Greetings! I’m back with a problem … again.
I have pulled PSA values from inside my OI (MOSAIQ), and now wish to manipulate the PSA values from these Prostate Cancer patients.
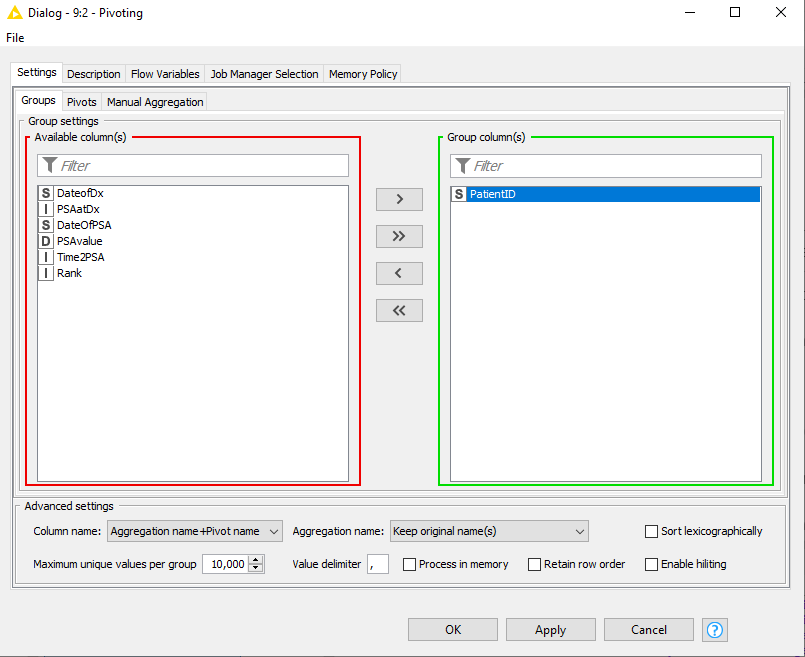
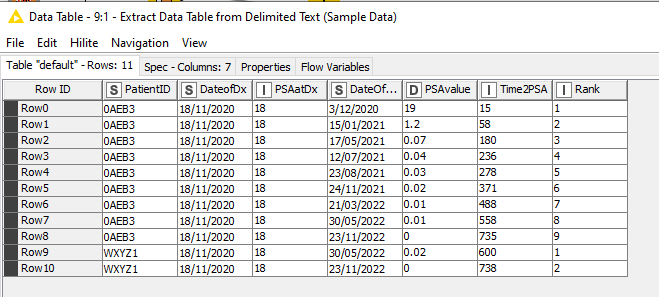
Here is a sample spreadsheet where I have pulled out all of the PSA values (PSAvalue) after the Date of Diagnosis (DateOfDx) with the last PSA preceding the date of diagnosis (PSAatDx), and listed them in temporal order (Rank) with the number of days since diagnosis (Time2PSA) for each patient (PatientID).
| PatientID | DateofDx | PSAatDx | DateOfPSA | PSAvalue | Time2PSA | Rank |
|---|---|---|---|---|---|---|
| 0AEB3 | 18/11/2020 | 18 | 3/12/2020 | 19 | 15 | 1 |
| 0AEB3 | 18/11/2020 | 18 | 15/01/2021 | 1.2 | 58 | 2 |
| 0AEB3 | 18/11/2020 | 18 | 17/05/2021 | 0.07 | 180 | 3 |
| 0AEB3 | 18/11/2020 | 18 | 12/07/2021 | 0.04 | 236 | 4 |
| 0AEB3 | 18/11/2020 | 18 | 23/08/2021 | 0.03 | 278 | 5 |
| 0AEB3 | 18/11/2020 | 18 | 24/11/2021 | 0.02 | 371 | 6 |
| 0AEB3 | 18/11/2020 | 18 | 21/03/2022 | 0.01 | 488 | 7 |
| 0AEB3 | 18/11/2020 | 18 | 30/05/2022 | 0.01 | 558 | 8 |
