I have like 40 csv files coming from 5 different systems with invoice formation. Every system has a different layout with different data in the csv (some data is similar, but the column names differ). The file names are consistent per system and can be used for selections.
At this moment I have multiple csv reader nodes (one per system) pointing to a folder where are files are located and I use the filter function in the csv reader to process data per system. In the end all data concatenated. I chose this way, so that I can simply update the folder location instead of selecting files.
I would like to have workflow whereby I only need to update the file location once instead of each csv reader node. Subsequently a filter on filename would process the data per system. Finally all should be consolidated.
I don’t understand how it works with setting up the CSV reader in that case.
There’s 2 files for system 1
5 for system 2
10 for system 3 etc
How do I get that the loop to split in multiple output files that I can alter. For example the column names in the files from system 2 are different than system 1 and the column names of system 3 are different from system 1 and 2. I need to rename them per system.
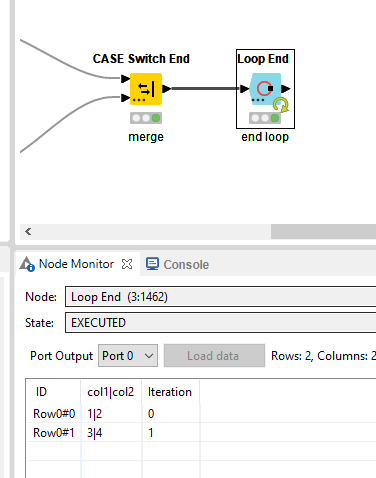
So you would use a List Files/Folders node for each file system, and the CSV reader would read in each one of them from this system. The Loop End concatenates each of these files, so you end up with a table containing all the data from all csv files from that system.
Thanks Alice, but there’s no added benefit of this compared to using the CSV reader. That is already scanning (sub)folders with a filter option on file name.
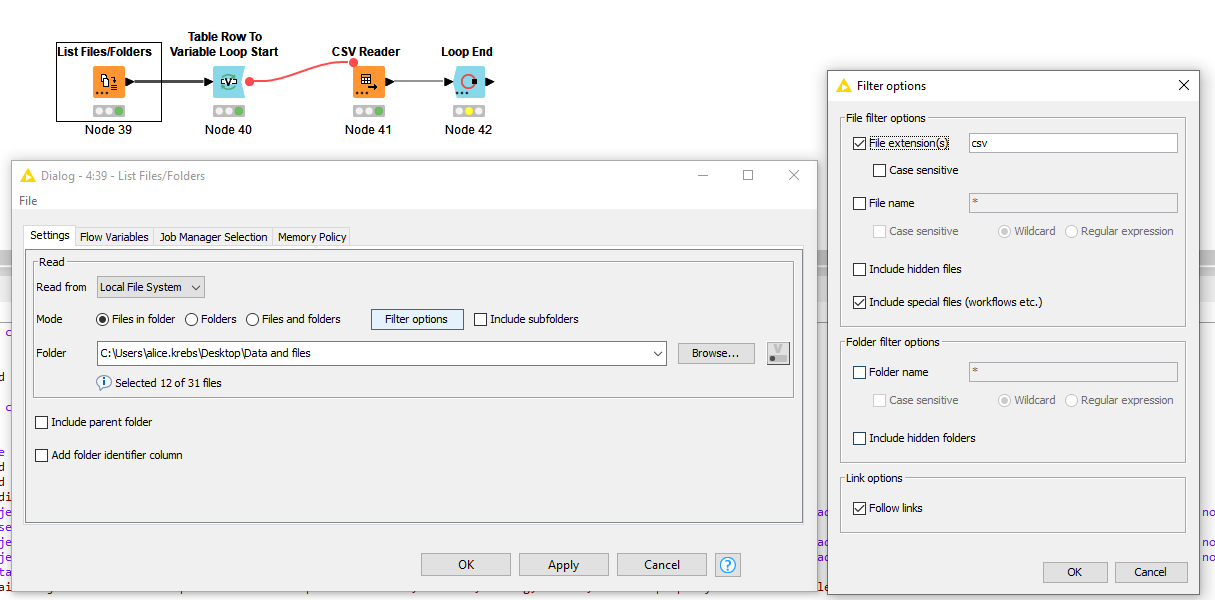
I was hoping it would be possible to list the files, apply a filter on file name so that Knime would pickup the data from the filterd file with a csv reader node. Some like the attached picture, so that I could just update the file location in the list files node and everything flows automatically from there (keep in mind that every csv reader results in difference file adjustments and I need quite some adjustment to each file before I can concatenate).
