Hi,
I am working on a POC on Knime to be implemented as an ETL tool. I have a requirement in which I need to process files(loop through) that are delivered in S3 bucket and load it in Redshift and after that move the processed files(One by one in the same loop) into another S3 bucket. I am not sure how to move the files within S3 as a part of the loop one by one.
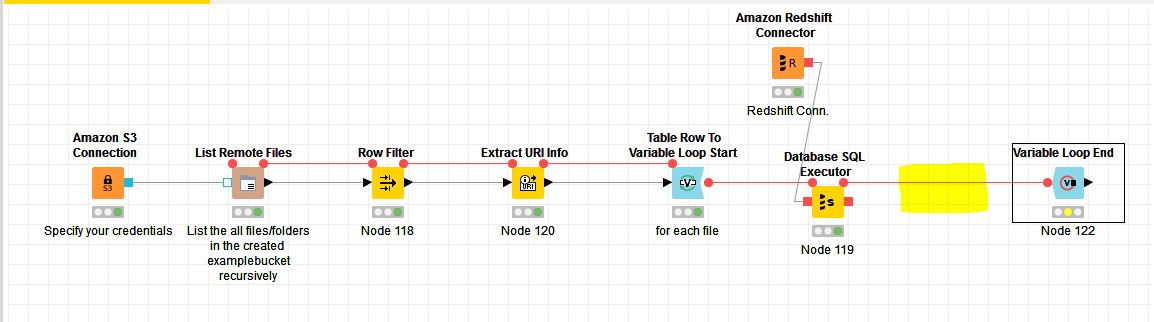
In the screenshot attached I am able to loop through the files and load them into Redshift in sequence.
I need to know how to use a component to move files between S3 buckets.
I am not sure whether I understood correctly. But if you want to save your queries/tables in S3, then table unloading seems like what you want to do. If you want to specify the location dynamically in the loop you could use the String Manipulation node to build the query for the unload statement and then pass it to the Database SQL Executor node as a flow variable.
Hi,
I think i was not able to explain it better. Let me try again.
We receive files continuously in our S3 bucket.
I need to load those files in Redshift and then move the processed files to another S3 bucket to archive them.
I need to run this process every minute.
To accomplish this I need to loop through the files as shown in the screenshot.
I am able to load the files into Redshift while looping over them 1 by 1 as shown in the screenshot.
The problem exists when I have to include some component(in the loop) to move the files to another S3 bucket.
The yellow marking in the screenshot is where i want to include a component to move files to the another S3 location(to archive processed files). I am not able to get that working with the components available in knime like Copy/Move Files , Download/Upload from List.
So if there is some example that accomplishes my requirement please let me know.