Hi all -
I am trying to execute a moving sum that:
- has a window length of 8 weeks
- changes based on fields Purchase Year (2022 or 2023) and Relation Name (client names, there are about 50)
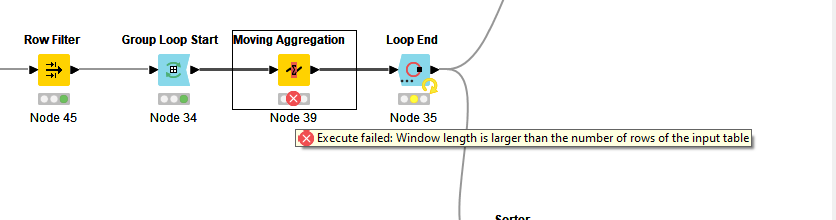
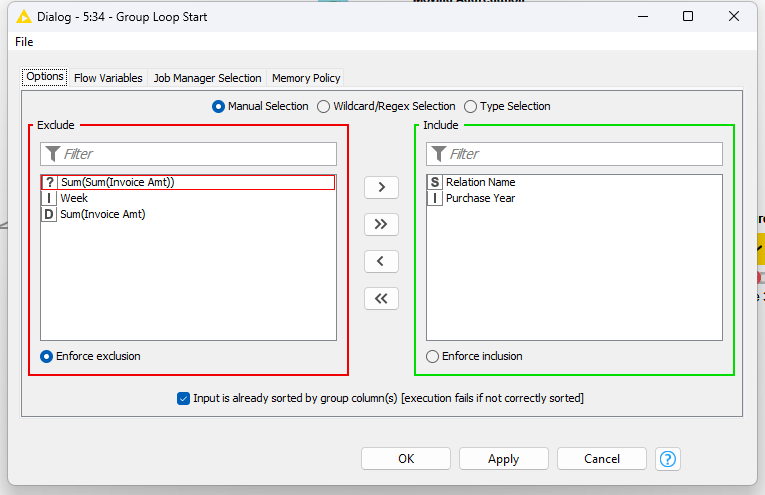
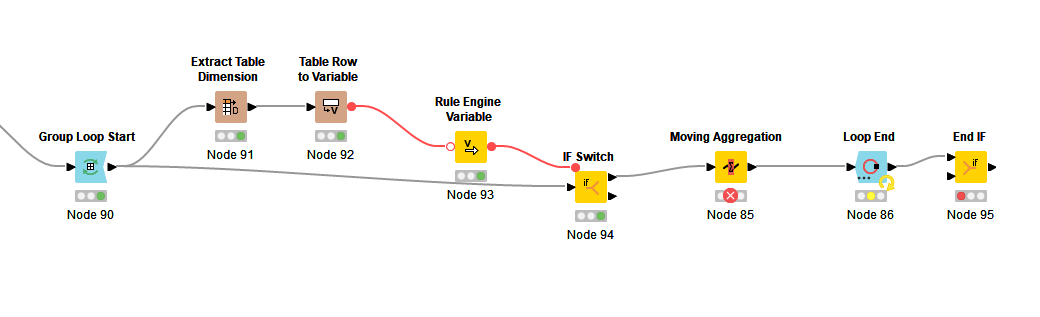
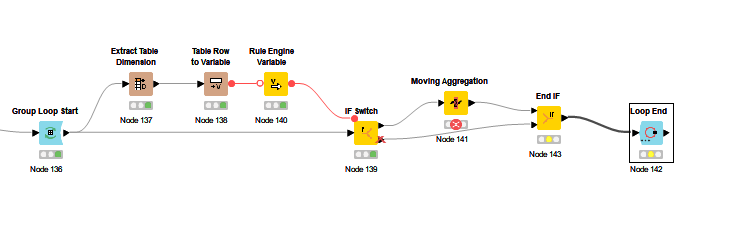
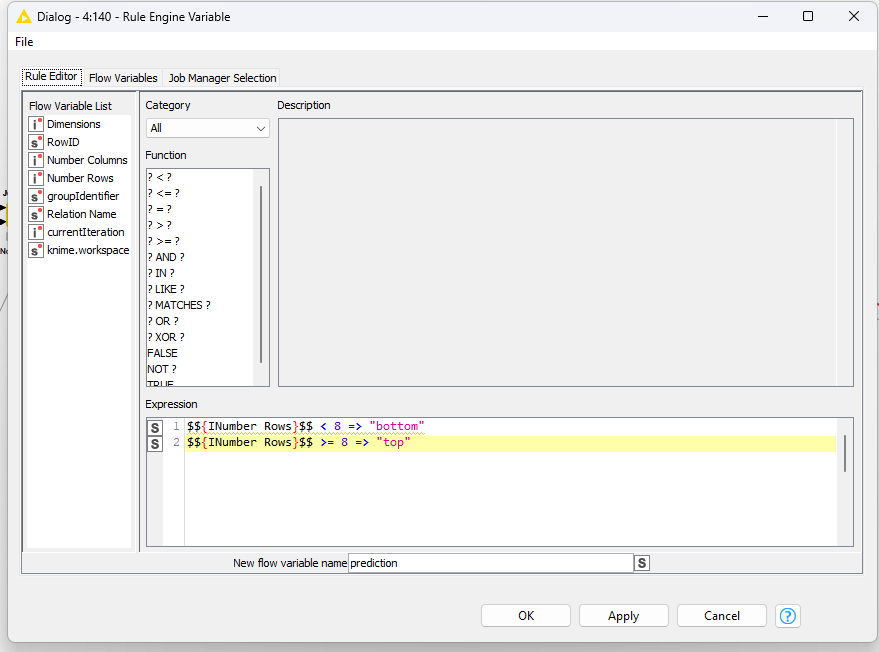
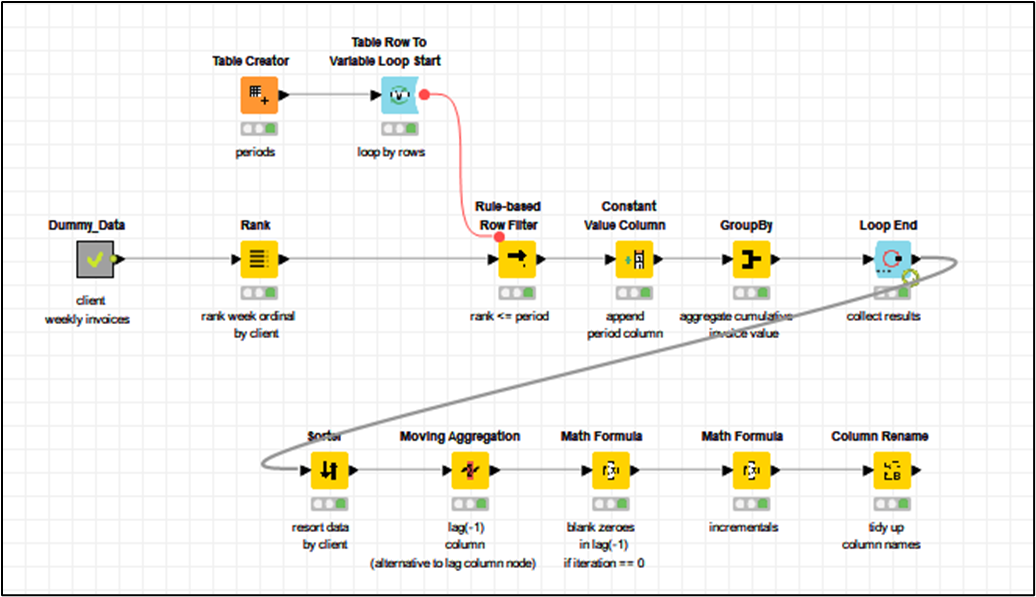
I have the flow shown below, where I sort the fields by: Purchase Year (Ascending), Relation Name (Ascending) and Week (Descending). Then the Group Loop Start where I am grouping by Purchase Year and Relation Name. Then the Moving Aggregator where I specify a window of 8, resolving to an incomplete window if not enough data available, and summing on Invoice Amount. Then the Group Loop End.