@robvp maybe you can provide us with an example of what would constitute a system and what part you want to change. You can read various paths and set different flow variables in order to have a dynamic setting. Of course, you can extract paths and file names from the results and filter them later.
@mlauber71
A system is an ERP system in my case.
Each ERP system has invoices recorded in it (sales and purchases). The extracts from each ERP system differs in layout/column names/amount of columns etc, even between sales and purchases is differs. The csv reports from all ERP systems are in one folder and have filenames that tell what system it’s from and whether it’s sales or purchase data.
For every report different data alterations need to be done and finally the need to be concatenated (after alterations have been done). See screenshot below as an example (text below image).
In reality I have like 10 csv reader nodes that I would need to update every month with a new file path for the new files for the current month (the file path is identical for all reports). If possible I’d only like to update the file path at one location only and Knime would - based on filename - execute the actions relevant for that system.
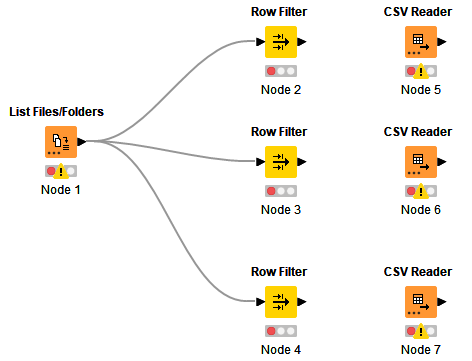
I think you can do that by using the List Files/Folders, extracting the names, filtering them by their characteristics/parts and then feeding them separately into your CSV readers (in a loop maybe).
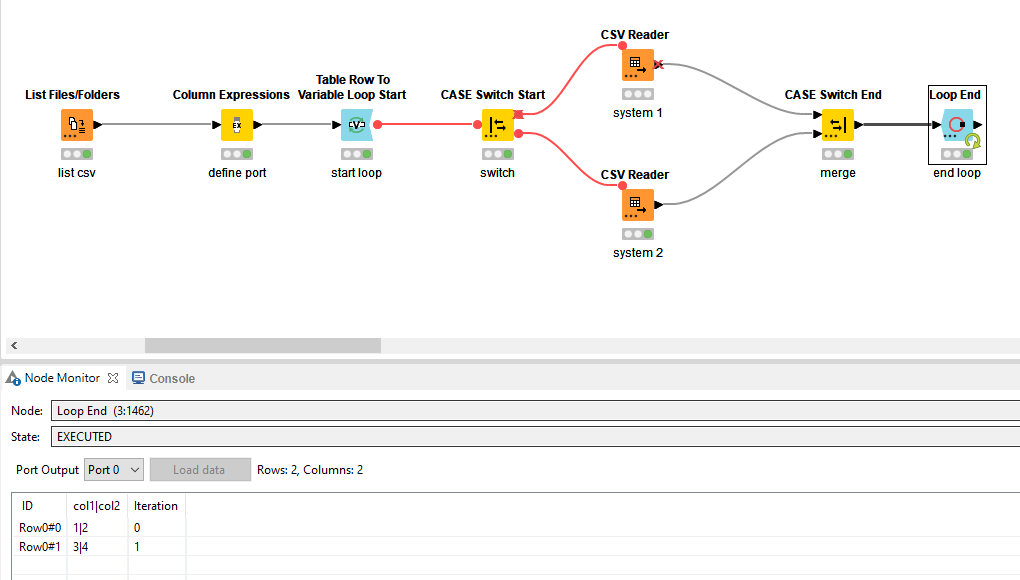
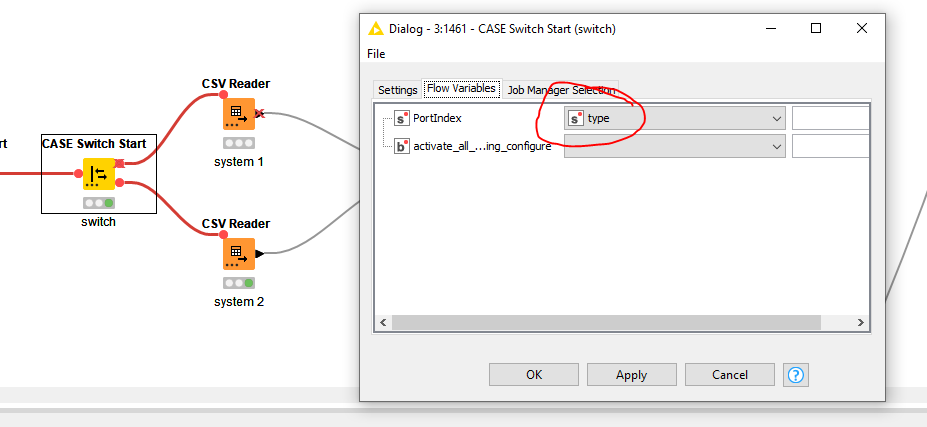
Similar to @mlauber71 his suggestion, have you considered a CASE Switch approach? Since it should be based on the filename, you can assign a port index value with your business rules in mind and then distribute them accordingly to the correct CSV Reader.
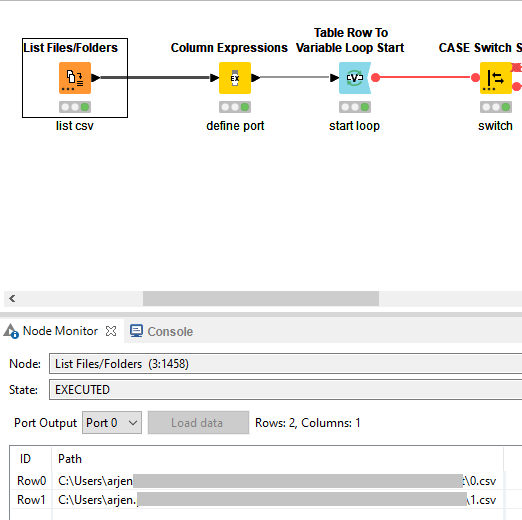
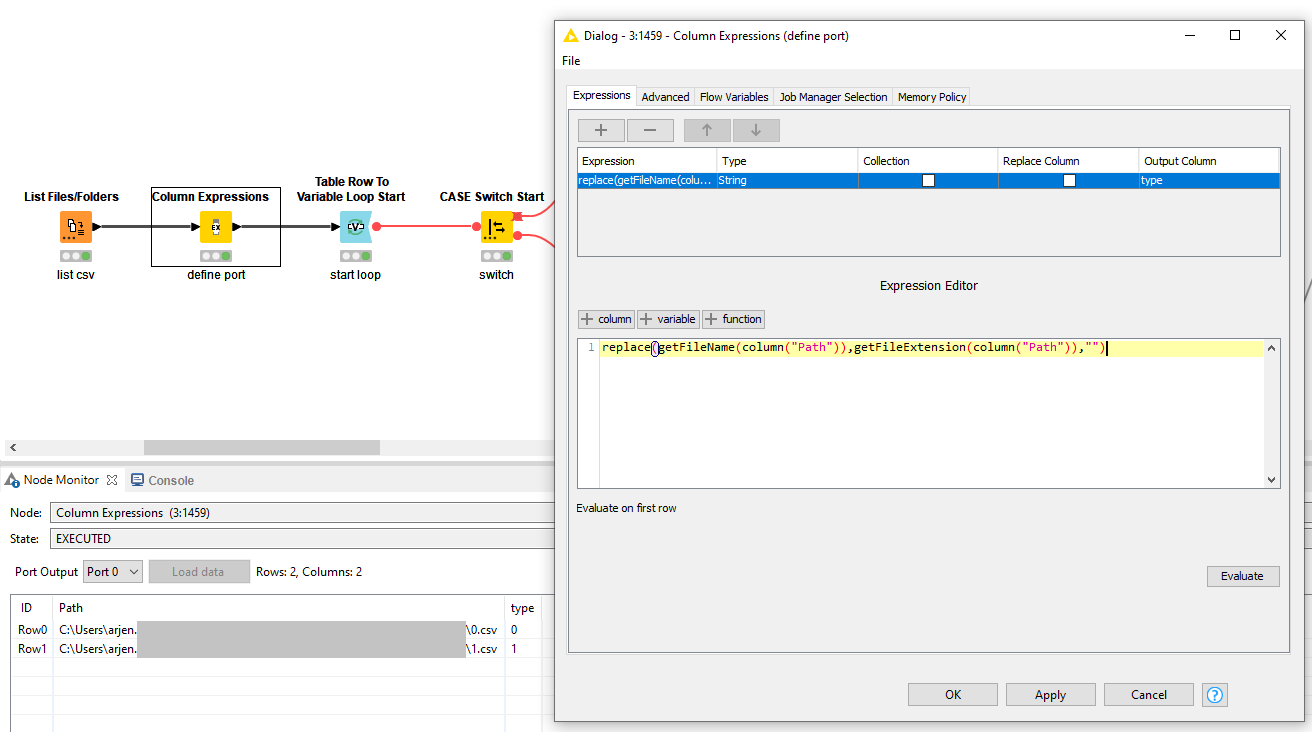
