Hi @RoyBatty296, and following on from @bruno29a 's questions, what would the rules be if you have many columns?
If say you had 20 columns, will it be that column 1 and 11 are merged, then 2 and 12, then 3 and 13 and so on? Or is there some other rule that would be followed?
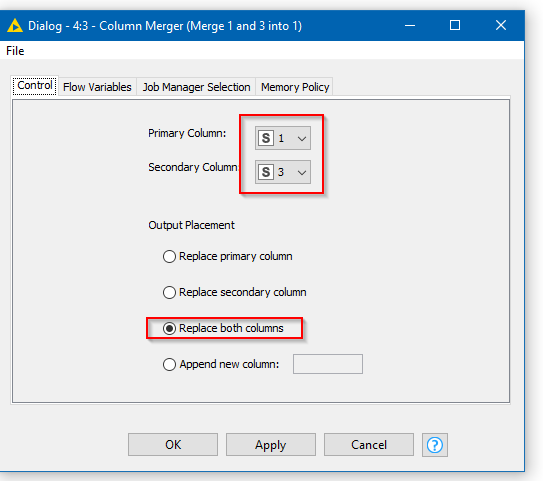
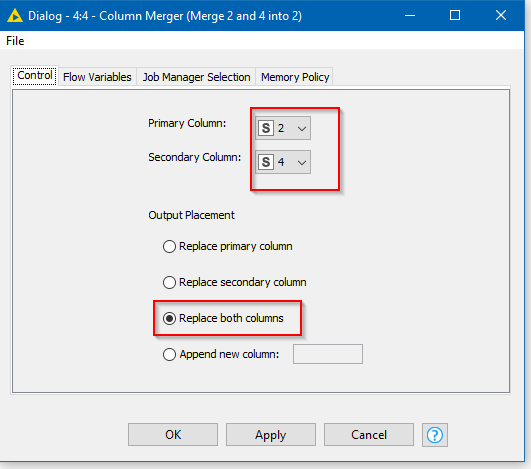
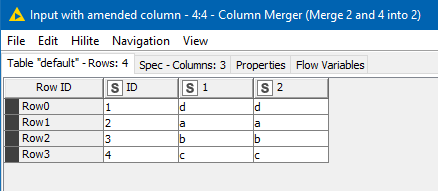
btw, In your example, using Column Merger, you shouldn’t need column filter or rename, if you choose the appropriate options in the Column Merger node
But I can see if you have a large number of columns, that will be painful.
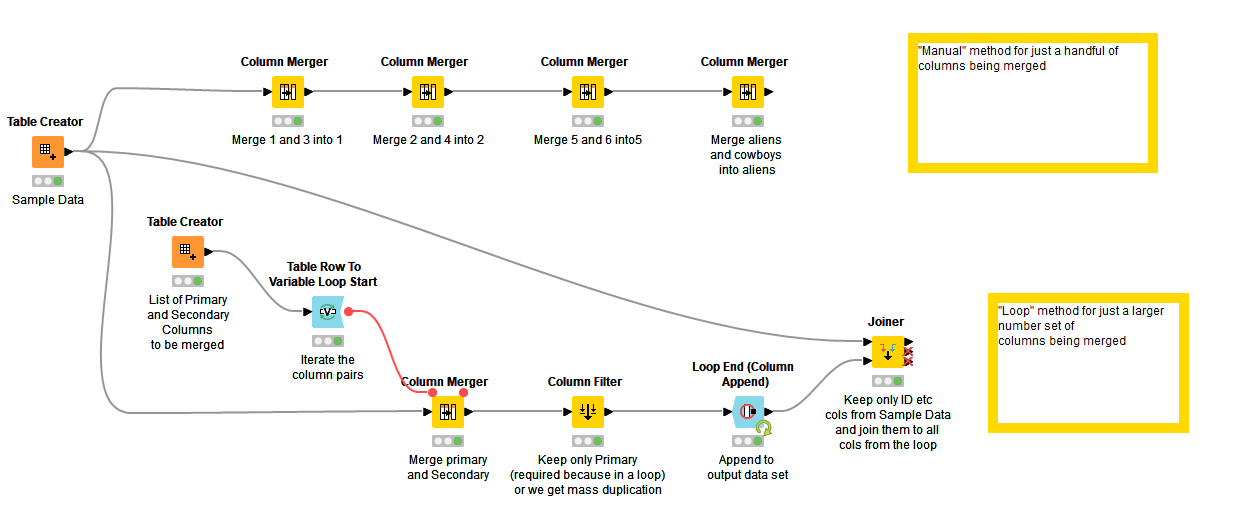
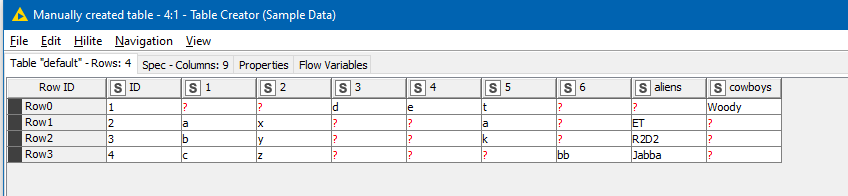
The top part of the flow demos on a dataset how a series of chained Column Merge nodes might achieve what you wish but would be impractical on a very large number of columns.
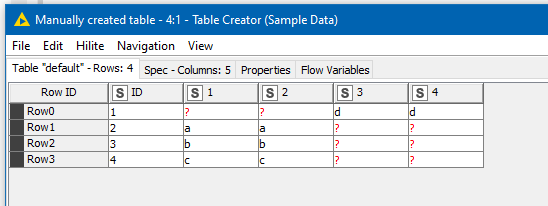
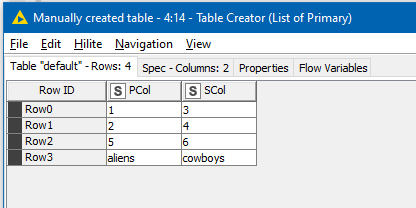
The lower flow performs the same but with a loop. Overkill for a small number of columns but more scalable. Here a Table Creator is used to “feed” the list of Primary and Secondary columns to be used in the merge process. This list could be entered manually, or if your columns have logical sequential names, could possibly be sourced programatically.