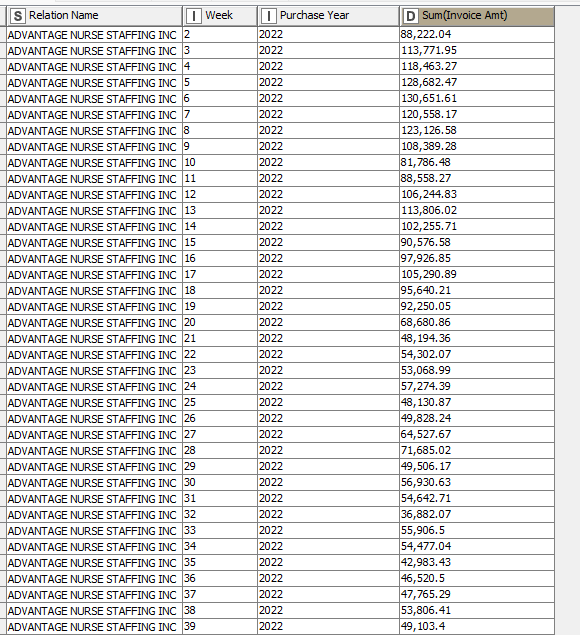
I continuously run into errors on the Moving Aggregator: “Execute failed: Window length is larger than the number of rows in the input table”. Some Relation Names have less than 8 rows of data (they only have 1-5 weeks of records, for instance) and the aggregation is failing. When I check "cumulative computation, the flow works fine. But I need an 8 week window, and resolving missing values to an incomplete window should take care of the problem of less than 8 records. What is going wrong?
It also seems like the Group Loop Start node is only cycling through a few of the Relation Names. I reset and execute it individually to see what’s going on, and only 3-4 of the relation names are coming up in it.