Define the system with a Rule Engine, Column Expression, Java Snippet, etc. In this example case I want to derive the port for the CASE Switch directly from the filename so I use replace(getFileName(column("Path")),getFileExtension(column("Path")),"") Note: the PortIndex of the CASE Switch is of type string.
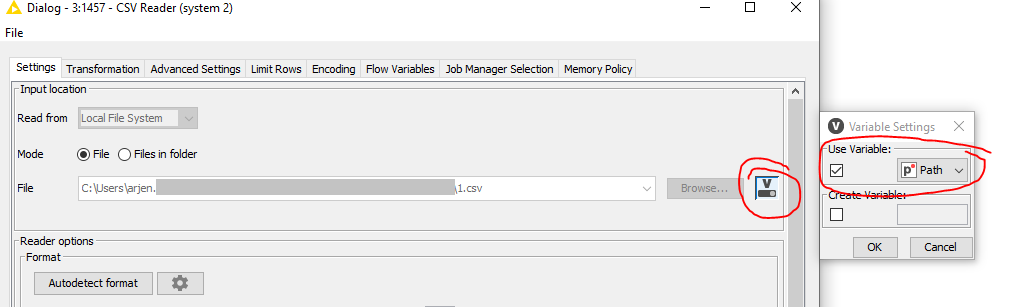
Set-up as many CSV Readers to your liking for each system whereby the filepath is flow variable controlled (Path). Apply the required transformations for each system (which I disregarded here).
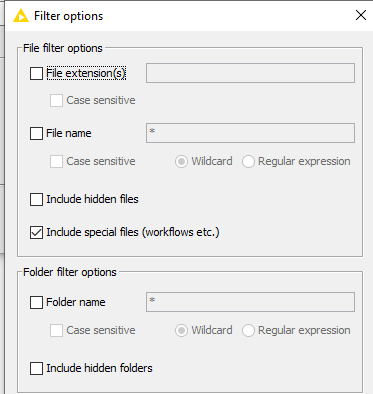
I see there are already a plethora of answers, I just wanted to say that you actually CAN filter for the file name already with the List Files/Folders node. But that requires of course some regularity within the file names of your files
Thanks to all for you help!!
I got it working with your help!!
However, during all this I just found another very simple solution by using node. All files are in one folder and I set all CSV reader to read the entire folder (including subfolders) with a filter on filenames.