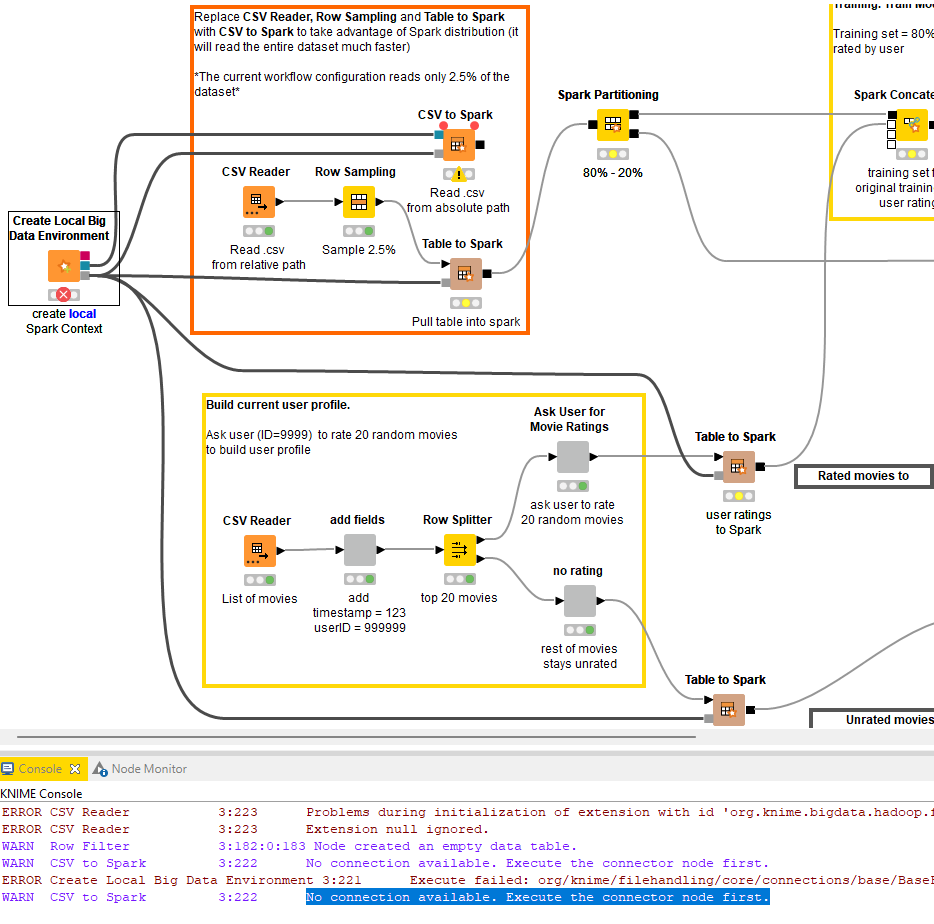
1. Create local Spark Context; 2. Read ratings.csv and movies.csv from movie-lens dataset into Spark (https://grouplens.org/datasets/movielens/); 3. Ask user for rating on 20 random movies to build user profile and include in training set; 4.Train Spark Collaborative Filtering Learner (Alternating Least Squares) algorithm https://www.infofarm.be/articles/alternating-least-squares-algorithm-recommenderlab; 5. Apply model to all other movies unrated by user; 6. Display recommendation results for user
The error message we need more detail on is the one prior to that, about the Create Local Big Data Environment node itself. It says “Execute Failed” with some other info that gets cut off by your window. Can you copy and paste the full error message, or possibly upload your log?
WARN CSV to Spark 3:222 No connection available. Execute the connector node first.
ERROR Create Local Big Data Environment 3:221 Execute failed: org/knime/filehandling/core/connections/base/BaseFSConnection
WARN CSV to Spark 3:222 No connection available. Execute the connector node first.
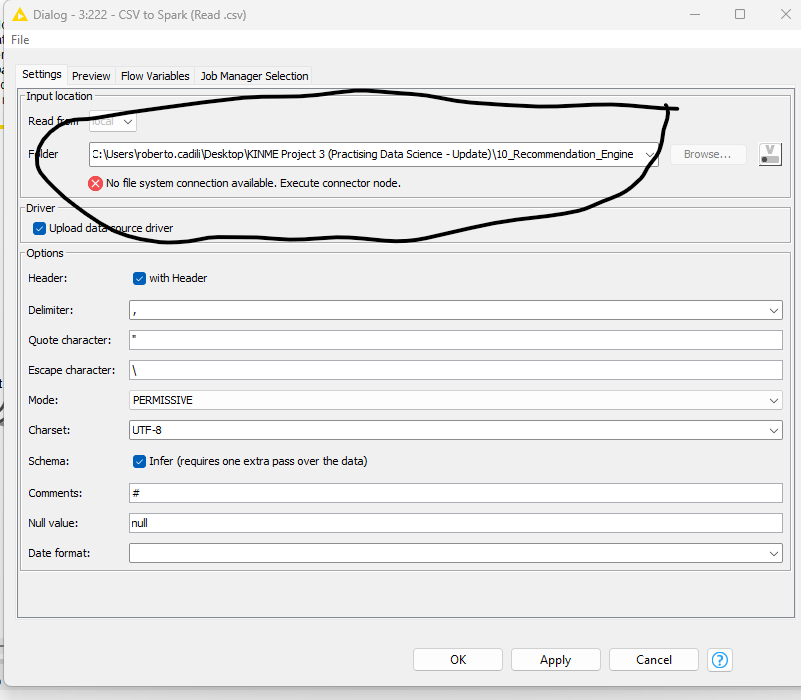
Hi @santoshmd , the node you’re trying to execute had been configured to take on an absolute path to access a file.
From the screenshot image you uploaded, you were able to access the file from the alternative route already, which is the CSV Reader>Row Sampling>Table to Spark route.
As @badger101 mentioned, you need to manually change the path to point to the correct directory, since C:\Users\roberto.cadilli\... doesn’t exist on your machine.