| 0AEB3 | 18/11/2020 | 18 | 23/11/2022 | 0 | 735 | 9 |
I want these is a spreadsheet where there is one line for each patient (as below):
| PatientID | PSAvalue_1 | Time2PSA_1 | PSAvalue_2 | Time2PSA_2 | PSAvalue_3 | Time2PSA_3 | PSAvalue_4 | Time2PSA_4 | PSAvalue_5 | Time2PSA_5 | PSAvalue_6 | Time2PSA_6 | PSAvalue_7 | Time2PSA_7 | PSAvalue_8 | Time2PSA_8 | PSAvalue_9 | Time2PSA_9 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0AEB3 | 19 | 15 | 1.2 | 58 | 0.07 | 180 | 0.04 | 236 | 0.02 | 371 | 0.01 | 488 | 0.01 | 558 | 0 | 735 |
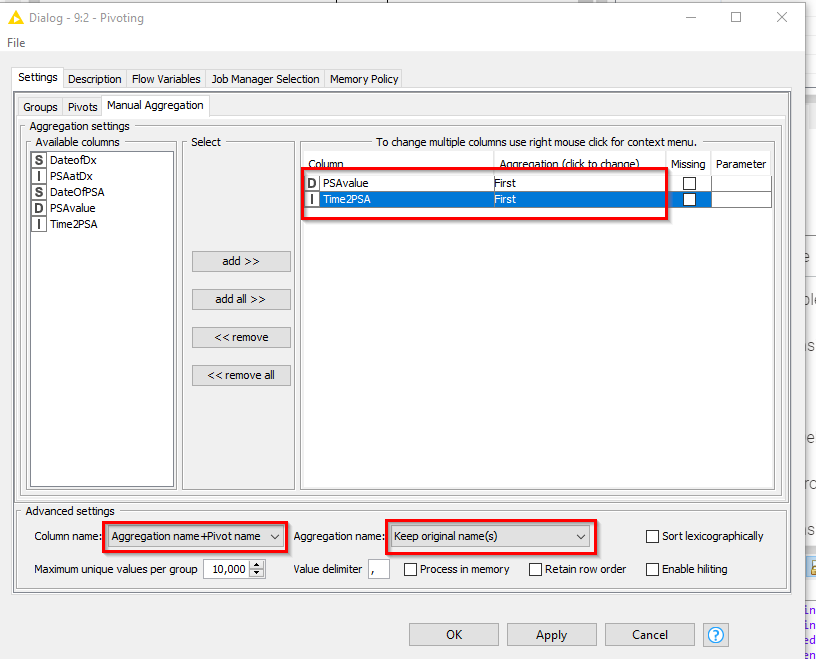
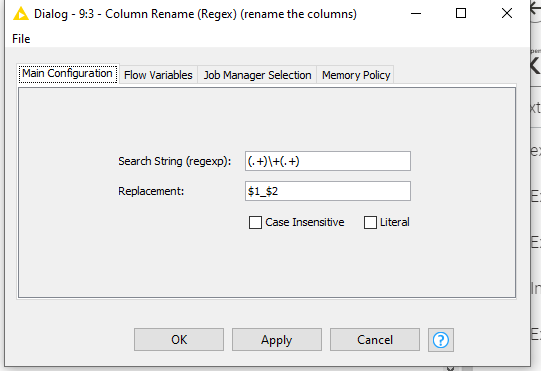
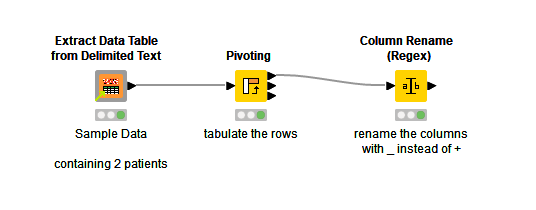
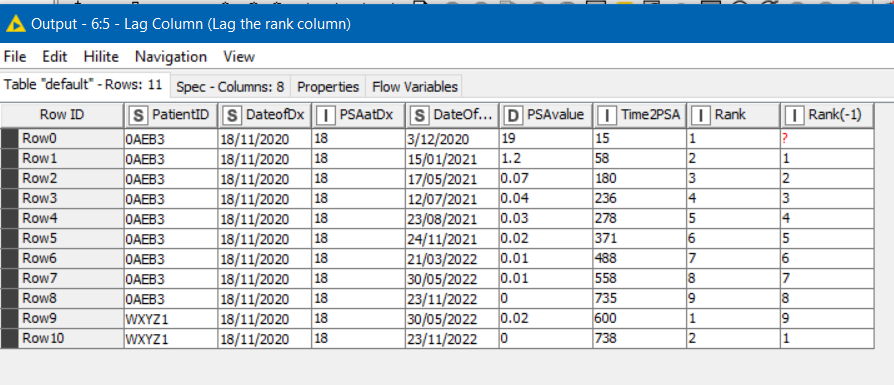
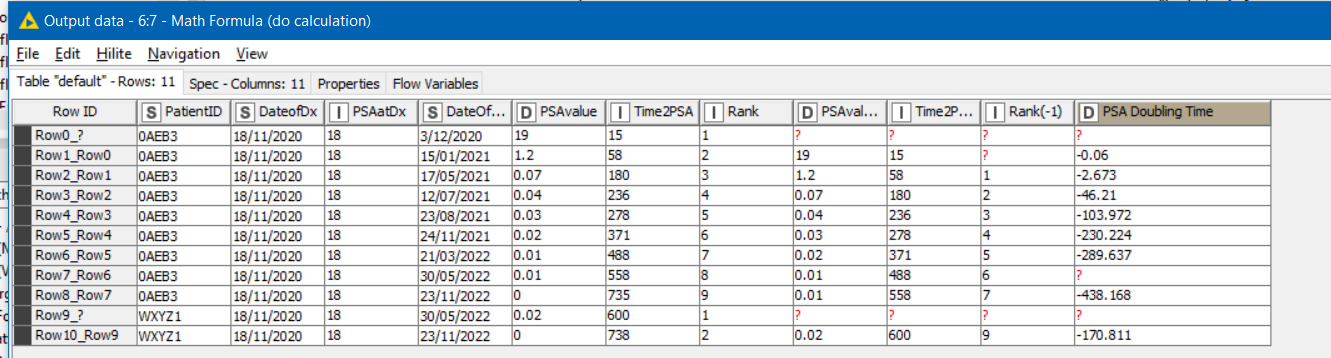
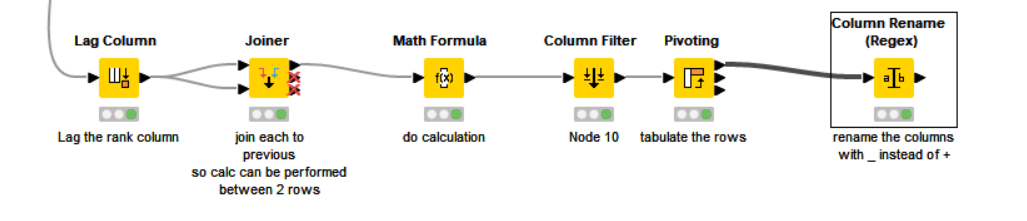
I can do this by using RowSplitter and Joiner, however the maximum number of PSA values and hence iterations of Row Splitter / Joiner pairs is 95!
I’m thinking that there has to be an easier way to do this, hence my request.
Once again , many thanks for the past help.
A
MOSAIQ; OIS; Oncology Information System; PSA