I have a dataset with the closing prices every day for several stocks. For each stock for each day, I want to calculate the average closing price of the previous 28 days and also the average closing price of the next 28 days.
Moving average does not seem to give me a way to do this. I would appreciate any suggestions and links to workflows that are similar. Thank you.
Welcome to KNIME Forum. See what the Window Loop Start node followed by a GroypBy node can do. In your case you need the loop twice (previous and next).
Can you share a dataset with an (anonymised) example? From what you explain honestly that is what Moving Average with a Window Size of 28 should do. You may have to use the Moving Average node inside of a loop (Group Loop Start Node) and you will have to make sure that the data you pass into that loop has been sorted first by stock, second by date. The Moving Average Node simply goes backwards (or in your case also forward) 28 rows from the current row - it doesn’t make any checks whether the previous rows belong to the same stock or related to previous/next days…
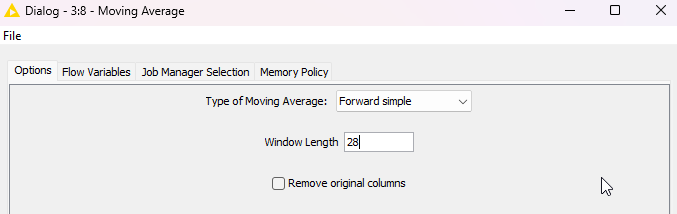
In Moving Average Node I think any “Forward” Method should do the trick for the the average of the “future” 28 days, and “Backwards” for the past:
The data set is 2GB – daily stock prices from 2016 through 2022. I can shrink it for testing, but first it’s worth noting that I get an error message on Moving Average: “Execute failed: Number of total samples in time series smaller than moving average window length!”. This is within a loop that (in theory) is getting all the daily prices for one stock at a time.
I finally figured it out. The solution was to use Column List Loop Start and Moving Aggregator within the loop. What made this different is that essentially it was calculating a moving average for multiple time series, one for each different security.
Great that you managed to sort it out yourself - just a note on the error: it simply means that the table you are passing into the MA Node has less rows than the configured window size. To avoid that I recommend using group by or Pivot nodes depending on your source data set to check on the “count” of rows for each security. You can then decide to either take the lowest count as your window size or to filter out securities that have a count below the window size. That said when a security has count equal to window size you either get only a MA for one row or the same average across all rows depending on how you have set up the MA node…