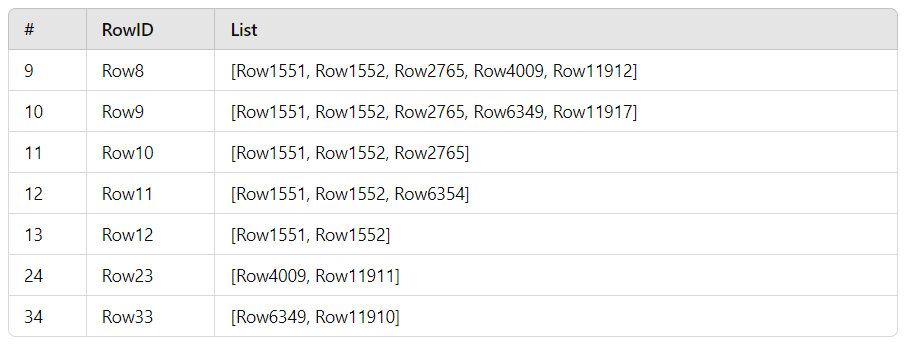
I am attempting to consolidate multiple RowIDs that are all interlinked with each other. They all share at least one (or more) RowID in the List column which would require all RowIDs within that record to be consolidated.
This is one example of my starting data but have several different combinations that would be made, and the overall data size is very dynamic and unpredictable.
All of the rows share a common list number and therefore all list numbers on that row should be included into the consolidation until it is down into one single row.
In the example above this is what the ending should appear to be:
Through my several attempts with Recursive Loop and methods to consolidate the data I have not been successful. The data is currently grouped by RowID as a set.
Any help in developing a workflow to achieve this outcome would be greatly appreciated.
Really need some help on this one if possible, because all of the IDs in the list column have at least 1 number that is associated with another, that means they are all associated and need to be consolidated into a single line and any duplicated values removed.
Can you maybe describe more in detail about how you reached your desired output?
You have Row11910 associated to Row8 but 11910 on its own is not directly related to Row8. So you go through Row6349 which is linked to Row9 and that links to Row8 based on 1551,1552 and 2765?
What about the other rows then? What would be the output of Row11, Row 12?
PS: there is no need to create two topics in short succession about the same topic, next time just bump the original one
Hi @tmac1916 , I agree with @ArjenEX that you need to describe more what the logic is, as I cannot work out from your description what the output should be.
On the face of it, it looks like you are just generating the distinct set of RowIDs from the List column:
But if that is the case, then what is special about Row8 ? i.e. what happens in row # 1-8 (which we cannot see, but presumably exist?)
btw, if you are simply wanting to generate the unique set, you could use the Ungroup node to ungroup the “List” column (if it is actually a List datatype) and then use GroupBy to create a new “Set” (which gives a List but with no items repeated).
Is the logic…
… that for each row, if any element in the List in that row has appeared in a previous row, then all elements from that row’s list should be consolidated with that same previous row. This is why Row8 becomes the consolidation of all the rows shown.
So if, for example, there had been another row, say Row40 that contained [Row500, Row 6001], this would not be consolidated in Row8, but if it contained [Row11910, Row21234] then it would be?
Please would you upload a small workflow containing a sample dataset so that people can have a play without having to create their own. A recursive loop should certainly be one possibility for handling this provided we know the rules.
This is only a sampling of the data set. Rows 1-7 are of different data. But what we are trying to do is consolidate the rows that have a similar Row number, in the example Row8 is the top row found therefore it would be the one that is updated. But we are basically merging these rows together and then removing the duplicated values.
So Row8 shares List numbers 1551, 1552 & 2765 therefore List Number 6349 and 11917 are merged.
Now that Row9 which containing List 6349 is merged with Row8, Row33 now should be merged since it would match.
Basically, the workflow would need to identify any RowID that shares any single list item with any other RowID and those should be merged together and continued until no further mergers can be completed.
I have tried do this through loops but have not had success but am looking for any help/suggestions. I don’t have a workflow but have added a data table with the full set of data to be used. This would need to be dynamic as the populating of the data table can change with what the inbound data can be.
Below is a csv file with sample data that can be used for a workflow.