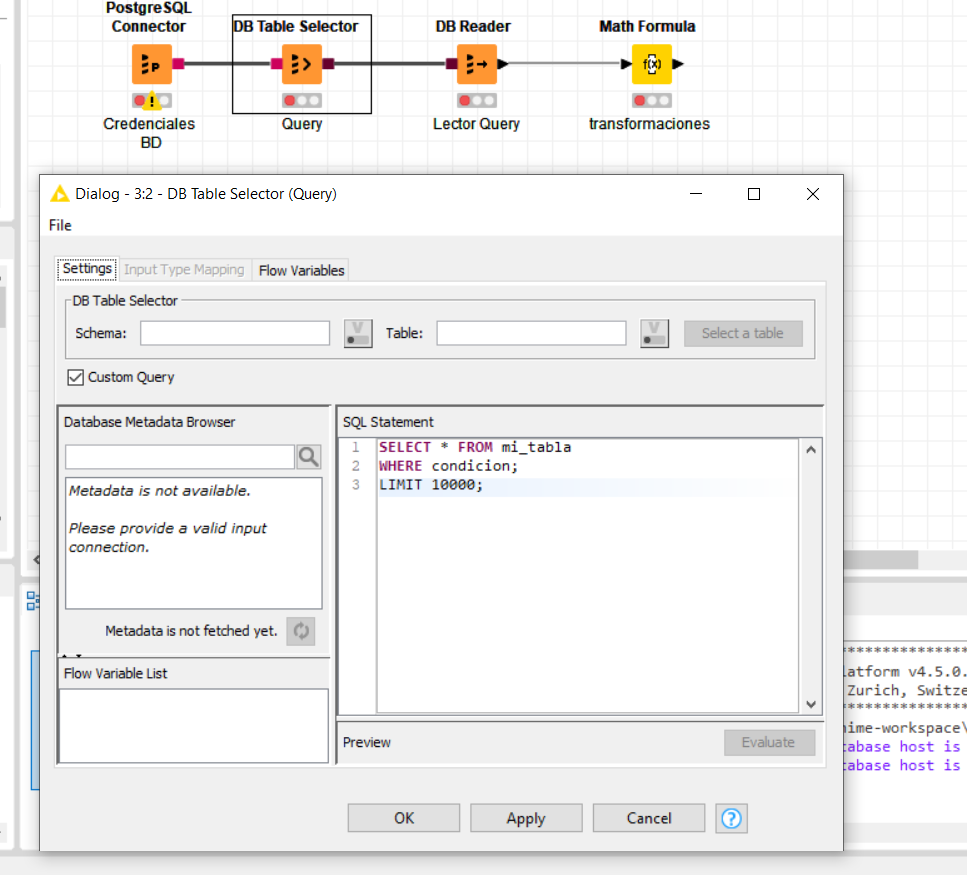
Para ello, te seria posible postear aqui la consulta Posgre que has usado en el nodo -DB Reader- ?
Hola!! siguiendo la sugerencia que te hizo @aworker tendrías que configurar el nodo “DB Table Selector”. Para esto señalas la opción “Custom Query” y de esta manera habilitas el panel de consulta personalizada; así te traes nada más una muestra de los datos mientras construyes el reporte que necesitas en Knime.
Una vez tengas todo el flujo diseñado , editas la consulta y dejas que pasen todos los datos de la base. Espero sea de ayuda!
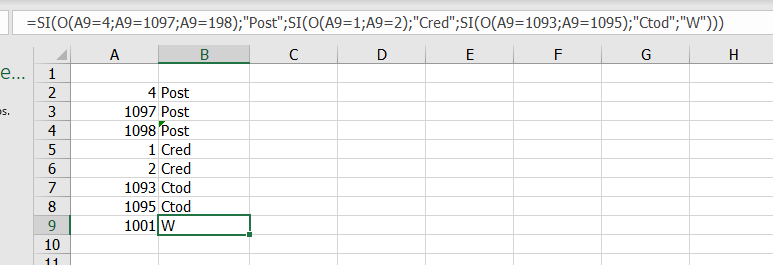
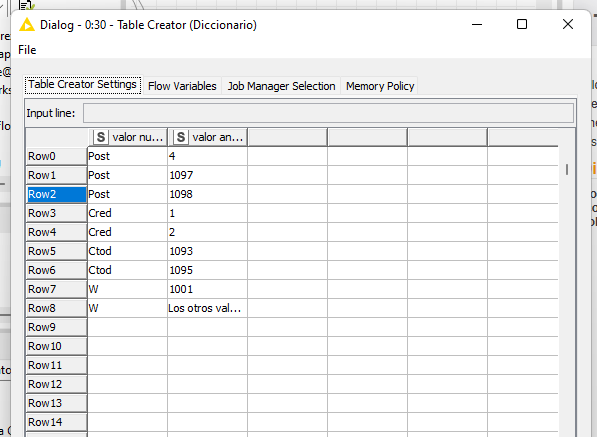
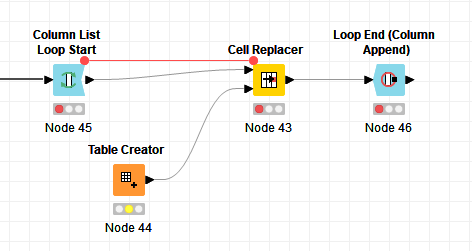
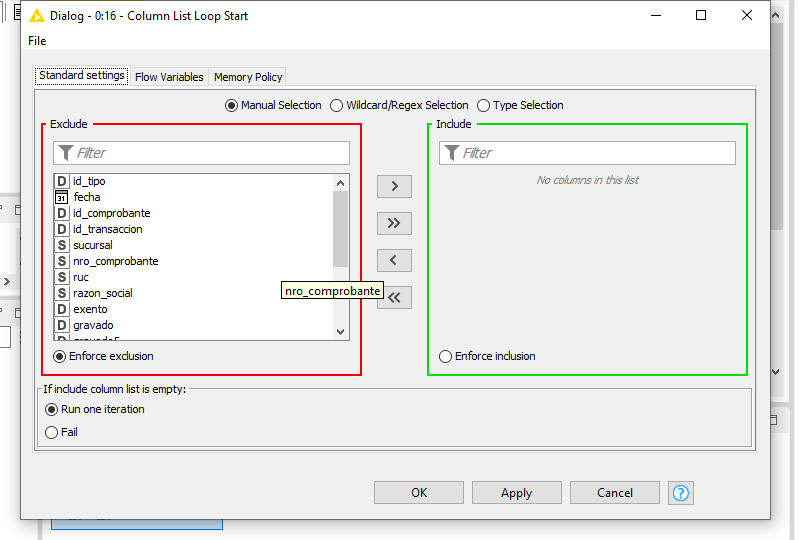
Me alegra que te funcione. Si, el column list loop (que debe terminar en un loop end (Column Appender)) es para repetir el proceso en diferentes columnas (si es el caso).
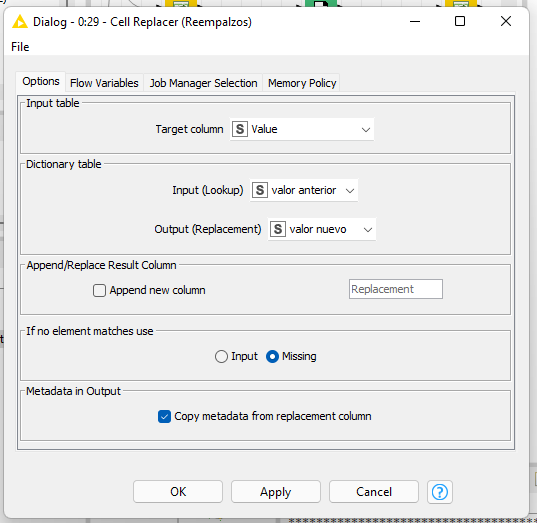
Recibe de entrada tu tabla con los datos. La variable de flujo que sale del nodo Column List Loop Start es la columna actual en la iteracion, en el cell replacer, la columna a reemplazar es definida por la variable de flujo
Observa que, como lo dice la descripción del nodo del loop, es conveniente hacer previamente un filtrado de las columnas sobre las cuales no se va a hacer el ciclo pues, en caso contrario, las repite en cada iteración.